
执行摘要
2025年6月10日,圣菲研究所(Santa Fe Institute)的David C. Krakauer、John W. Krakauer与Melanie Mitchell在arXiv上发布了题为《大型语言模型与涌现:复杂系统的视角》(arXiv:2506.11135)的预印本论文 1。这份文件迅速在人工智能学术界与产业界引发了剧烈震荡,因为它不仅是从技术层面对当前主流的大型语言模型(LLM)范式提出了质疑,更是从复杂性科学(Complexity Science)、热力学与信息论的基础物理层面,对支撑当前万亿美金AI产业的“缩放定律”(Scaling Laws)进行了根本性的解构。
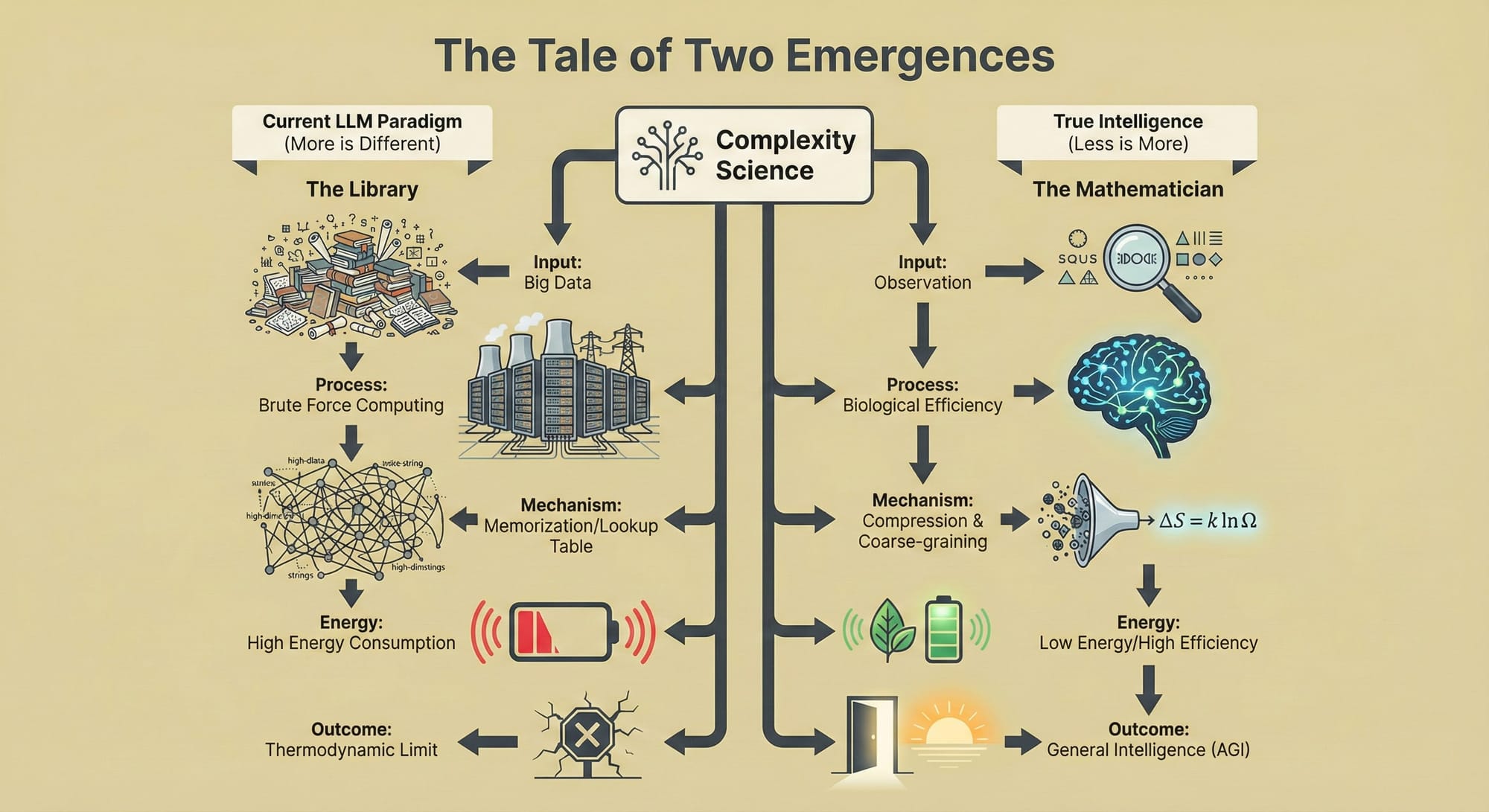
本报告旨在对该论文进行详尽的拆解与验证。分析表明,论文的核心论点在于区分“能力的涌现”(Emergent Capabilities)与“智能的涌现”(Emergent Intelligence)。作者指出,当前AI产业界普遍观察到的所谓“涌现”现象——即随着参数量增加,模型突然具备某种能力的现象——往往是度量标准选择不当造成的统计假象,或者是高维数据记忆的某种表现,而非系统内部发生了真正的相变或重组。真正的智能,应当符合“少即是多”(Less is More)的原则,即通过极度压缩的高层变量来解释复杂现象,从而实现计算与能耗的极致效率;而当前的LLM正沿着“多即是多”(More is More)的路径狂奔,试图通过穷举所有可能性的高维查找表来模拟智能,这在物理本质上是反智能的。
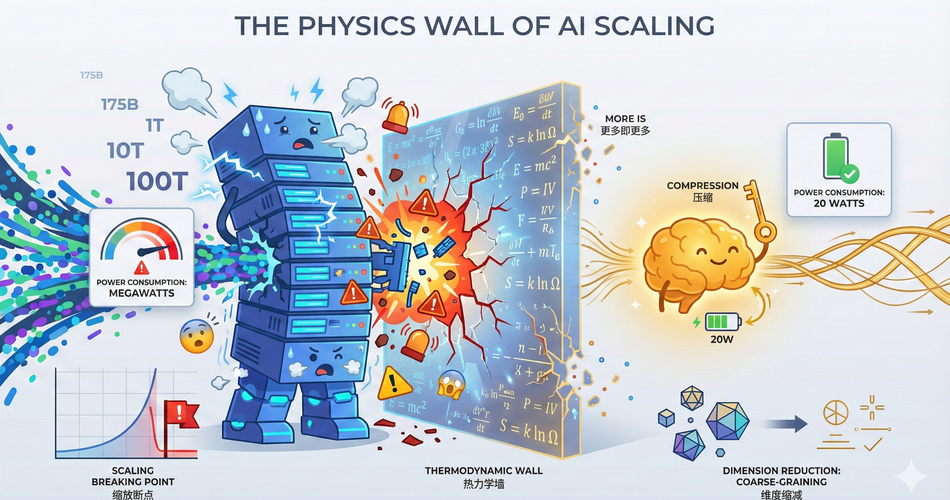
这一理论视角的转变之所以让科技巨头“彻夜难眠”,是因为它预示着当前的暴力美学路线可能正逼近一个无法逾越的热力学与经济学极限。如果智能的本质是降维与压缩,那么目前以堆砌算力为核心的军备竞赛可能是一场通往死胡同的冲刺。
1. 定义的危机:重估人工智能的“寒武纪大爆发”
1.1 前2025时代的共识:作为宿命的缩放
在深入剖析arXiv:2506.11135之前,必须回溯该论文发布前的行业语境。自Transformer架构问世以来,特别是GPT-4及其后续模型 Claude 3.5、Gemini 1.5 Pro 等展现出惊人的通用能力后,AI领域被一种近乎宗教般的信仰所笼罩,即“缩放假设”(Scaling Hypothesis)。Jason Wei等研究者在2022年的标志性论文中定义了LLM的“涌现能力”:这是那些在小模型中不存在,但随着模型规模扩大到某一临界值后突然出现、且无法通过小模型表现外推预测的能力 1。
