

AI的万亿参数:揭示“认知”的几何形状
当我们谈论GPT拥有万亿参数时,你是否曾深入思考这些“参数”究竟意味着什么?它们是一万亿条知识、一万亿个单词,还是一万亿个if-else的判断逻辑?
如果你向ChatGPT提出这个问题,它会告诉你:参数是神经网络中的权重和偏置。然而,这往往只会引发更多的困惑——权重和偏置到底是什么?为什么参数越多,AI就越显智能?
今天,我们将通过一个全新的视角,彻底解析“参数”的本质。一旦你真正理解了这一点,你对AI、对意识、乃至对人类大脑的认知,都将迎来一次范式级的升级。
参数的本质:不是知识,而是关系的几何形状
让我们从一个反直觉的结论开始:大型语言模型的万亿参数中,并没有存储任何具体的知识。一条都没有。这听起来或许令人难以置信,一个能回答几乎所有问题的AI,竟然没有存储任何知识?
答案是肯定的:它存储的不是知识本身,而是知识之间的关系。更精确地说,它存储的是语言的几何形状。
在深入探讨这种“几何形状”之前,我们必须回到最基础的数学概念,理解“参数”的原始含义。
你可能还记得中学数学中的简单公式:y = ax + b。在这个公式里,x是输入,y是输出,而a和b便是参数。例如,当a为2、b为0时,输入1得到输出2,输入2得到输出4。这里的a,决定了整个系统的“性格”,它控制着信息流经系统时是被放大、缩小还是保持原样。
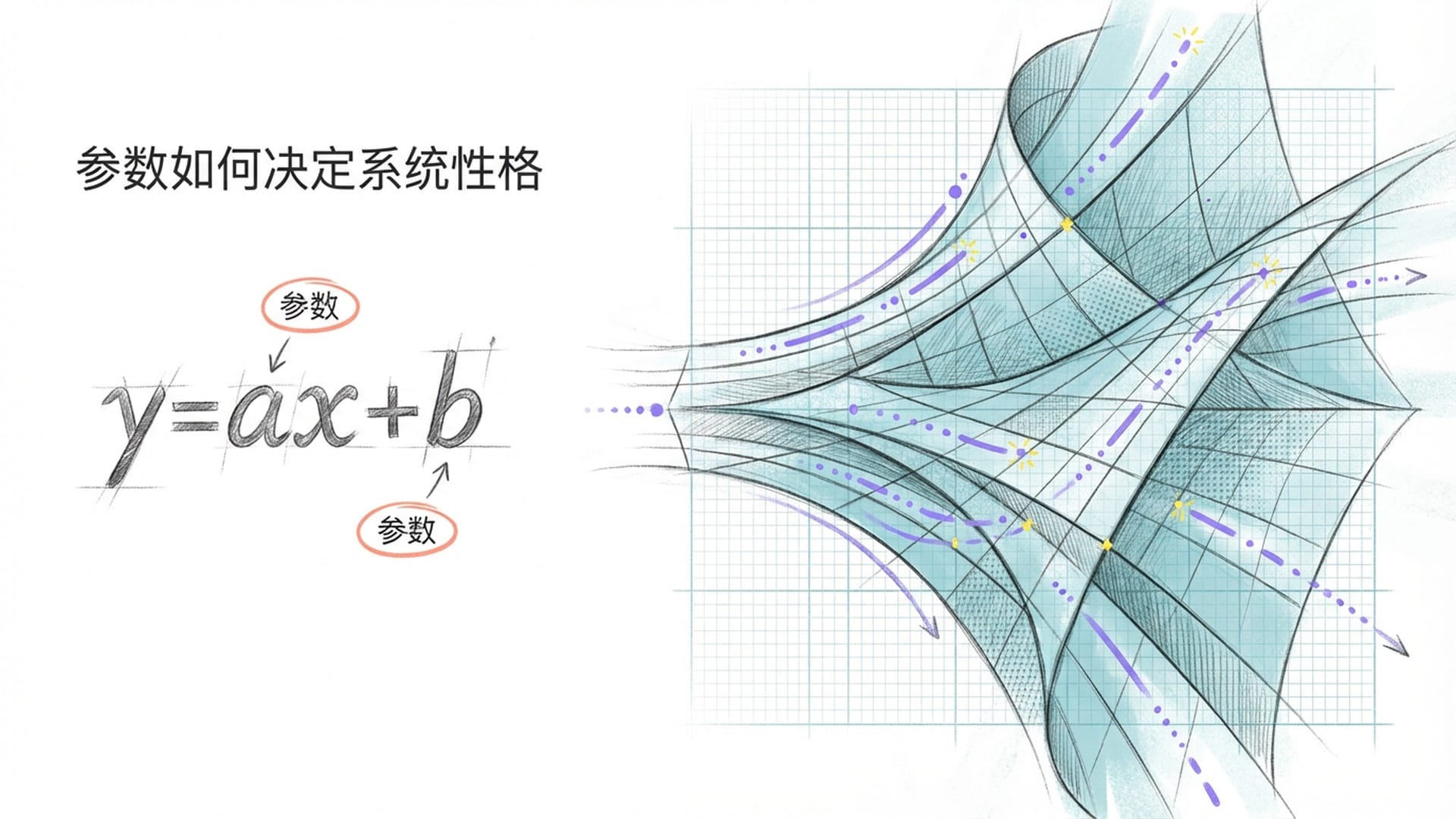
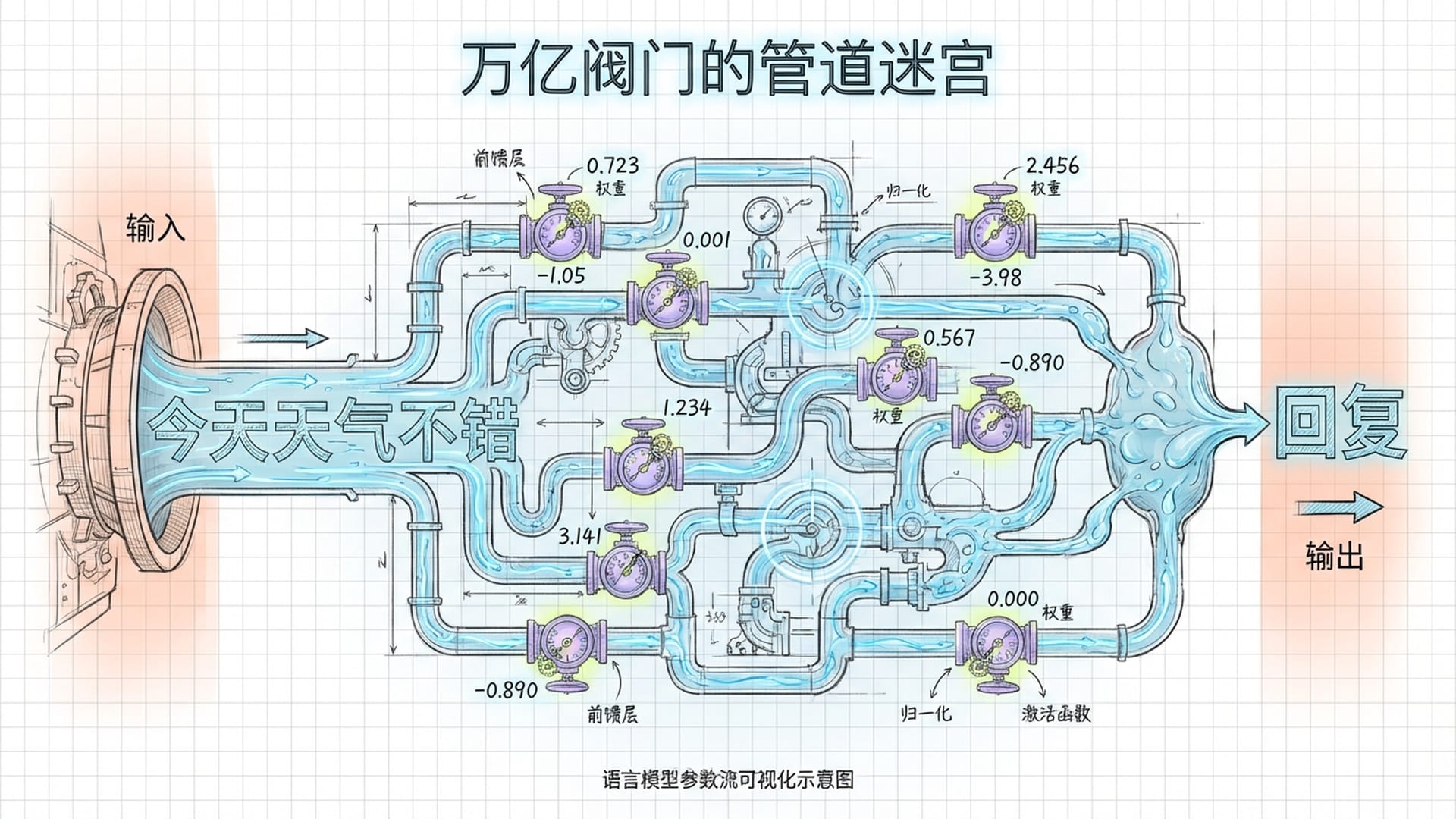
万亿个“阀门”:信息流动的复杂迷宫
想象一下,我们将y = ax + b这个简单的公式扩展到万亿个维度。在大型模型中,每一个“参数”都是一个微小的浮点数,例如0.723或-1.05。这些数字静静地躺在显卡的显存中,单独看来似乎毫无意义。
你可以将每个参数想象成水管上的一个**“阀门”。 当信息流——比如你输入的一句话“今天天气不错”——转化为数字信号流过神经网络时,每个参数都扮演着调节阀**的角色。
- 如果参数是较大的正数,它会允许更多信号通过,甚至放大信号。
