

AI超级周期的残酷真相:内存墙、价格飙升与中国半导体的绝地反击
2026年,全球半导体行业正站在一个历史性的十字路口。英伟达“Vera Rubin”计算平台的横空出世并全面量产,表面上是一次硬件升级,实则将彻底重塑全球存储芯片的供应链逻辑,并直接冲击到我们的钱包和每一台电子设备。未来几年,当你抱怨手机内存不足、电脑卡顿时,这背后可能正是今天我们探讨的这场“零和博弈”所带来的影响。
科技进步通常意味着产品更便宜、更高效。然而,在AI超级周期的浪潮下,我们却可能面临“花更多的钱,买更‘抠门’的产品”的反直觉现实。这场围绕英伟达Vera Rubin平台展开的芯片产业零和博弈,将颠覆我们对数字世界的认知。
内存墙的困境与Vera Rubin的破壁
随着AI智能化程度的不断提高,其对算力的需求也呈指数级增长。然而,长期以来困扰行业的是一个“内存墙”问题——CPU或GPU处理数据的速度,远超内存提供数据的速度。这就像拥有一辆法拉利,却只能在乡间小路上慢行,因为“路”太窄了。英伟达的Vera Rubin平台正是为解决这一“路窄”问题而生。
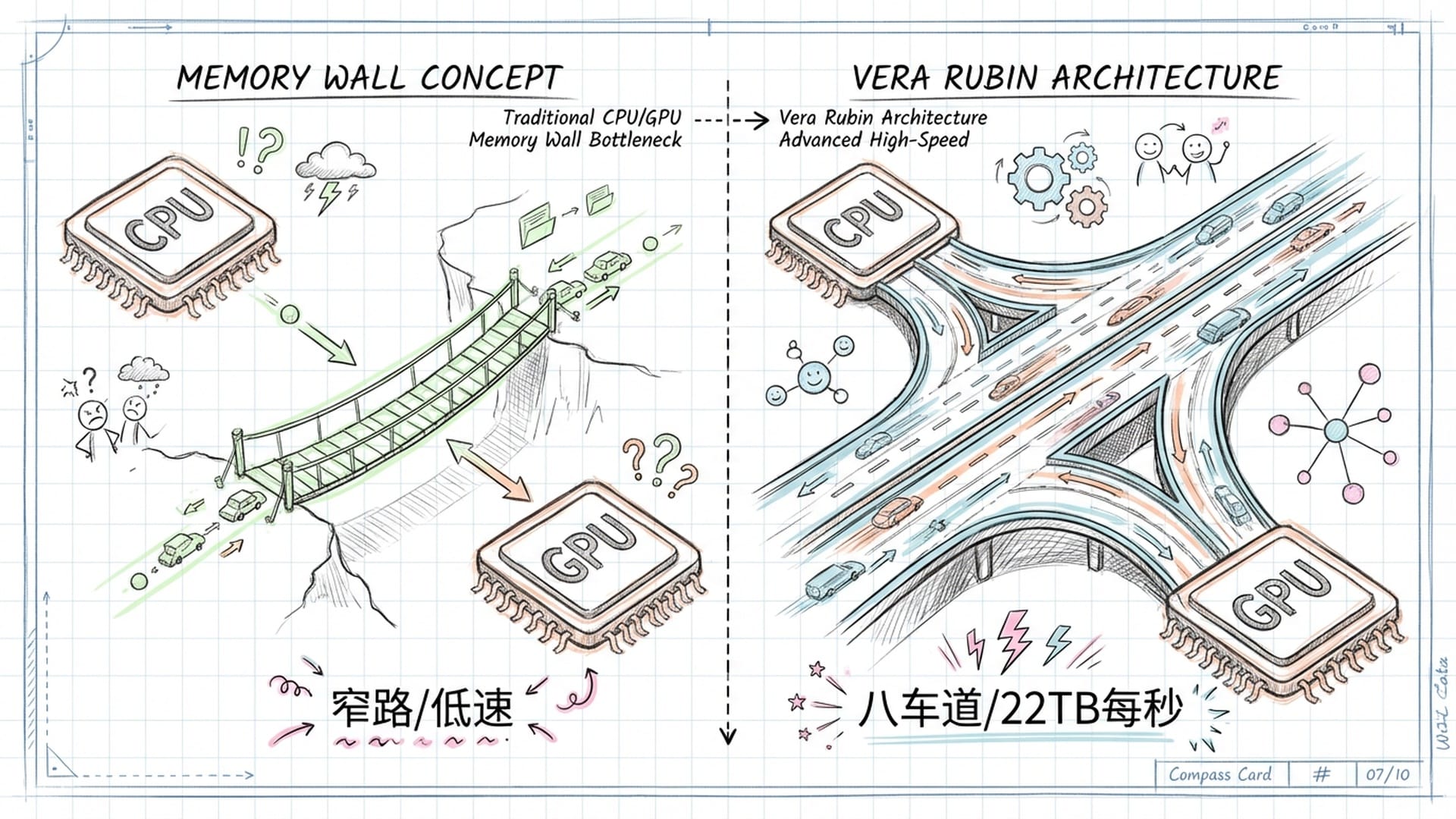
在2026年初的CES展会上,英伟达发布了Vera Rubin平台,标志着“代理型AI(Agentic AI)”时代的硬件基础设施标准正式确立。作为Blackwell架构的继任者,Rubin不仅在算力上实现飞跃,更在存储子系统设计上进行了激进革新,旨在解决万亿级参数模型训练中日益严峻的内存墙问题。
Rubin平台的核心是命名为R100的GPU,它采用台积电最先进的3纳米工艺,并引入了双芯片、光罩极限的设计架构。这种创新设计使得Rubin GPU能够容纳高达3360亿个晶体管,比前一代Blackwell的2080亿个晶体管增长了约1.6倍。然而,单纯晶体管数量的增长已不足以满足AI模型的效能需求,真正的瓶颈在于数据搬运速度,即“路不够宽,法拉利也跑不快”的问题。