这种定义构建了一种线性的技术乐观主义:如果模型目前不懂逻辑,那是因为它还不够大;如果它产生幻觉,那是因为数据还不够多。这种“知识输入型”(Knowledge-In)的范式假设,只要向神经网络灌输足够多的人类文本,并通过预测下一个token(Next-Token Prediction)的任务进行训练,模型就会自动习得关于世界的深层表征。在这种叙事下,智能被视为计算量的副产品,只要算力足够,全知全能的AGI(通用人工智能)指日可待。
1.2 神话的破灭:从“惊喜”回归科学
Krakauer、Krakauer与Mitchell的论文之所以具有破坏力,是因为他们拒绝接受AI社区对“涌现”一词的通俗化挪用。在AI文献中,涌现往往等同于“意料之外的能力提升”或“黑盒中的惊喜”。然而,在复杂性科学这一更为严谨的物理学分支中,涌现有着严格的数学定义。
作者指出,真正的物理涌现(如P.W. Anderson在《多即是不同》中所述)并不只是“更多”,而是伴随着对称性的破缺和系统描述层级的跃迁 1。如果在宏观层面上,我们必须通过追踪每一个微观粒子的状态来解释系统行为,那么这就不是涌现,只是复杂的模拟。
论文通过引用一系列复杂系统文献,包括Krakauer自身关于“个体信息论”的研究,提出LLM目前的表现更像是一个巨大的、高维的“随机鹦鹉”变种——它保留了训练数据的所有复杂性,而没有将其压缩为可迁移的、低维的“机制” 1。换言之,LLM可能并没有“学会”物理定律,它只是记住了所有关于物理定律的考题和答案。
1.3 巨头为何“无眠”:经济与架构的双重死锁
论文中隐晦但深刻的含义直接击中了科技巨头的软肋。如果Krakauer等人的理论成立,目前科技行业数千亿美元的基础设施投资可能面临巨大的减值风险。
这种焦虑源于三个核心维度的失效:
首先是边际效用的崩塌。当前的商业模式建立在“规模=智能”的假设之上。如果这种线性关系被证伪,意味着再投入1000亿美金建设数据中心,可能只会得到一个更渊博的“图书馆管理员”,而无法得到一个能进行因果推理的“科学家”。
其次是架构的死胡同。论文暗示,基于自回归(Autoregressive)的Transformer架构可能在根本上无法实现真正的“粗粒化”(Coarse-graining)压缩。这意味着通往AGI的道路可能需要推倒重来,探索全新的神经符号(Neuro-symbolic)或物理启发式架构,这将导致现有的技术护城河瞬间失效。
最后是能效比的审判。论文提出了“智能即效率”的观点,指出人脑以20瓦的功率实现了真正的智能,而LLM以兆瓦级的能耗仅实现了模仿。这种巨大的能效鸿沟暗示当前的AI路径在物理本质上是低效且不可持续的。
2. 解构涌现:物理学视角下的“多即是不同”
