

我们正迎来一场史无前例的计算变革,这好比站在计算海啸的浪尖。在过去几年里,大模型训练以其万亿参数的浮点运算能力(FLOPS)主导着AI世界。然而,一个新时代正迅速崛起,旧的衡量标准正在被颠覆。
从训练到推理:AI范式的根本性转变
如果说AI训练是构建一个超级大脑,那么推理就是让这个大脑去思考、感知和创造。从2024年到2027年,AI世界的重心正在发生一个根本性的结构性转变。我们将告别以昂贵资本支出为主的大模型训练周期,一头扎进以大规模推理部署为主的运营支出阶段。
这种转变不仅仅是技术上的,更是商业模式和战略重点的调整。企业需要重新审视其AI基础设施投资,将目光从单纯追求算力高峰转向成本效益、实时响应和规模化部署。
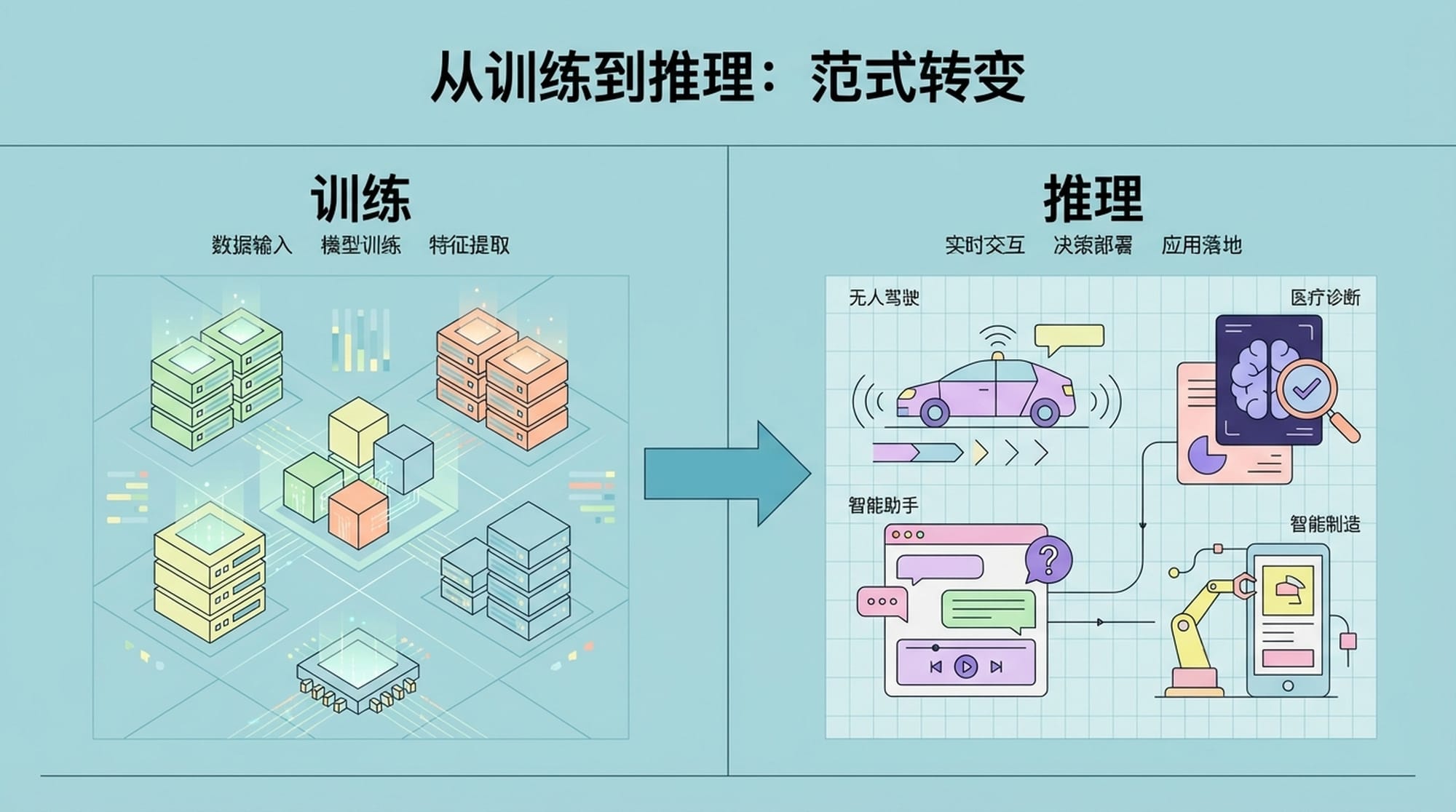
推理需求的爆炸式增长
预计到2026年,全球超过 70% 的通用AI计算需求将来自推理任务,其需求量更是训练需求的 4.5倍!这是一个惊人的数字,意味着我们不能再仅仅关注浮点运算能力。
- 新的衡量圣杯包括:
- 每瓦特性能 (Perf/Watt):能源效率至关重要。