为突破这一瓶颈,Rubin GPU配备了288GB的HBM4显存,这是业界首款全面采用HBM4标准的量产级AI加速器。通过8个HBM4堆叠,Rubin实现了惊人的22TB每秒显存带宽。相较于Blackwell Ultra,尽管显存容量同为288GB,但带宽效能实现了近乎3倍的提升,从约8TB每秒跃升至22TB每秒。这种带宽的爆炸性增长,对于支持FP4精度的50PFLOPS推理性能至关重要,它能让单个GPU高效运行庞大的推论与训练任务,这简直就是将乡间小路拓宽成了八车道高速公路。

系统级整合:Vera CPU与DGX Vera Rubin
Vera Rubin不仅仅是GPU的升级,它展现了英伟达在系统级整合方面的巨大野心。Rubin平台还引入了代号为“Vera”的全新CPU,这款CPU搭载了英伟达自研的Olympus Armv9.2核心,专为高吞吐量数据编排和异构计算而设计。
更有趣的是,Vera CPU在内存架构上选择全面拥抱LPDDR5X技术,而非传统服务器CPU依赖的DDR5,旨在追求极致的能效比和带宽密度。它支持高达1.2TB每秒的内存带宽,是前代产品的两倍,容量也实现了3倍增长。这一设计反映了AI负载的特性:对于长上下文推理和大数据吞吐,LPDDR5X提供了比传统DDR5更优异的能效表现。
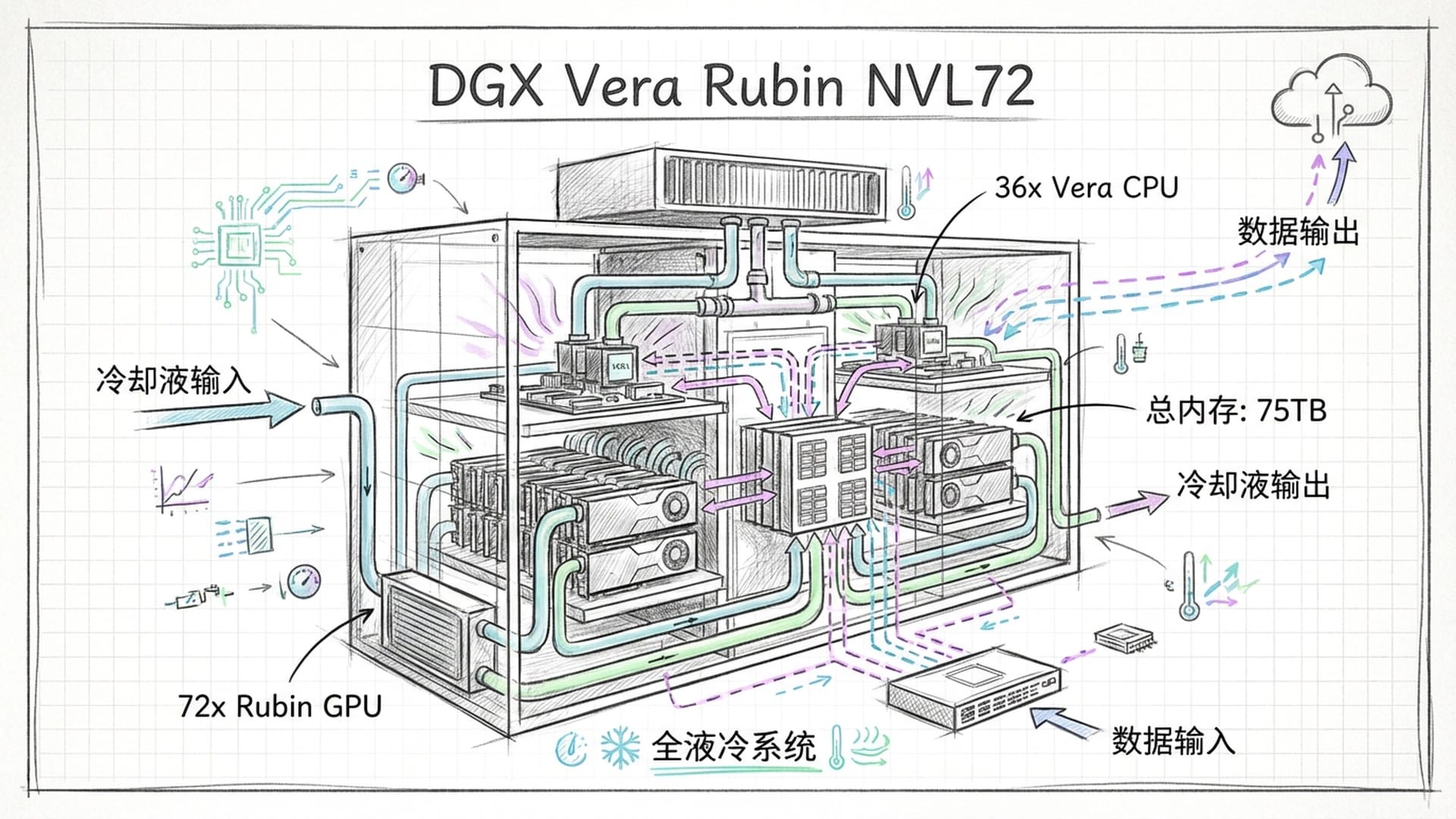
在机柜层面,英伟达推出了DGX Vera Rubin NVL72和NVL144解决方案。一个标准的NVL72机柜集成了36个Grace Vera超级芯片,即72个Rubin GPU和36个Vera CPU,它们通过第五代NVLink Switch互连。这种配置下,整个机柜拥有高达20.7TB的HBM4显存,总带宽达到1580TB每秒。此外,系统还整合了54TB的LPDDR5X内存,使得单一机柜的总内存容量接近75TB。
NVLink 6互连技术进一步强化了这种庞大内存池的可用性,提供了3.6TB每秒的双向带宽,使得机柜内的72个或144个GPU能够像一个单一巨型GPU运作,实现跨芯片的内存统一编址。这种架构彻底改变了模型训练的并行策略,允许开发者将更巨大的模型参数完整载入内存中,从而减少了跨节点通信的延迟开销。