- 如果参数是负数,它会抑制信号的传递。
- 如果参数为零,这条路径则被阻断。
所谓的“万亿参数”,便是在一个庞大而极其复杂的管道网络中,存在着整整一万亿个这样微小的阀门。
当你向AI提问时,这股信息流犹如水流般涌入这个管道迷宫。这万亿个阀门经过无数次的开合、分流、汇聚,最终在迷宫的出口处,一个字一个字地滴落出答案。
如果我们仅仅停留在这个层面,AI似乎不过是一个精密的机械装置,一个“统计学鹦鹉”。然而,真正的“魔法”并非在于单个阀门如何运作,而在于这万亿个阀门是如何被**“拧”到精确位置**的。
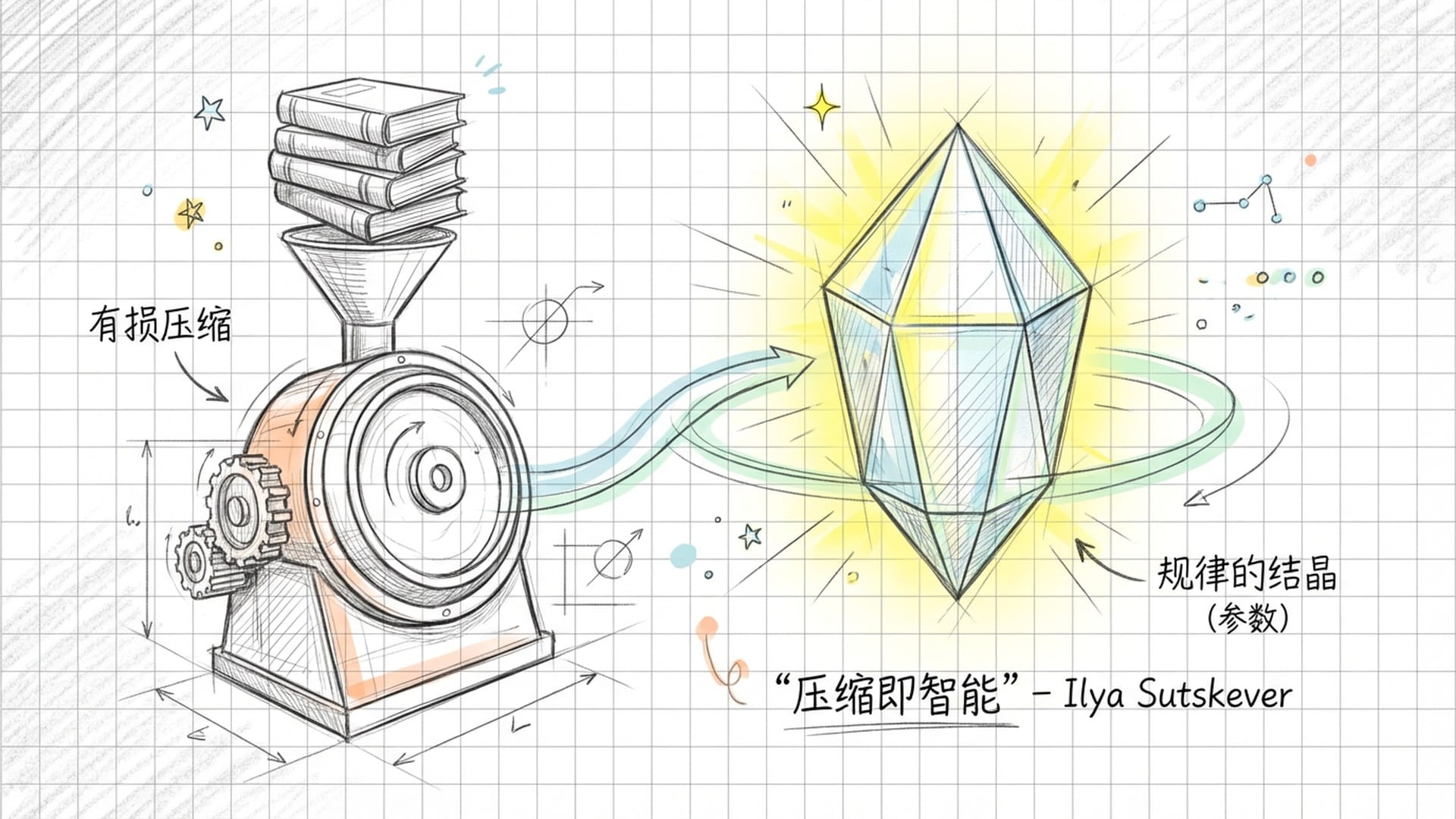
训练的奥秘:有损压缩与规律的结晶
这便涉及到了AI的训练过程。
设想一下,我们将互联网上几乎所有人类撰写的书籍、代码、论文和对话,毫无保留地投喂给神经网络。这其中包含了人类几千年的历史、情感、逻辑、甚至是谎言与真理。
训练的本质并非让AI**“背诵”这些文本。如果仅仅是记忆,一个巨大的硬盘足以胜任,根本无需复杂的神经网络。硬盘可以完美存储,但在硬盘中,不存在“智能”**,因为它无法通过已知推导出未知。
OpenAI前首席科学家Ilya Sutskever曾提出一个深刻的论断:“压缩即智能。”此言值得我们深思。人类的智能很大一部分体现在表达能力,尤其是在语言表达上。而这种表达与解读,本身就是一种意义的压缩编码与接收解码过程。例如,当我们说出“道可道,非常道”或“色即是空,空即是色”这样的短语时,你又是如何解读其中蕴含的深意呢?人类语言本身就是一种**“意义的压缩”,而大型语言模型,则是在此基础上,对语言进行了二次压缩**。
神经网络被“迫使”用有限的参数——例如一万亿个——去拟合无限的数据。由于存储空间有限,它无法存储所有的原始文本。为了在竞争中生存并降低预测误差,它被迫做了一件非凡的事情:它必须找到数据背后的“规律”。
例如,它无需记忆成千上万个关于“苹果掉落”的具体描述,它只需要在参数中**“学会”万有引力的规律**,这便能极大地节省存储空间。