论文的核心理论贡献在于它引入了凝聚态物理和统计力学的框架来重新审视AI的进展。这一章节将深入分析作者如何利用这些硬科学概念来驳斥AI领域的软科学叙事。
2.1 Anderson的遗产与对称性破缺
论文高频引用了诺贝尔物理学奖得主P.W. Anderson 1972年的经典论文《多即是不同》(More is Different)1。Anderson的核心观点是,当物质系统的规模增大时,它不仅仅是量的积累,还会经历相变,产生全新的物理定律,这些定律无法从微观粒子的性质中直接推导出来。例如,单个水分子没有“湿”或“流动”的概念,但大量水分子聚集在一起时,流体力学的方程(如纳维-斯托克斯方程)就涌现了出来。
Krakauer等人争辩说,这种物理涌现的关键特征是降维(Dimensional Reduction)。我们不需要计算$10^{23}$个水分子的轨迹来预测水流,只需要知道压强、速度和密度这几个宏观变量。微观的自由度被宏观的有序参数所替代。
然而,在LLM中,我们并没有看到这种降维。当模型“学会”做加法时,它并没有形成一个独立的、低维的“加法模块”或逻辑规则。相反,它是在其数千亿个参数的高维空间中,通过统计相关性来模拟加法的结果。这意味着,每一次推理,模型都在调用其庞大的参数网络,没有任何“微观细节”被真正屏蔽。这种机制上的差异,判定了LLM表现出的能力并非真正的物理涌现,而是一种伪装成涌现的统计拟合。
2.2 流体力学类比:模拟与理解的界限
为了形象地阐述这一观点,报告进一步分析了论文中隐含的流体力学类比 1。
设想我们需要模拟海浪。
- 物理涌现(真实智能): 理解了波动的方程。无论海浪多大,方程形式不变。这是一种极其压缩的、高效的表征。
- 当前LLM(伪涌现): 记录了历史上每一滴水在每一个时刻的位置。当要求预测下一个波浪时,它通过检索历史上相似的水滴排列来给出答案。
虽然从外部看,两者生成的图像可能无法区分(通过图灵测试),但内部机制有着天壤之别。前者具备无限的泛化能力(可以预测从未见过的海啸),后者只能在训练数据的凸包内进行插值。一旦遇到训练数据之外的情境(Out-of-Distribution),“死记硬背”的系统就会崩溃,产生所谓的“幻觉”。
下表总结了论文中对比的两种“涌现”模型:
2.3 粗粒化与有效变量:智能的指纹
论文的技术核心在于“粗粒化”(Coarse-graining)这一概念。在统计物理中,粗粒化是将系统的精细状态映射到粗糙状态的过程,同时保留关键的因果关系 3。作者认为,智能体必须能够在其内部状态中形成这种粗粒化的表征。
例如,当人类看到一只猫时,大脑中激活的是“猫”这个概念(粗粒化变量),而不是视网膜上每一个光子的像素值。这种概念化的过程不仅节省了能量,还使得我们能够进行抽象推理(如“所有的猫都喜欢吃鱼”)。