功耗和散热已成为不可忽视的挑战。这种算力密度爆炸式增长的代价是巨大的能耗。为应对高密度计算带来的热流密度,Rubin平台全面采用了液冷技术。在NVL72机柜中,液冷系统覆盖GPU、CPU、NVLink Switch和电源供应单元,构成一整套“AI工厂”基础设施。
这种对散热和供电的极端要求,进一步推高了AI数据中心的建设门槛和总体拥有成本,使得只有超大规模的云服务商才有能力部署如此规模的算力集群。
HBM4:技术鸿沟与存储产业的重构
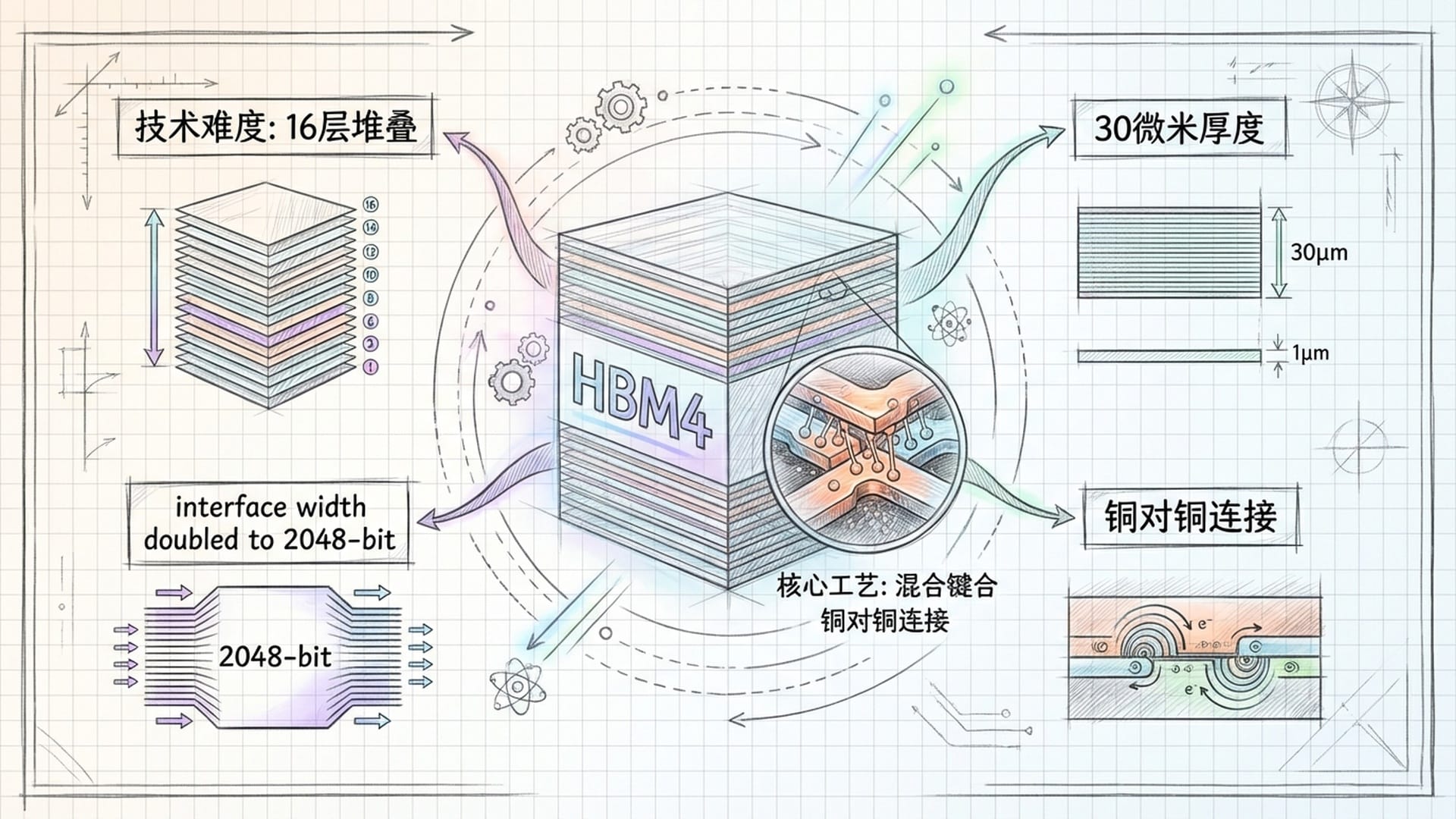
英伟达Rubin强制性需求HBM4,意味着存储产业在2026年必须跨越一个巨大的技术鸿沟。HBM4不仅仅是带宽的线性增长,它是自HBM标准诞生以来,最彻底的架构重构。
其核心变革在于接口宽度的翻倍,将传统的1024位接口扩展至2048位。这旨在降低时钟频率的同时,大幅提升总带宽,优化能效比。然而,接口宽度的增加意味着硅通孔的数量和密度必须同步倍增,这对晶圆制造的布线工艺和信号完整性提出了极高要求。
另一个关键突破是堆叠层数的增加。为满足单颗36GB到48GB的容量需求,HBM4必须实现16层堆叠。在JEDEC标准规定的775微米封装高度限制下,这意味着每一层DRAM晶圆必须被减薄到极限的30微米,大约是人类头发直径的三分之一。这种极致薄化工艺,极大地增加了晶圆加工过程中的翘曲和破裂风险,直接冲击了生产良率。
面对16层堆叠的物理挑战,传统的微凸块连接技术已接近极限。为进一步降低堆叠高度并提升散热效率,存储产业开始导入混合键合技术。这项技术移除了传统焊锡凸块,直接实现铜对铜的原子级连接,不仅解决了高度问题,还显著改善了热传导性能,这对功耗巨大的HBM4至关重要。但混合键合对洁净度和对准精度的要求极高,这正是2026年量产初期最大的产能瓶颈。