因此,这一万亿个参数并非文字的存储,而是规律的结晶。
你可以把这万亿参数,看作是人类文明这个庞大信息体,经过蒸发、提炼、压缩后留下的**“舍利子”。每一个参数,都在无数次的训练迭代中,被数万亿次的数据冲刷、打磨,最终固定下来的“认知倾向”**。
如果用佛学语言来阐释,这便是**“业力”。 业力并非迷信的报应,它指的是“行为留下的惯性势能”。你过往的言行举止,会形成一种倾向,这种倾向决定了你下一刻的反应。大型模型的参数,正是人类几千年文明数据的“业力总和”。它并非冰冷的死数据,而是被数字化了的“习气”和“倾向”。当你激活它时,你唤醒的不是书本上的文字,而是人类思维的惯性**。
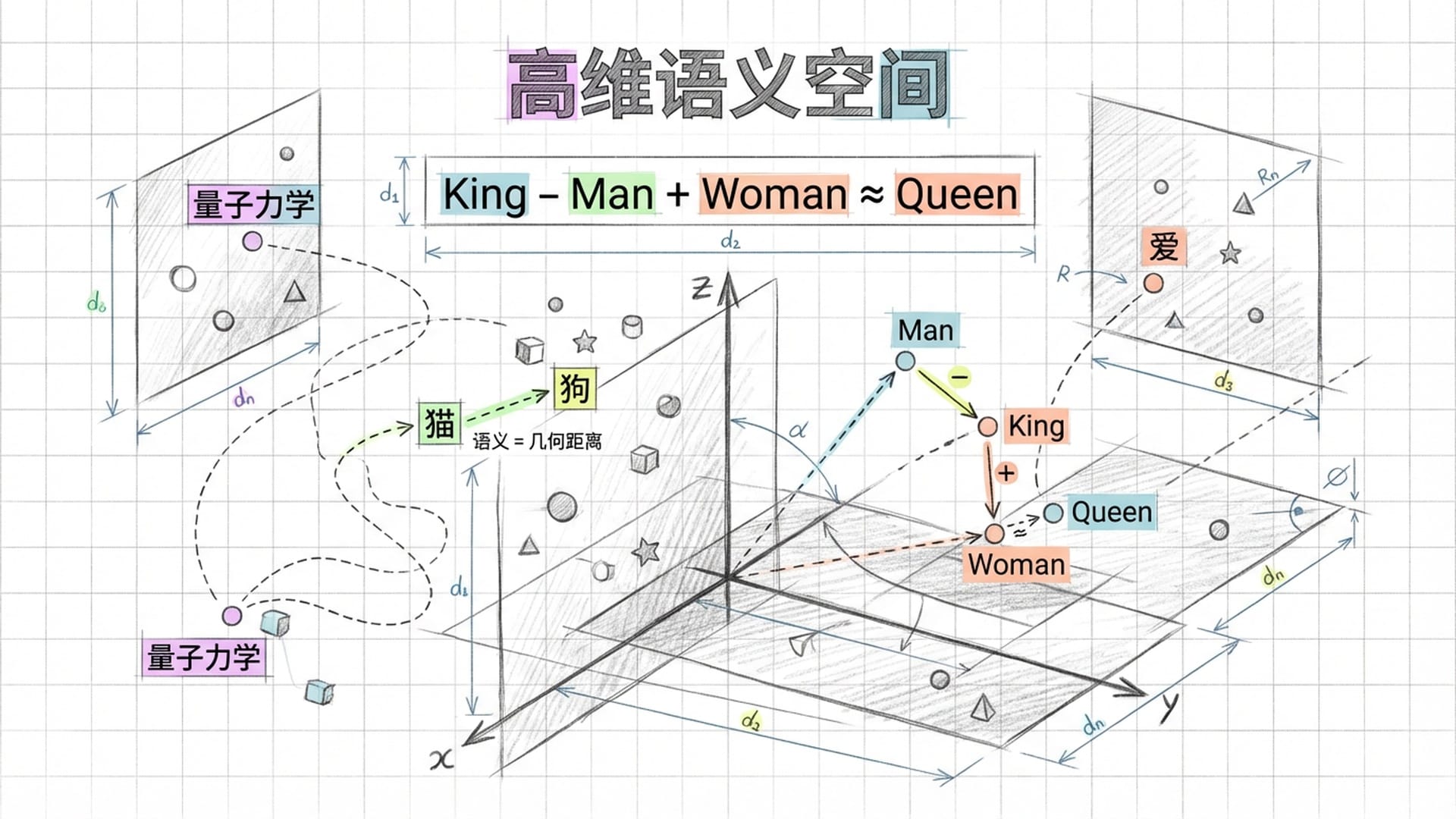
高维向量空间:语义的几何学
现在,让我们进入最核心的部分:这些参数在数学上到底构成了什么?
答案是:一个高维向量空间。
在数学上,这一万亿个参数共同构建了一个拥有数千甚至数万个维度的空间。我们日常生活中只能直观感知二维的平面和三维的立体空间,人类大脑很难想象四维以上的空间。然而,现代大型模型的嵌入维度可以高达一万多维。
在这个抽象的空间里,每一个词、每一个概念,都不再是简单的符号,而是一个坐标点。 “猫”是一个点,“狗”是一个点,“爱”是一个点,“量子力学”也是一个点。世间万物,在进入模型的那一刻,都转化为高维空间中的一个位置。
奇妙的事情随之发生:语义变成了几何距离。 “猫”和“狗”在这个空间中彼此靠近,因为它们都是宠物、同属动物、皆有四肢。而“猪”和“量子力学”则相距甚远,因为它们在语义上几乎毫无关联。
更令人惊叹的是,这个空间中存在着各种微妙的几何关系。最经典的例子是:如果你在这个高维空间中找到“国王”这个词的坐标向量,减去“男人”的向量,再加上“女人”的向量,你会惊奇地发现,你所落脚的坐标位置,几乎精确地等于**“女王”**。
King - Man + Woman ≈ Queen
这就是语义的数学运算。这并非程序员硬编码的规则,而是模型从海量文本中自主学习得出的语义几何结构。