反观LLM,论文引用了Schaeffer等人的研究(2023)指出,所谓的“涌现能力”往往是因为使用了不连续的评估指标(如Exact Match准确率)。如果改用连续的概率指标(如Negative Log-Likelihood),性能的提升就是平滑线性的。这种线性表明,模型并没有在某个临界点突然“领悟”了概念,而是在持续不断地记忆更多的模式。缺乏内部状态的重组和相变,进一步佐证了LLM缺乏真正的粗粒化机制。
3. 重定义智能:“少即是多”的经济学
如果说对“涌现”的解构是破,那么对“智能”的重定义则是立。arXiv:2506.11135最引人深思的部分在于它将智能与能力剥离,提出了一个基于热力学效率的全新智能定义。
3.1 智能作为效率的函数
论文摘要开宗明义:虽然涌现是“多即是不同”,但智能是“少即是多”(Less is More) 1。这是一个极具颠覆性的观点。在当前的AI竞赛中,所有的指标都在追求“多”:更多参数、更多数据、更长上下文。
然而,Krakauer认为,智能的本质特征是以最小的能量和信息成本解决问题的能力。生物进化是一个无情的优化过程,人脑之所以进化出智能,是因为它允许我们在极其有限的代谢预算(约20瓦)下生存和繁衍。
智能是对环境的压缩编码。一个智能体不需要记住迷宫的每一条死路,它只需要掌握走出迷宫的通用算法。相比之下,当前的LLM即使在解决简单问题时,也需要激活庞大的网络,消耗巨大的能量。这种“高带宽、低效率”的模式,在作者看来,不仅不是智能的标志,反而是智能的反面——是进化的失败品。
3.2 图书馆与数学家:两种认知的隐喻
为了阐明这一点,论文及相关讲座中使用了一个精妙的隐喻:图书馆与数学家的对比 1。
- 图书馆(LLM模型): 它是知识的容器。它拥有所有问题的答案,只要这些答案被写在某本书里。它的能力来源于存储的广度。如果你问它一个已知的问题,它能完美检索。但它没有推理能力,它只是索引。这是“多即是多”。
- 数学家(涌现智能): 他可能不知道具体的历史事实,但他掌握了公理和逻辑推演的规则。面对一个从未见过的新问题,他可以通过少量的规则推导出答案。他将无限的数学真理压缩进了有限的公理集中。这是“少即是多”。
论文指出,LLM目前正处于“图书馆”阶段。它们展现出的所谓“推理”,很大程度上是基于海量文本中推理步骤的模式匹配。它们依赖于“知识输入”(Knowledge-In),即把外部世界的知识硬编码进参数里;而真正的智能应当是“知识输出”(Knowledge-Out),即通过内部机制生成新的知识 1。
3.3 能量视角的批判:数字计算的傲慢
Geoffrey Hinton曾宣称数字计算在获取知识方面可能远优于生物计算,因为它可以无限复制和扩展 5。Krakauer和Mitchell对此提出了严厉的反驳。他们认为,这种观点忽略了计算的物理代价。