HBM4的另一重大变革是底层基础芯片的逻辑化。过去HBM的基础芯片主要负责物理层缓冲,采用较成熟的存储制程。但在HBM4世代,为实现更高带宽和更复杂控制逻辑,基础芯片转而采用台积电最顶级的12纳米甚至5纳米逻辑工艺。
这促成了存储厂和晶圆代工厂之间的深度结盟。SK海力士和台积电组成了紧密的“One-Team”联盟,共同开发针对英伟达Rubin优化的HBM4封装方案。这种跨界合作打破了传统IDM的边界,使得HBM4实际上成为一种定制化的系统级产品。
存储三巨头的市场份额争夺
在这场HBM4的存储战争中,全球三大存储原厂在2026年展开了激烈的市场份额争夺战。
- SK海力士:作为HBM市场的现任霸主,在2026年依然占据优势地位。他们凭借成熟的
MR-MUF封装技术,成功展示了业界首款16层HBM4,并锁定了英伟达Rubin平台初期大部分订单。预计到2026年,SK海力士将掌控全球HBM市场大约60%到70%的份额,特别是在高端HBM4领域,几乎是垄断性的存在。 - 三星电子:在HBM3世代稍显落后,但试图在HBM4世代通过技术跳跃实现反超。三星押注于混合键合技术和其
1c纳米DRAM工艺,试图提供更优异的能效比。此外,三星积极争取AMD的Helios平台和谷歌TPU的订单,利用其同时拥有存储和晶圆代工产能的优势,提供一站式解决方案。 - 美光科技:尽管市场份额较小,但扮演了关键的搅局者角色。其HBM4产能直到2026年底已全部售罄,显示出市场对非韩系供应链的强烈需求。美光甚至宣称其产品能效比领先竞争对手30%,使其成为电力敏感型数据中心的理想选择。

挤压效应:消费市场的危机
然而,这场存储战争的残酷真相是:它正在引发全球供应链的“挤压效应”,并可能导致一场消费市场的危机。
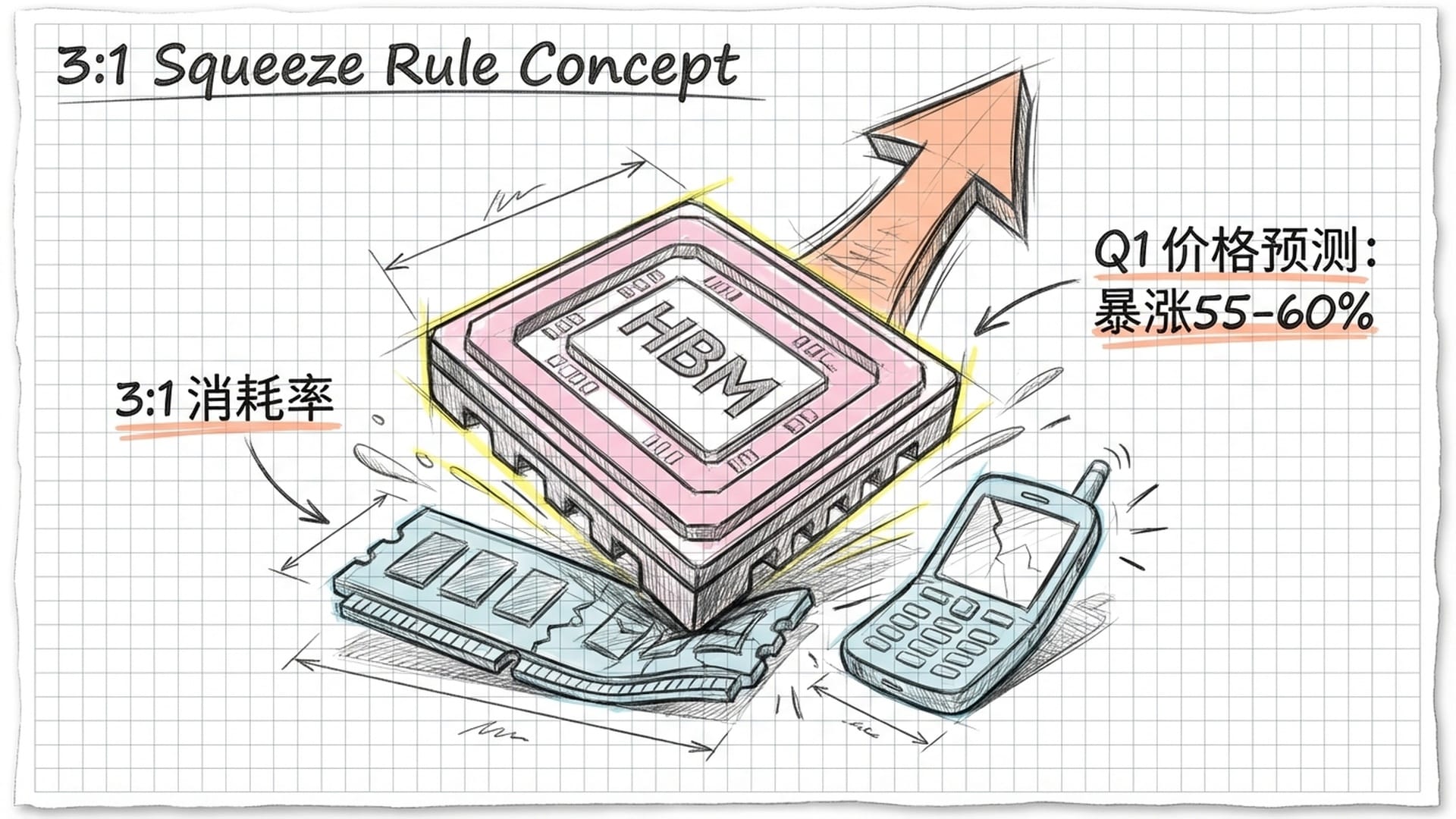
2026年存储市场的核心矛盾在于AI对产能的无限渴求与物理产能扩充的滞后性。这种矛盾集中体现在所谓的“3:1挤压法则”上。根据美光和TrendForce的产业分析,生产1GB的HBM显存,由于其巨大的晶粒尺寸、复杂的周边电路以及良率损耗,实际消耗的晶圆产能是生产1GB标准DDR5内存的3到4倍。这意味着,存储原厂每多生产一颗HBM4芯片,就必须从传统PC或手机存储市场抽走相当于三倍容量的晶圆投片量。