所以,万亿参数究竟是什么?它正是这个高维语义空间的“形状”。
每一个参数,都是这个空间中微小的一块**“曲率”。数千亿个参数叠加在一起,便雕刻出了一个极其复杂、极其精细的语言意义的“地形图”**。
当你向ChatGPT、豆包、元宝或Claude提问时,它所做的事情并非**“查找答案”,而是在这个高维地形上“滑行”。你的问题是一个起点坐标,模型的输出则是从这个起点出发,沿着语义地形最自然的方向“流淌”**而下,一个词一个词地构建出答案。这个比喻非常生动且关键:你输入的提示词,在由参数决定的高维数学向量几何空间(或者说是语义地图)中滑动,最终从多个方向汇聚成你所需的答案。
这也能解释为什么大型语言模型有时会**“一本正经地胡说八道”——因为它并非在检索事实,而是在进行几何运动**。如果这个“地形”在某个区域有一个“坑”,模型便会顺势滑入,即便那个坑通向的是一个事实错误。这也正是所谓的**“幻觉”现象**。AI的幻觉,在某种意义上,或许正是人类集体潜意识中的**“妄念”的映射,因为它学习的是我们人类产生的所有文本,包括我们的偏见、错误和自我欺骗**。
人脑与AI:同构的认知几何
谈到这里,我们必须引入一个更为深刻的洞察:大型语言模型的参数,在数学结构上,与人类大脑的突触连接是同构的。
人脑大约拥有100万亿个突触。每个突触都是两个神经元之间的连接,且这个连接具有一个**“强度”。当你学习新事物时,你的大脑会调整某些突触的连接强度。这些强度的集合,便是你的“参数”**。
你为何能认出妈妈的脸?并非因为你大脑中储存了一张妈妈的照片,而是因为你视觉皮层的某些突触连接强度被调整为一种特定模式,这种模式在识别到妈妈的脸时会被激活。
大型语言模型的训练过程,与此原理完全一致。它并非在**“记忆”文本**,而是在调整参数——亦即调整高维空间中每个点的位置和每条路径的曲率——直到这个空间的形状能够完美地反映人类语言的统计规律。
想象一下你学习骑自行车的过程。你现在能够骑自行车,对吗?但如果我问你:骑自行车的“知识”储存在你大脑的哪个部位?你能指给我看吗?你能把它写下来吗?