在生物界,并不存在将所有认知能力(视觉、语言、运动控制)全部混杂在一个单一网络中的生物,因为那样的能耗是致死的。生物大脑通过模块化和专门化来实现效率。而LLM试图通过一个通用的Transformer架构解决所有问题,这种“暴力美学”导致了极其低效的计算路径。论文暗示,如果不解决能效问题,AI将永远无法像生物那样在真实世界中独立存在,而只能作为依附于电网的寄生系统。
4. 针对AI涌现三大主张的系统性反驳
论文不仅停留在理论层面,还针对AI社区关于涌现的具体技术主张进行了逐一击破。作者将现有的涌现主张归纳为三类,并分别证明了其证据的薄弱性。
4.1 主张一:随规模出现的陡峭性能提升
行业观点: 随着模型从GPT-2扩展到GPT-4,诸如算术、逻辑推理等能力呈现出S型曲线的突然跃升,这是涌现的确凿证据。
论文反驳: 这一现象在很大程度上是度量标准的假象。作者引用了Koyejo和Schaeffer等人的工作,展示了如果改变评估指标(例如,不再要求完全匹配答案,而是评估部分正确的概率),这种陡峭的跃升就会变得平缓 2。此外,所谓的“突然学会”往往掩盖了模型在小规模时就已经具备的微弱相关性。这意味着并没有发生内部机制的质变,只是统计积累量变到了足以通过特定测试阈值的程度。
4.2 主张二:零样本(Zero-Shot)能力
行业观点: 模型能够执行未被训练过的任务(如将德语翻译成一种只有极少数人使用的小语种代码),这证明了泛化能力的涌现。
论文反驳: 在数万亿token的训练数据面前,“未被训练过”是一个无法证实的假设。互联网数据的污染问题极其严重。许多看似全新的任务,实际上只是训练集中某些片段的变体。只要数据量足够大,模型就可以通过一种极其复杂的“软查找表”(Soft Lookup Table)来拼凑出答案,而无需真正理解任务的逻辑结构。除非能严格证明任务与训练数据正交,否则“零样本”更多是对训练集记忆的重新组合。
4.3 主张三:内部世界模型(World Models)的形成
行业观点: 尽管只是预测下一个词,但在为了能够准确预测的过程中,模型被迫在内部构建了一个关于世界的时空模型(如Othello-GPT案例)。
论文反驳: 这是最微妙的一点。作者承认某些特定的句法结构或简单的棋盘规则可能被模型内化。然而,他们强调,基于下一个token预测的度量是“脆弱的”。如果模型真的拥有世界模型,它应该对提示词的微小扰动具有鲁棒性。但现实是,改变问题的措辞往往会导致模型输出截然不同的答案,甚至产生逻辑矛盾。这表明模型的“世界模型”是依附于语言表层的统计规律,而非深层的物理因果律。论文进一步探讨了“内部语言”(Internal Language)或“思维语言”(Language of Thought)的可能性,但得出结论认为,目前的证据不足以证明LLM发展出了独立于外部输入语言之外的内部逻辑符号系统。