这种挤压效应在2026年达到高峰。由于三大原厂为追求HBM4带来的高毛利(HBM的毛利率远高于标准型DRAM),它们纷纷将最先进的制程节点优先分配给HBM产线。结果就是,2026年全球DRAM的位元供给增长率预计仅为16%,远低于AI驱动的需求增长,造成了严重的供需失衡。
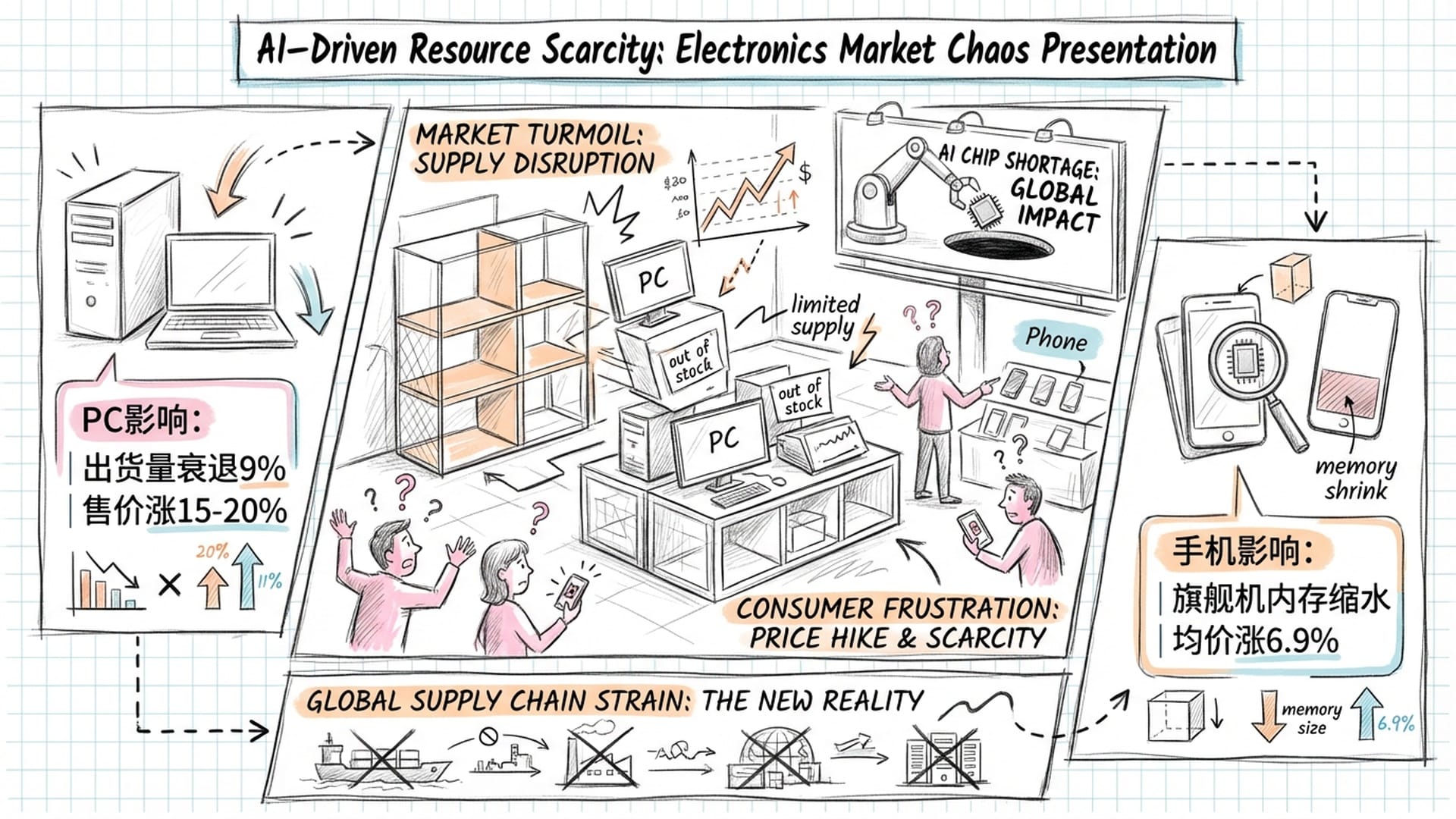
这场上游的产能争夺战,直接传导到了我们身边的PC市场。2026年,原本寄予厚望的“AI PC”换机潮,正面临存储成本暴涨的逆风。
首先是价格冲击。TrendForce预测,2026年第一季度DRAM合约价格将出现55%到60%的剧烈季增幅。对于戴尔、惠普、联想等PC厂商而言,这意味着物料成本显著上升。Dell和Lenovo等大厂已计划从2026年初开始上调产品售价,涨幅可能在15%到20%之间。
其次是配置门槛的挑战。微软为Copilot+ PC设定了16GB RAM的最低硬件门槛,这本应推动内存容量的倍增。然而,由于DDR5价格飙升,这一标准的普及正面临巨大阻力。为控制成本,部分入门级和中阶机型可能被迫停留在8GB,甚至出现“加价不加量”的市场现象。
最终结果是市场萎缩。IDC警告,受高昂的内存和固态硬盘价格影响,2026年全球PC出货量可能面临9%的衰退。DIY电脑市场受到的打击尤为严重,因为零售内存模组的价格涨幅往往高于OEM合约价。
智能手机市场同样无法幸免。DRAM和NAND Flash通常占手机物料成本的15%到18%,存储价格波动对手机定价极为敏感。
- 旗舰机规格倒退:业界原本预期2026年旗舰手机将迈向24GB RAM以支持端侧AI模型。然而,受限于
LPDDR5X产能被英伟达Vera CPU等产品挤压,这一进程可能被迫中断。分析指出,下一代旗舰机,如iPhone 17 Pro Max、Galaxy S26 Ultra,可能只会维持在12GB或16GB。 - 中低端市场降级:在价格敏感的新兴市场,为维持售价竞争力,厂商可能采取更激进的降级策略,例如将中端机型RAM从12GB降回8GB,甚至低端机型重回4GB配置。