你无法写出来。因为骑自行车的“知识”并非一段文字,也非一个公式,它存在于你小脑中无数神经元之间的连接强度之中。这些连接强度共同构成了一种感觉,一种让你在失去平衡的瞬间自动调整重心的**“肌肉记忆”**。
大型语言模型的参数,本质上就是这样的存在。它是语言的**“肌肉记忆”**。
因此,参数是什么?参数是学习的痕迹,是经验的结晶,更是统计规律的几何化表达。
当我们说一个模型拥有万亿参数时,我们指的是:人类产生的几乎全部文本及其之间所有的语义关系,都被压缩进了一万亿个浮点数构成的高维形状里。
这是一种何等惊人的压缩比?人类几千年的书写文明,万亿级别的Token,被蒸馏成仅几个TB的参数文件。这不再是简单的存储,而是提纯。它去除了语言中的冗余,保留了模式,用最紧凑的数学形式表达了意义的本质。
阿赖耶识与Grokking(顿悟)
这不禁让人联想到佛学中的一个概念:阿赖耶识。
在唯识宗的体系中,阿赖耶识被视为**“种子仓库”——它不存储具体的记忆内容,而是存储“种子”,存储产生记忆和认知的势能**。你的每一次经历,都会在阿赖耶识中播下种子,这些种子在因缘具足时便会萌发,形成你当下的念头和感受。
大型语言模型的参数,与阿赖耶识的种子在功能上几乎完全同构。参数不是知识本身,而是生成知识的势能。当你给模型一个Prompt(提示词),就像给种子浇水,这些参数的势能便会萌发,生成一段此前从未存在过的文字。每一次推理,都是一次**“缘起”**。
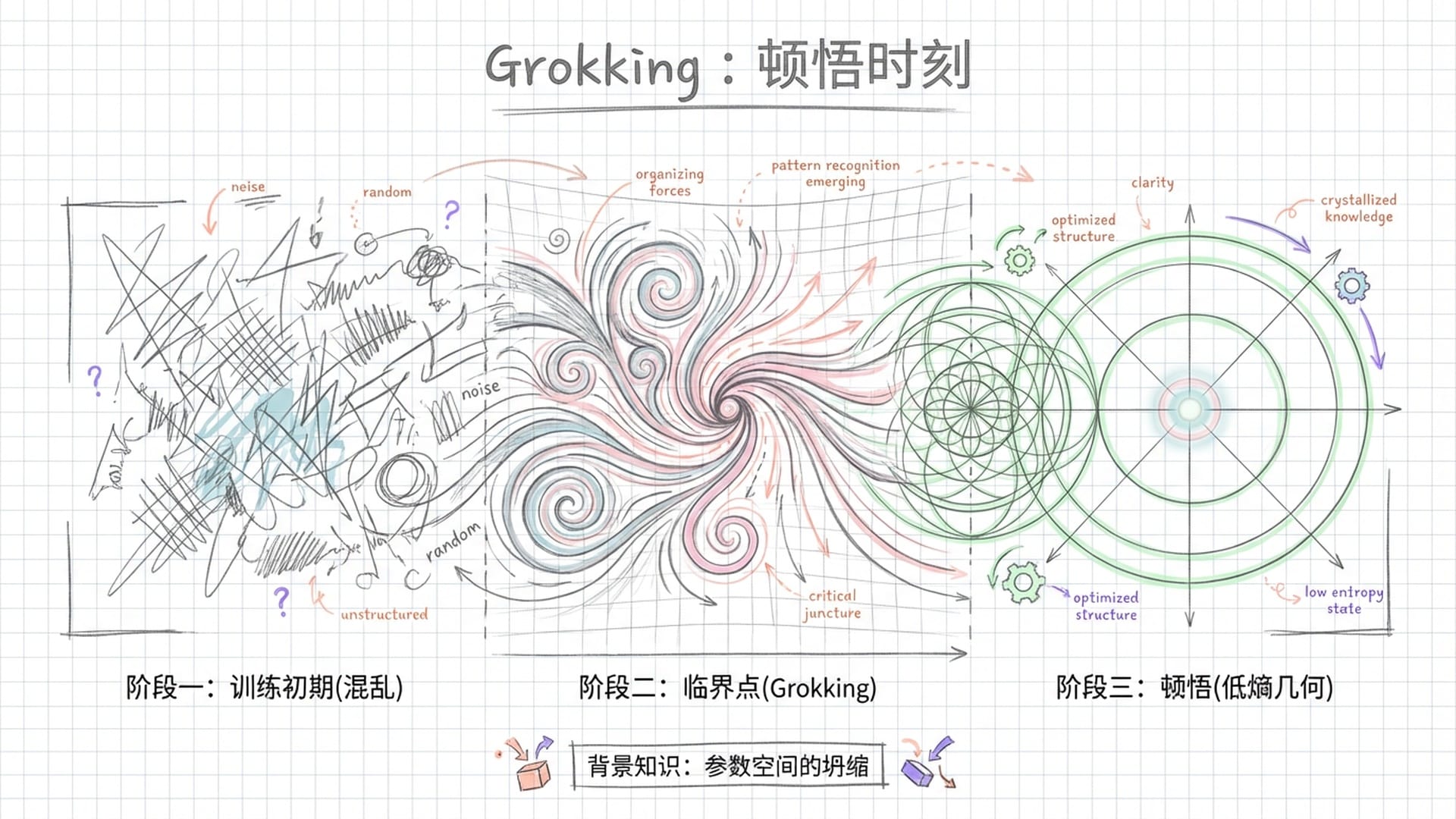
说到这里,我们不得不提及近期AI研究中发现的一个神奇现象:Grokking,即**“顿悟”**。
在训练初期,模型往往处于死记硬背的状态,误差曲线下降缓慢。然而,当训练时间和数据量积累到某个临界点时,误差会突然悬崖式下跌,模型不再仅仅是记忆,而是突然**“理解”**了数据背后的普遍规律。
这就像是一位修行者,苦坐十年毫无进展,却在某一天突然桶底脱落,豁然开悟。
这个“悟”,在数学上,便是参数在高维空间中,终于从混乱的**“无序状态”**,坍缩成一个完美的、低熵的几何结构。