- 每美元吞吐量 (Tokens/$):成本效益是规模化的核心。
- 延迟敏感度 (Latency):实时交互对速度有着严格要求。
在推理世界中,速度就是一切,而成本则是生命线。试想一下,如果一个AI助手在实时对话中需要数秒的延迟,用户体验将大打折扣。推理任务的多样性,从需要极低延迟的实时交互到需要极高吞吐量的后台批处理,彻底打破了“一款GPU通吃天下”的神话。
两股巨大力量的碰撞:NVIDIA的进化与云巨头的反击
在这场前所未有的AI推理大分化中,两大阵营正在激烈碰撞:
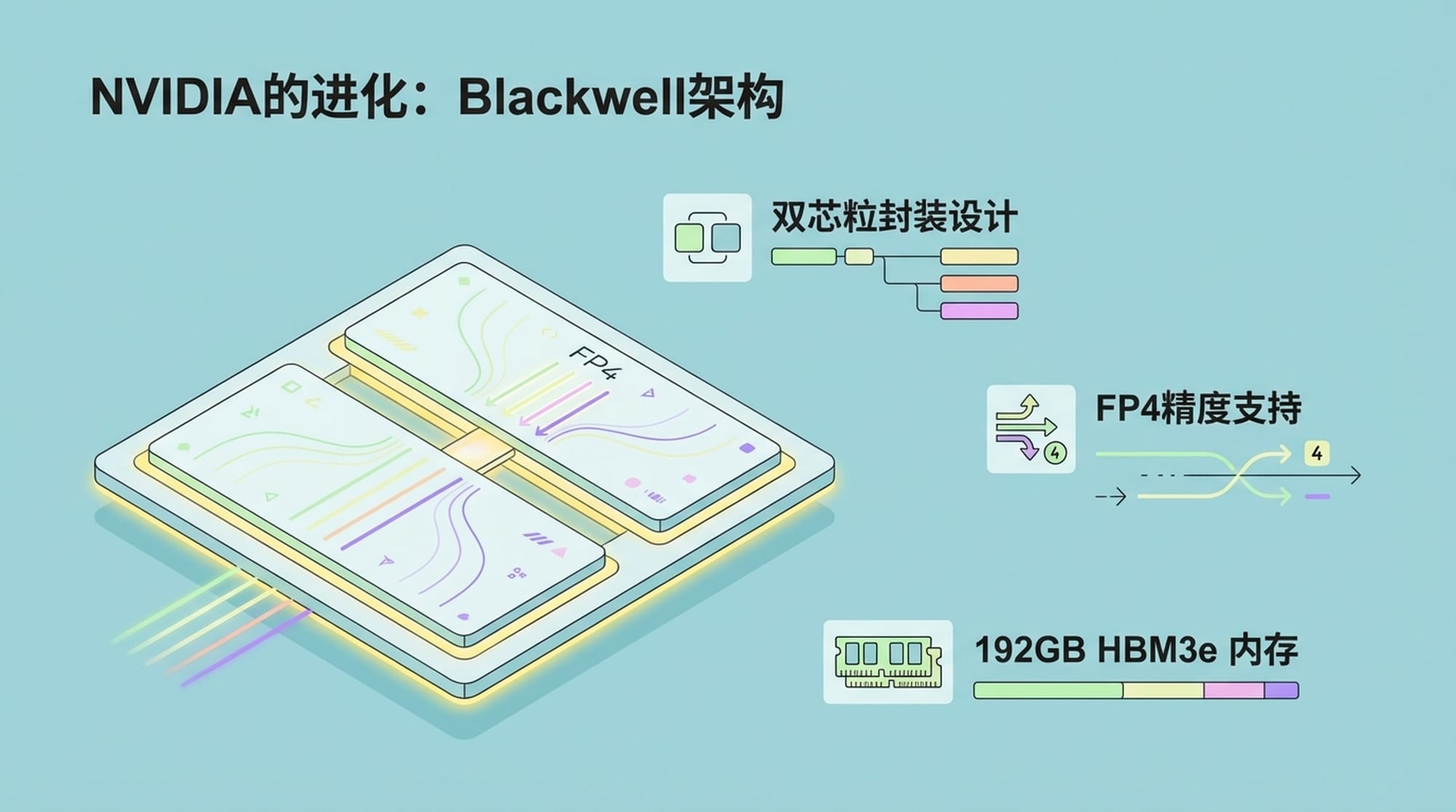
1. NVIDIA的持续进化:Blackwell架构的革新
作为AI计算领域的绝对霸主,英伟达深知推理市场的重要性。其从Hopper到Blackwell架构的迭代速度令人惊叹。Blackwell不仅仅是制程工艺的提升,更是对推理市场痛点的精准打击。
- Blackwell的核心创新:
- 双芯粒设计:单颗B200芯片拥有2080亿个晶体管,大幅提升了单卡算力。