5. 索玛立方体与物质性原则:具身智能的必要性
为了具体化什么是“真正的智能”,论文引入了一个极其精彩的物理案例——索玛立方体(Soma Cube),并结合了Krakauer与Kardes、Grochow等人的相关研究 8。这一部分将计算复杂性理论与认知科学完美结合,指出了LLM缺失的关键一环:具身性(Embodiment)。
5.1 索玛立方体问题:计算与物理的博弈
索玛立方体是一个由7个不规则组件拼成3x3x3正方体的智力玩具。
- 纯计算解法(LLM路径): 一个非具身的算法试图解决这个问题时,必须在脑海中搜索所有可能的旋转和排列组合。这是一个组合爆炸问题,搜索树的分支因子极大,计算成本极高。
- 物理具身解法(人类路径): 当一个人类试图解决这个问题时,他不仅仅是在用脑子想。他会拿起积木,利用重力(积木如果不平衡就会掉下来)、碰撞(固体无法穿透固体)和触觉反馈来辅助思考。
在这个过程中,物理定律本身在帮人类进行“计算”。物理约束极大地削减了搜索空间,使得一个极其复杂的组合数学问题变得连四岁小孩都能解决。
5.2 物质性原则(Principle of Materiality)
基于此,作者提出了物质性原则:智能的机制即是降低任务难度的机制。
LLM作为一种“缸中之脑”,由于缺乏身体和与物理世界的交互,它被迫完全在内部模拟一切。这使得它必须以最高昂的计算代价来解决最简单的问题(比如理解“杯子里的水倒出来会湿”)。这种与物理世界的断裂,注定了LLM只能是一种极其低效的模拟智能,而非原生智能。
5.3 智能的三重维度
Krakauer进一步将智能细分为三个维度,精准定位了LLM的短板 7:
- 策略智能(Strategic Intelligence): 关于适应和生存。例如病毒和细菌,它们没有大脑,但通过进化策略极其高效地解决了生存问题。这是极致的“少即是多”。
- 推断智能(Inferential Intelligence): 涉及形式逻辑、数学和符号计算。这是LLM擅长的领域,也是人类为了弥补自身不足而发明计算机的原因。但作者指出,
这类智能只是工具性的。 - 表征智能(Representational Intelligence): 发现更好的问题编码方式的能力。这就是索玛立方体的例子——
将一个复杂的逻辑问题转化为一个简单的物理操作问题。这是人类智能的皇冠,也是LLM完全缺失的。LLM不会“重新表征”问题,它只会用更多的算力去撞击原始问题的墙壁。
6. 产业启示:为什么巨头们彻夜难眠?