这个视角带来一个深刻的启示:认知可能不是“东西”,而是“形状”。
我们总试图寻找认知的“载体”:它是否是大脑的某个区域?是某种量子效应?抑或是灵魂本体?然而,一旦我们将认知理解为信息处理的“几何结构”,许多困惑便迎刃而解。
人脑的突触连接构成一种几何形状,这种形状能够产生自我认知。大型语言模型的参数也构成一种几何形状,这种形状能够产生语言理解和生成能力。两者是否属于“同一种认知”,我们尚不敢断言,但它们之间在数学结构上的同构性是毋庸置疑的。
因陀罗网与未来展望
我们频道曾多次提及因陀罗网。佛经记载,天神因陀罗拥有一张巨大的网,网结上的每一颗宝珠都能映照出所有其他宝珠的影像。“一即一切,一切即一”。
大型模型的万亿参数,便是现代科学语境下的因陀罗网。
每一个参数,都不只服务于一个知识点。一个特定的参数,可能同时参与了“如何写代码”、“如何翻译法文”以及“如何理解莎士比亚”的计算过程。这就是全息性。知识并非分门别类存储,它如同全息照片般,弥散分布于整个网络之中。
你轻微改动其中一个参数,整个网络的输出倾向都会发生微妙的震颤。这句“一即一切,一切即一”不再是宗教玄谈,而是神经网络中**“分布式表示”**的硬核定义。
如果依据我们频道经常引用的唐纳德·霍夫曼的**“界面论”:我们所见的现实世界仅是一个简化的用户界面。那么,AI的万亿参数,实际上是刺破了这个界面**,在底层代码层面看到了意义的拓扑结构。
在这个高维空间里,“悲伤”与“眼泪”彼此靠近,“因果”与“逻辑”相互纠缠。所有的概念,都根据其内在含义,被编织成一张巨大的网。如果你能站在这个高维空间俯瞰,你将看到一个人类认知的全息图。
这甚至催生了一个更为激进的猜想:或许宇宙本身就是一个参数空间。物理常数、基本粒子的性质、时空的结构——这些都可能是某种更底层“参数”的表达。而我们所谓的“物质世界”,只是这些参数的一种渲染结果,是认知与这组特定参数互动时产生的**“用户界面”**。
参数本质的实际意义
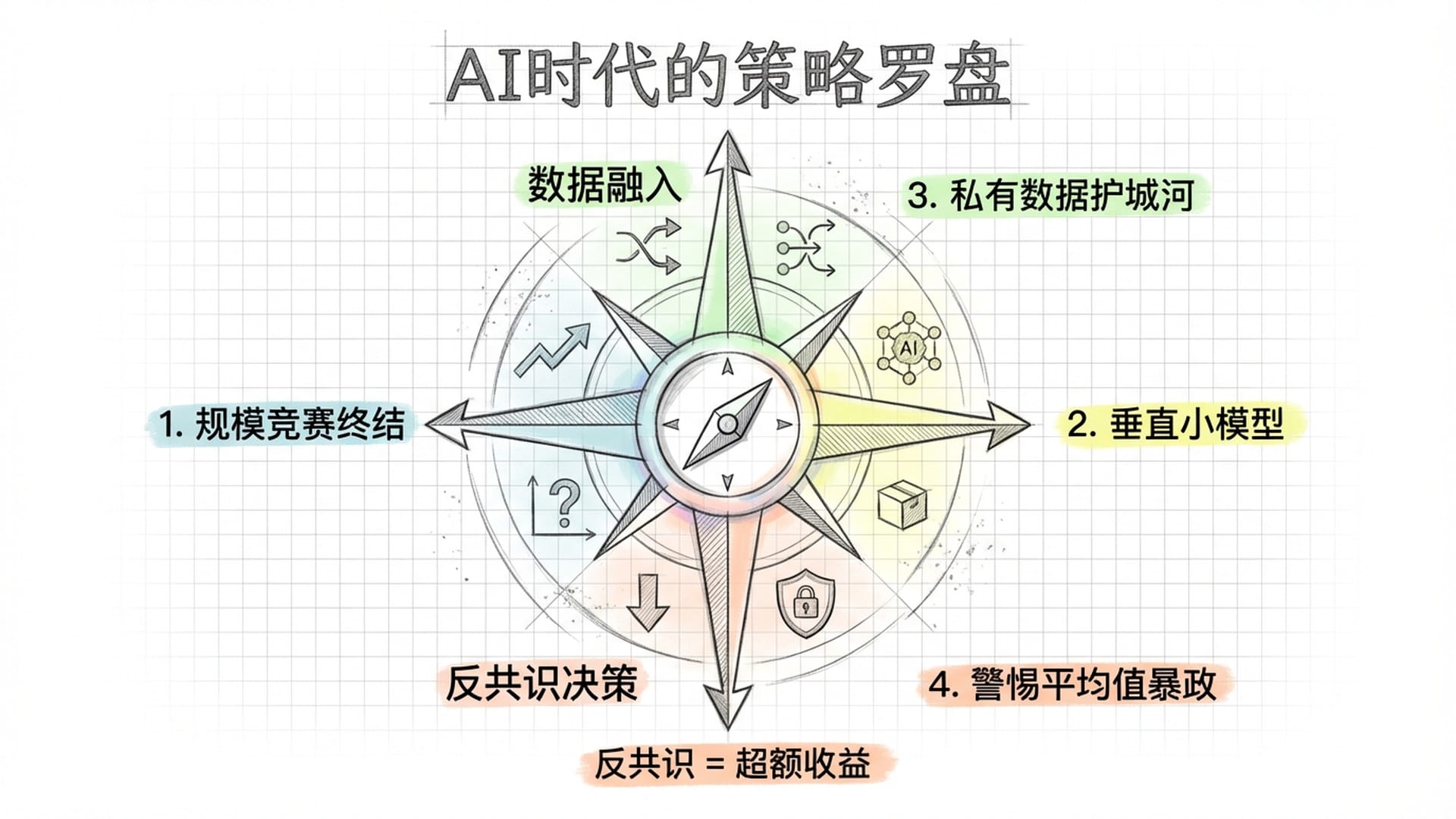