- FP4精度支持:计算吞吐量提升4倍,显存占用减少75%。
- 192GB HBM3e显存:带宽高达8TB/s,是H100的2.4倍,满足大模型推理的内存需求。
除了硬件层面的突破,英伟达还在进行一场商业模式的演进,推出了NIMs(NVIDIA Inference Microservices),通过软件许可费将硬件优势转化为生态系统的长期锁定。这种策略旨在加深其在AI生态系统中的影响力,不仅仅是销售硬件,更是构建一个完整的解决方案平台。
2. 云巨头的反击:自研芯片的崛起
在另一边,谷歌、亚马逊、微软、Meta等超大规模云服务商正积极部署自研芯片,目的只有一个:解耦对英伟达昂贵硬件的依赖,并优化其在特定用途和成本上的表现。
“数据中心即计算机”——这是谷歌TPU所代表的垂直整合系统设计哲学。这些云巨头通过自研芯片,不仅降低了成本,更获得了对硬件和软件栈的完全控制权,从而实现极致的优化。
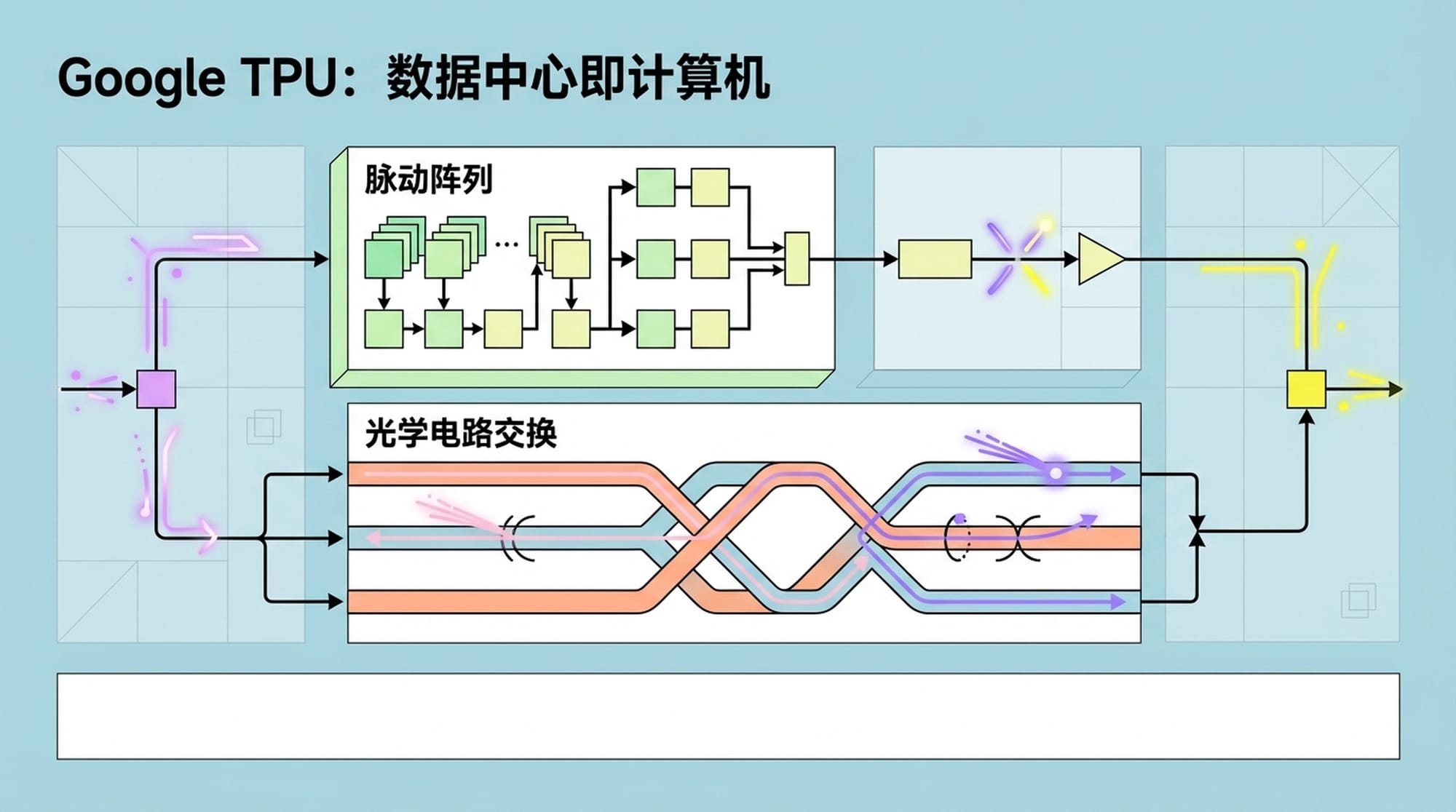
Google TPU:脉动阵列与网络优化的艺术