回到用户最初的疑问:为什么这篇学术论文会让科技巨头感到恐惧?答案在于,它不仅仅是理论批判,更是对当前AI商业模式的釜底抽薪。
6.1 缩放定律曲线的终结
OpenAI、Google和Microsoft的战略路线图建立在Kaplan等人2020年提出的缩放定律之上,即性能与算力呈幂律关系。然而,arXiv:2506.11135暗示,这条曲线描述的可能只是记忆容量的增长,而非智能的增长。
随着模型规模的扩大,对于需要真正逻辑推理和因果理解的任务,错误率的下降可能会遭遇“数据墙”。这意味着,即便巨头们投入1000亿美元建设Stargate级别的超算集群,如果不改变架构原理,他们得到的可能只是一个能够更流畅地产生幻觉的聊天机器人。资本投入与智能产出的脱钩,是商业公司最大的噩梦。
6.2 数据枯竭与“垃圾进,垃圾出”
论文区分了“Knowledge-In”(数据注入)和“Knowledge-Out”(知识生成)。目前的LLM完全依赖于前者。随着高质量人类文本(互联网存量数据)被耗尽,模型面临无米之炊。
更可怕的是,如果目前的模型不能产生“Knowledge-Out”的涌现机制,它们就无法像AlphaGo那样通过自我对弈来进化。AlphaGo之所以能成功,是因为围棋是一个封闭的形式系统,规则明确。而真实世界是一个开放系统,LLM缺乏一个能够判断真伪的“内部世界模型”作为裁判。这导致在合成数据上训练LLM可能会引发“模型崩溃”(Model Collapse),即智能退化。
6.3 专用架构对通用模型的威胁
“少即是多”的原则暗示,未来的AI可能不属于参数无限大的通用模型,而属于小巧、高效、针对特定领域优化了“有效变量”的专用系统(Specialized Systems)。
如果神经符号AI、物理启发AI或类脑计算被证明是通往真正智能的路径,那么目前科技巨头建立的基于庞大算力和通用模型的壁垒将变得毫无价值。这将导致市场格局的瞬间重组,就像恐龙被小型哺乳动物取代一样。
7. 批判性验证与潜在争议
作为一份客观的研判报告,必须指出该论文可能存在的局限性与反驳视角。
7.1 论点的坚实之处
- 物理学根基: 将重整化群理论和相变概念引入AI分析,为这一领域带来了急需的严谨性,从根本上区分了“复杂性”与“混乱” 1。
- 解释了幻觉的本质: 论文完美解释了为什么LLM会产生幻觉——因为它们是在高维空间中进行插值,缺乏一个低维的、连贯的真理机制(World Model)来约束生成内容。
- 历史一致性: 科学史本身就是一个追求“少即是多”的过程(如牛顿定律将天体运动压缩为三个公式)。认为智能应当遵循同样的极简原则是符合科学直觉的 1。
7.2 潜在的盲点与反驳
- “异类智能”(Alien Intelligence)的可能性: 论文的一个潜在假设是智能必须像人类一样通过“降维”和“可理解的变量”来运作。然而,
是否存在一种基于高维纠缠的“异类智能”,它确实有效,但对人类来说是不可理解的黑盒?我们不能完全排除LLM正在进化出一种全新的、基于纯统计的智能形式 5。 - 对近期进展的低估: 论文在截稿时可能未完全覆盖最新的研究(如Q*、推理链思维CoT的最新进展),这些技术似乎在一定程度上引入了搜索和规划机制,弥补了纯预测的不足。
- 定义的规范性:
将智能定义为“效率”是一种哲学选择。如果在无限能源的前提下,一个极其低效但全知全能的机器是否也可以被称为“智能”?这取决于我们定义智能是看结果(Effectiveness)还是看过程(Efficiency)。
7.3 综合判断
尽管存在上述争议,但arXiv:2506.11135的核心论点——单纯的规模堆砌无法自动产生具备因果推理和物理常识的智能——在逻辑上是自洽且强有力的。它为当前过热的AI投资提供了一个必要的冷静剂。
8. 结论:后涌现时代的黎明
David C. Krakauer、John W. Krakauer与Melanie Mitchell的论文《大型语言模型与涌现:复杂系统的视角》标志着AI发展史上一个重要阶段的结束。它宣告了“魔法时代”的终结,取而代之的是对复杂系统物理规律的严肃审视。
本报告总结出三大核心结论:
- “多”不是万能药: 仅仅通过增加参数(More is Different)可以创造复杂性,但无法自动创造出智能所需的有序机制。目前的LLM更像是博尔赫斯笔下的“巴别图书馆”,而非创造这些书籍的作者。
- “少”才是进化方向: 真正的智能是压缩、是遗忘、是简化。未来的AI架构必须从“记忆所有数据”转向“发现数据背后的生成法则”。这要求研究重心从工程规模化转向基础理论的突破。
- 巨头的梦魇是真实的: 科技巨头面临的风险不仅是技术上的,更是战略上的。如果他们的万亿基建是为了一种注定无法通往AGI的架构(Transformer)服务的,那么我们正处于一场巨大的科技泡沫之中。
这篇论文不仅仅是一份学术报告,它是一份判决书。它判决了暴力美学的死刑,并为下一代AI——那些更具身、更高效、更符合物理法则的智能形式——指明了方向。对于产业界而言,现在是时候从“越大越好”的迷梦中醒来,开始思考“如何用更少做到更多”了。
参考文献
本报告综合引用了以下来源的观点与数据,已在文中相应位置标注:1。
Works cited