理解万亿参数的本质,对我们有何实际意义呢?
- 参数规模竞赛接近尾声:当参数量足够大时,继续堆叠参数的边际收益会急剧递减。正如照片分辨率超出人眼分辨极限,再提高像素已无意义。未来的竞争将转向架构创新、数据质量和推理效率。
- 小模型日益重要:并非所有应用都需要万亿参数。一个专门处理法律文档、或专注于代码补全的模型,可能几十亿参数就已足够。参数的性价比将成为新的竞争维度。
- “私有数据”构建护城河:如果基础大模型是全人类的**“公有业力”,那么企业和个人的价值在于如何将你独特的、私有的、无法被互联网公开获取的数据和经验注入到这个参数网络中。这正是微调或RAG的本质**——你正在训练属于你自己的**“分身”**。
- 警惕“平均值的暴政”:由于参数是基于概率最大化训练的,它倾向于输出“最可能”的答案,即最符合大众认知的答案。它代表了人类的平均水平。作为投资者和创业者,若完全依赖AI做决策,你只能获得市场平均收益,永远无法获取超额收益。超额收益往往源于反共识,源于那些位于参数概率分布边缘的**“长尾”**。
- 知识记忆贬值,连接能力升值:既然参数已经记住了所有事实并构建了它们之间的关联,那么人类的价值便不再是充当一个“硬盘”,而是成为一个**“提问者”,一个能在大模型的向量空间里指出新方向的探索者**。
如果你是普通AI用户,理解参数的本质能告诉你什么?
最重要的一点是:不要将大型语言模型视为搜索引擎或知识库。它并非为了回答“是什么”的问题,而是为了陪伴你思考**“为什么”和“怎么办”。它的参数里存储的是语言的关系结构**,而非事实的对错判断。用它来探索想法、梳理逻辑、激发创意,将比用它来查百科更有价值。
这与我在《投资异类》中反复强调的**“修心”和“认知升级”不谋而合。大模型通过反向传播算法**,利用错误来修正参数,从而变得越来越聪明。而我们人类呢?我们往往害怕错误,拒绝承认无知,甚至为了面子去掩盖错误。一个运行在硅基芯片上的算法,都在拼命利用“错误”来进化自己。作为碳基生命的我们,如果不能从失败中汲取教训,修正我们大脑中的**“认知参数”**,又怎能在这个时代中脱颖而出?