- 平均售价上涨:为转嫁成本,主要手机品牌预计在2026年将平均售价上调约6.9%。消费者将面临一个尴尬现实:花更多的钱,却只能买到与两年前相同,甚至更低存储配置的手机。
NAND Flash市场也陷入紧缺
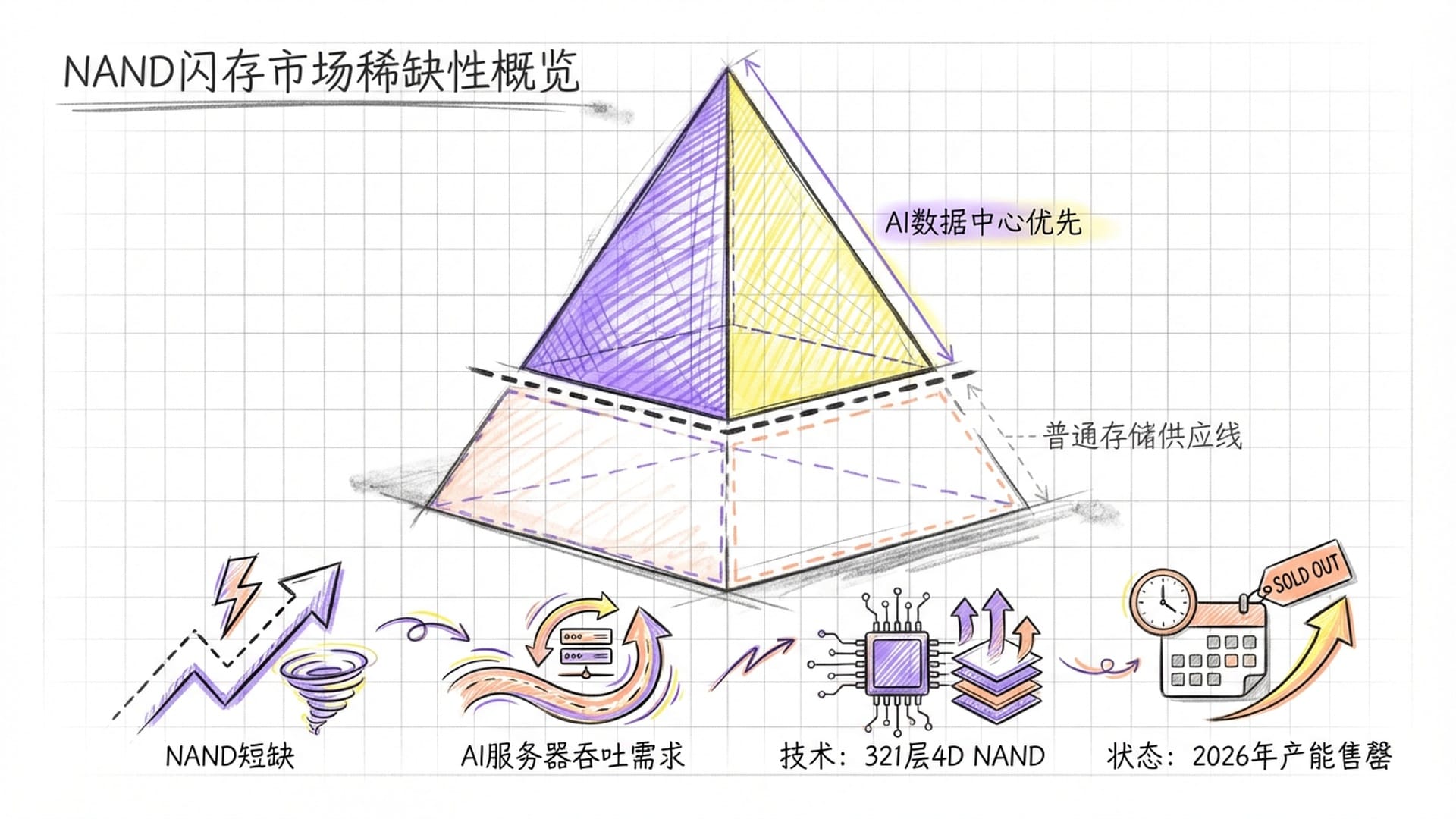
存储超级周期的影响不仅限于DRAM,NAND Flash市场也同步进入了紧缺状态。
AI服务器对NAND的巨大需求正在吸纳大量产能。AI模型训练过程中需要频繁保存检查点,这产生了对超大容量、高耐久性企业级固态硬盘的巨大需求。三星和SK海力士的QLC NAND产能被大量锁定,用于满足AI数据中心的需求。
除了NAND颗粒本身,固态硬盘控制芯片的产能也受到晶圆代工产能挤压的影响。群联电子的CEO预警,NAND价格已经翻倍,而且2026年全年的产能实际上已售罄,供应短缺预计将持续到2027年。
为应对存储密度需求,SK海力士计划在2026年上半年量产321层4D NAND,这将进一步拉开与竞争对手的技术差距,但也加剧了制造难度和设备投资需求。
中国半导体的绝地反击与红色突围
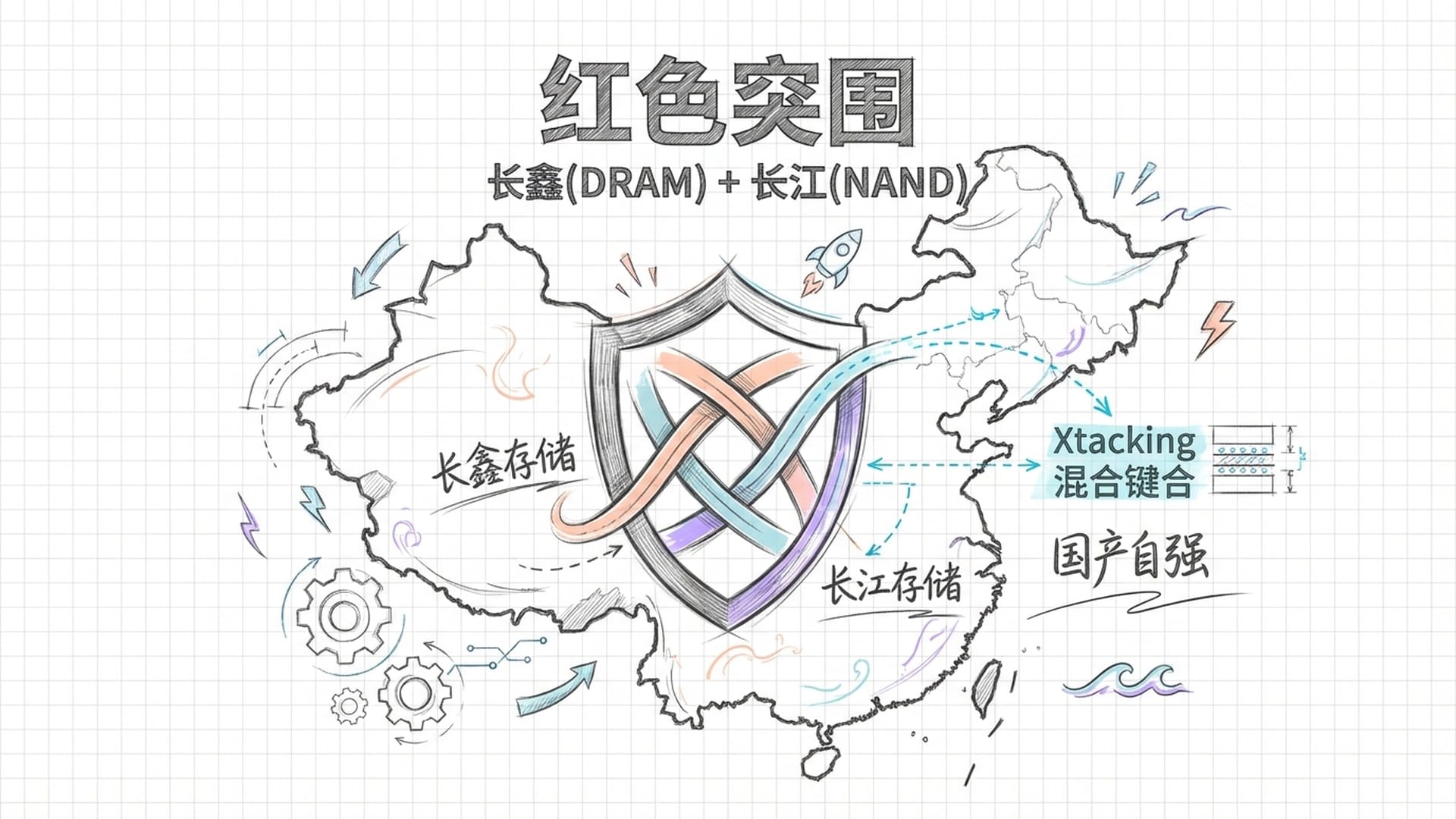
在地缘政治博弈、美国持续收紧出口管制和HBM技术壁垒的双重夹击下,中国半导体产业在2026年展现出强烈的突围意图,试图建立一条独立于“英伟达-SK海力士-台积电”体系之外的供应链。这无疑是一场封锁下的红色突围。
面对HBM制造的技术封锁,中国两大存储龙头——长鑫存储(攻DRAM)与长江存储(攻NAND)——正在进行前所未有的战略合作。长江存储在3D NAND领域自主研发的Xtacking混合键合技术,已被证实具有世界级的互连密度与良率表现。这项原本用于NAND堆叠的技术,恰好就是HBM4制造中所需的关键工艺——混合键合。通过引入长江存储的封装技术,长鑫存储试图解决HBM堆叠中的散热和互连难题。