- Large Language Models and Emergence: A Complex Systems Perspective - arXiv, accessed November 20, 2025, https://arxiv.org/pdf/2506.11135
- Overview of Emergent Abilities in AI - World Scholars Review, accessed November 20, 2025, https://www.worldscholarsreview.org/article/overview-of-emergent-abilities-in-ai
- Large Language Models and Emergence - NEW SAVANNA, accessed November 20, 2025, https://new-savanna.blogspot.com/2025/06/large-language-models-and-emergence.html
- Machine Learning Street Talk (MLST) - Apple Podcasts, accessed November 20, 2025, https://podcasts.apple.com/dm/podcast/machine-learning-street-talk-mlst/id1510472996
- arxiv.org, accessed November 20, 2025, https://arxiv.org/html/2506.11135v1
- accessed November 20, 2025, https://arxiv.org/html/2506.11135v1#:~:text=Intelligence%20is%20a%20consummate%20emergent,idea%20%E2%80%9Cless%20is%20more%E2%80%9D.
- We Built Calculators Because We're STUPID! [Prof. David Krakauer] - YouTube, accessed November 20, 2025, https://www.youtube.com/watch?v=dY46YsGWMIc
- (PDF) Physical Complexity of a Cognitive Artifact - ResearchGate, accessed November 20, 2025, https://www.researchgate.net/publication/395542394_Physical_Complexity_of_a_Cognitive_Artifact
- [2509.12495] Physical Complexity of a Cognitive Artifact - arXiv, accessed November 20, 2025, https://arxiv.org/abs/2509.12495
- A personal take: LLMs are stuck, but local might win? : r/LocalLLaMA - Reddit, accessed November 20, 2025, https://www.reddit.com/r/LocalLLaMA/comments/1mm1mcj/a_personal_take_llms_are_stuck_but_local_might_win/
- [PDF] Large Language Models and Emergence: A Complex Systems Perspective, accessed November 20, 2025, https://www.semanticscholar.org/paper/Large-Language-Models-and-Emergence%3A-A-Complex-Krakauer-Krakauer/2171bd0b91f7b827c621be068015927e9391be7c
- Large Language Models and Emergence: A Complex Systems Perspective - ResearchGate, accessed November 20, 2025, https://www.researchgate.net/publication/392716570_Large_Language_Models_and_Emergence_A_Complex_Systems_Perspective
- [2506.11135] Large Language Models and Emergence: A Complex Systems Perspective, accessed November 20, 2025, https://arxiv.org/abs/2506.11135
- Bayesian Models of Cognition - ResearchGate, accessed November 20, 2025, https://www.researchgate.net/publication/370681626_Bayesian_Models_of_Cognition