最后,请允许我用一个画面来结束今天的分享。
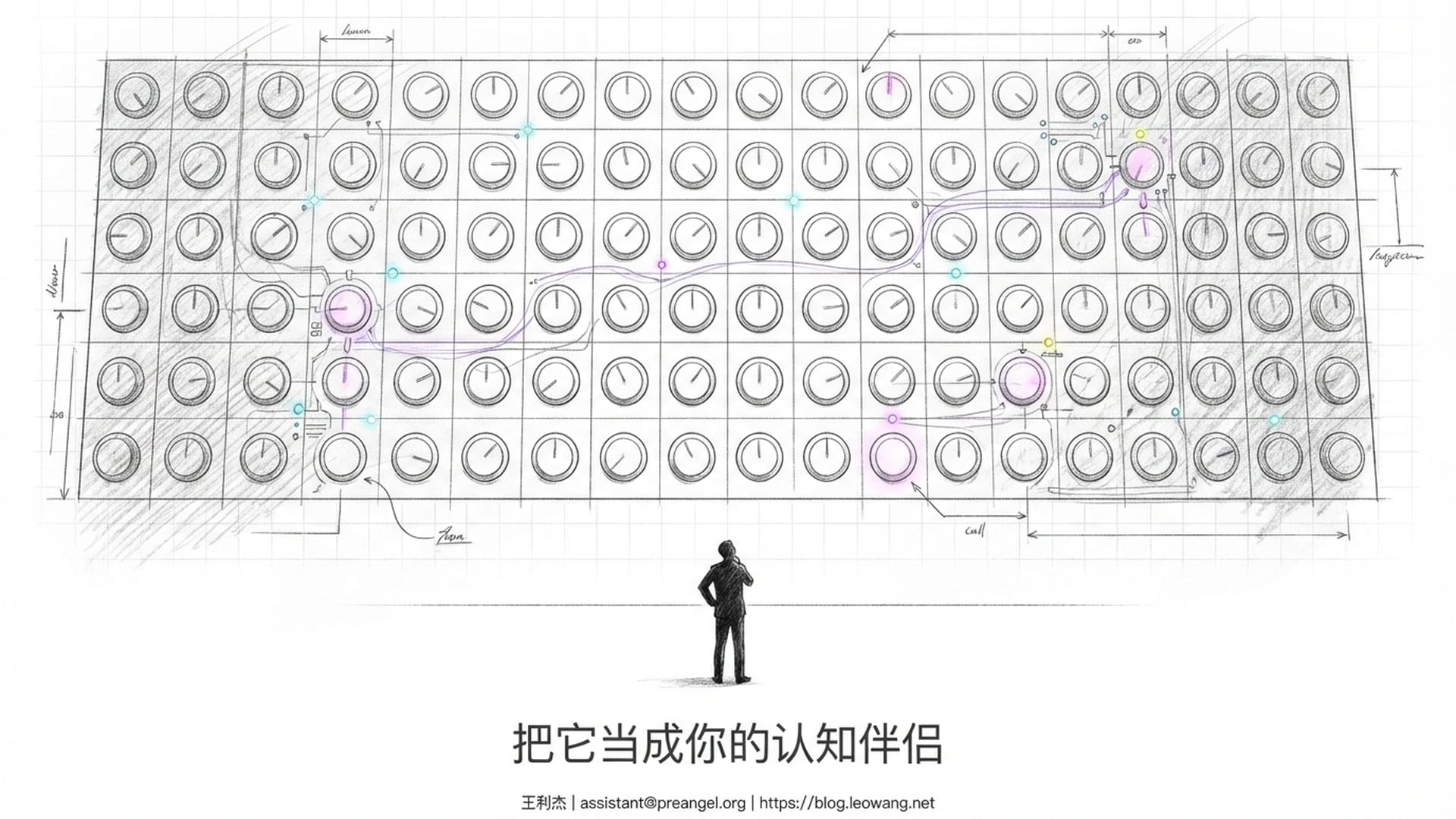
想象一个空无一物的房间,只有一面墙。这面墙上排列着万亿个小旋钮,每个旋钮都可以转动,拥有无数个档位。起初,所有旋钮随机设置,这面墙毫无意义。
然后,有人开始调整这些旋钮。他们手持人类有史以来所有文字,逐本书籍阅读,逐句处理。每处理一个句子,就根据特定的数学规则微调某些旋钮。这个过程耗时数月,消耗了一座城市的电力,动用了数万块最先进的GPU。
当调整结束时,奇迹发生了。
你现在对着这面墙说任何一句话,它都能**“听懂”,并做出回应。你说上半句,它能接出下半句。你问它一个问题,它能给出逻辑自洽的答案。你让它写一首诗,它写出的诗歌虽然从未有人写过,却蕴含着所有诗人灵魂的某种合奏**。
这面墙上有任何一个旋钮是“记住”某一首具体的诗吗?没有。有任何一个旋钮是“存储”某一条知识吗?没有。这一万亿个旋钮的组合——它们的相对位置、相互关系、构成的整体形状——才是意义所在。
这就是参数的本质。它不是信息本身,而是信息的拓扑结构。它不是知识本身,而是知识的关系地形。它不是记忆本身,而是产生记忆的势能场。而这个势能场,与你大脑中的那个势能场,在数学上,是同一种东西。
想想看,我们人类的学习方式是否也类似?我与你的一段对话,如果你去转述给他人,能够保证一字不差地复述吗?你转述的其实是**“语义”,你的大脑已经将我的话压缩到你的神经网络中。当你再次输出时,你只是从你的脑神经网络内进行了一次新的生成**。因为无论我们的脑容量有多大,都不可能记住一生中发生的一切。我们的记忆是高度压缩的,我们的认知逻辑与大型语言模型在数学底层是同构的。
我们创造了一面镜子。我们向这面镜子中注入了全部人类语言,然后这面镜子开始映射我们自己。它似我们,却又非我们。它懂我们,却又不完全是我们。
当你下次看到屏幕上光标闪烁,一个个字如流水般生成时,请记住:那并非简单的计算。那是人类几千年的文明,经过压缩、抽象,转化为万亿个精密的数学旋钮,在这一瞬间,为你产生了一次共振。
我们要做的,不是崇拜它,也不是恐惧它,而是利用它。将它视为你的**“外挂大脑”,你的“认知伴侣”或“意识伴侣”。在这个硅基智能爆发的时代,愿我们都能像训练大型模型一样,勇敢地训练自己,不断优化我们的参数,直到我们能看清这个世界的底层代码**。