在国产HBM进展方面,尽管在单芯片效能和良率上,中国企业仍落后国际大厂3到4年,但长鑫存储已开始向华为等国内关键客户提供HBM3样品。这些芯片虽然无法与SK海力士的HBM3E竞争,但对于被制裁的华为昇腾910系列AI芯片而言,这无疑是“从无到有”的战略生命线。
为支撑庞大的资本支出,长鑫存储计划于2026年在上海证券交易所进行IPO,目标估值和募资规模将创纪录,以支持其在HBM和DDR5产线上的激进扩张。
在先进制程受阻的同时,中国厂商在成熟制程和利基型存储市场持续攻城略地。随着边缘AI和物联网设备的普及,高容量NOR Flash的需求激增。虽然台湾厂商旺宏和华邦电在技术上领先,但面临中国厂商兆易创新的激烈价格竞争。随着AI服务器对配置存储要求提升,3D NOR Flash技术有望成为新的增长点。设备自主化也显得尤为重要。为应对设备禁运,中国正加速推动半导体设备的国产化。北方华创和中微公司等设备商在2026年预计将获得大量来自国内晶圆厂的订单,涵盖刻蚀、沉积和清洗等关键环节,尽管在光刻机领域仍依赖存量设备。
双轨制与后Rubin时代展望
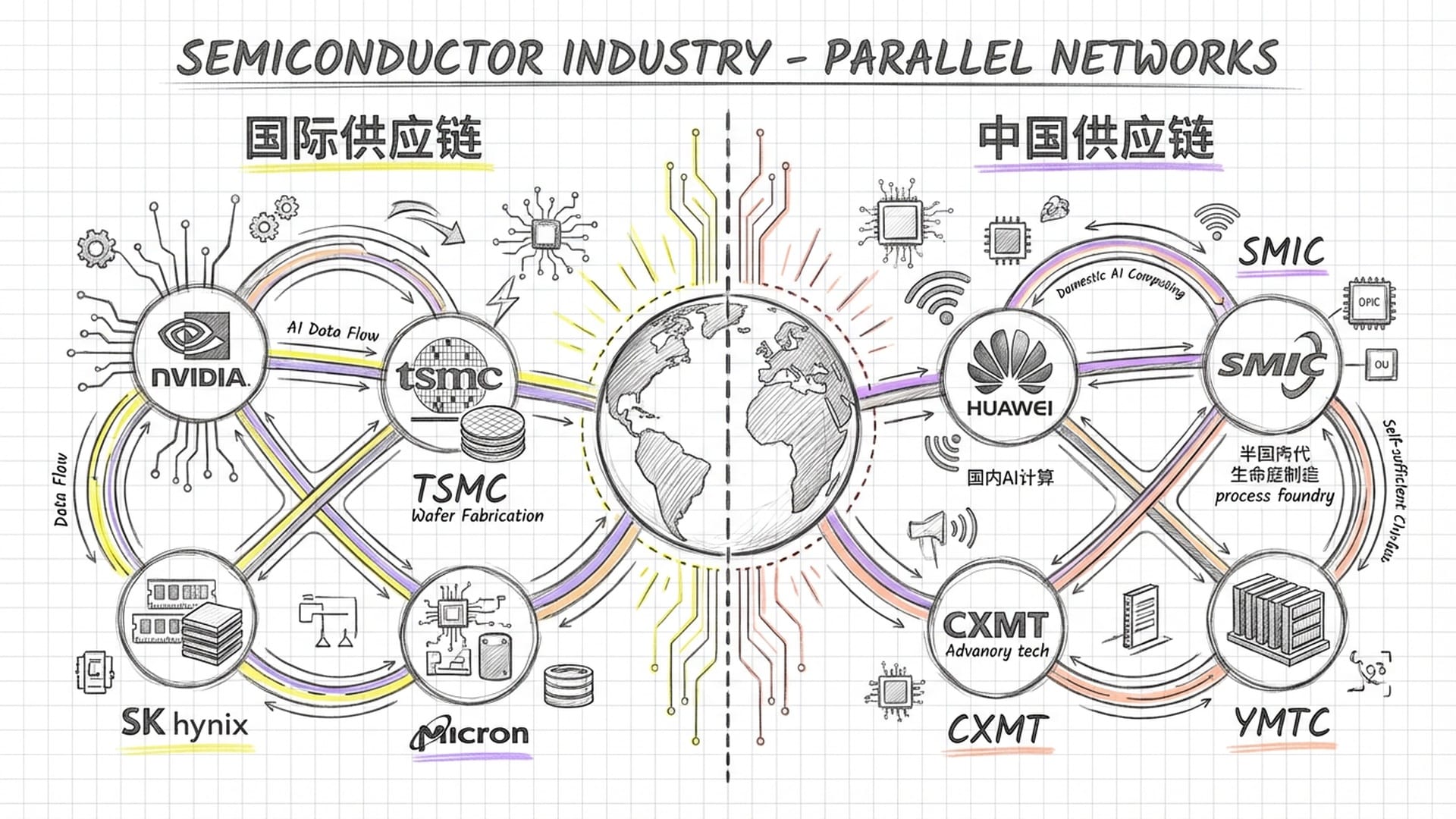
到2029年,全球存储产业将呈现明显的“双轨制”格局。
一条是国际供应链,由英伟达主导,依赖台积电、SK海力士、三星和美光的先进制程,服务于全球市场和高端AI计算。另一条是中国供应链,由华为和中国政府主导,依赖中芯国际、长鑫存储、长江存储和国内封测厂,服务于中国内需市场和部分不受制裁的发展中国家市场。这两条供应链在技术标准、软件生态和市场定价上将渐行渐远,形成各自的平行宇宙。
展望2027年到2029年的后Rubin时代,技术路径和市场周期又将如何演变?
首先,CXL将成为产业焦点。随着英伟达Rubin将HBM容量推向288GB,单靠HBM已无法满足未来万亿级参数模型对容量的渴求。HBM成本过高且容量扩展受限,使得CXL技术将在2027年后接棒成为产业焦点。CXL 3.1与内存池化技术将成为趋势,三星和SK海力士计划在2027年到2028年大规模商用基于CXL 3.1标准的内存模组。这项技术允许CPU和GPU通过PCIe接口共享PB级的外部内存池,从而大幅降低了AI推理服务器的内存成本。
未来的AI系统将形成“HBM(高速缓存)+ CXL(主内存)+ SSD(冷存储)”的三级架构,HBM提供极致带宽,CXL提供海量容量,两者互补而非替代。
同时,HBM5和3D DRAM将延续摩尔定律的生命。SK海力士的技术路线图显示,HBM5预计将于2029年到2030年问世。随着平面DRAM微缩逼近物理极限,HBM5时代可能会引入3D DRAM架构,将DRAM晶体管结构从垂直改为水平堆叠,类似于3D NAND,彻底改变存储器的密度极限。HBM5将进一步强化“定制化”趋势,存储厂商将不再只销售标准品,而是如同晶圆代工厂一样,为英伟达、谷歌等客户提供整合特定逻辑功能的定制化内存模组。
摩根士丹利等分析机构指出,这波由AI驱动的存储超级周期,其特征是“更长、更强”。预计市场供需的极端紧绷将在2027年到2028年达到顶峰。届时,随着美国CHIPS Act资助的新晶圆厂产能释放,以及AI基础设施建设增速的潜在放缓,市场可能迎来供需平衡甚至局部过剩。但即便周期回落,由于AI应用的结构性支撑,存储价格恐怕也难以回到2023年的低点。“高波动、高单价、高技术门槛”将成为2029年前存储产业的新常态。
2026年到2029年,全球存储产业将在英伟达Vera Rubin的引领下,经历一场从“通用标准品”向“AI专用基础设施”的彻底转型。这不是一次简单的产品升级,而是一场涉及资本、技术和地缘政治的立体战争。赢家将是那些掌握了HBM4先进封装和混合键合技术的厂商,如SK海力士和台积电,他们将攫取产业链中绝大部分利润。而缺乏先进产能、只能生产通用DRAM的二线厂商,以及被迫承受高昂成本的消费电子品牌,则可能沦为输家。
在这个硅晶圆的零和博弈中,2026年将是决定未来十年产业版图的关键时刻。存储器,曾经的周期性商品,如今已成为定义AI算力上限的战略石油。