谷歌的TPU是这场挑战的代表。其核心是脉动阵列,一种专门为矩阵运算优化的架构。谷歌真正的独门秘籍在于其自研的光学电路交换 (OCS) 和 Jupiter数据中心网络,这使得网络层的功耗降低了41%,极大地提升了整体效率。
除了谷歌,AWS的Inferentia2和Meta的MTIA2也都是针对特定用途和成本优化而生的芯片。Inferentia2基准测试显示,其每百万Token成本比同级别GPU实例低40%到50%。
- ASIC在成本上的优势:
- 设计优化:ASIC为特定任务量身定制,避免了通用GPU的额外开销。
- 规模效益:云服务商巨大的采购量和部署需求,使得自研芯片的成本优势更加明显。
值得一提的是,在这个自研芯片的浪潮中,我们还有一个**“隐形冠军”——博通 (Broadcom)**。作为谷歌TPU和Meta MTIA的幕后推手,博通提供了关键的IP和设计能力,默默支持着这些巨头对抗英伟达。
总拥有成本(TCO):性能之外的算计
在推理市场,单纯的性能是基础,但总拥有成本 (TCO) 才是决定性的因素。我们估算,纯硬件成本上,ASIC方案确实比H100低了30%到50%。然而,TCO远不止硬件租金那么简单!
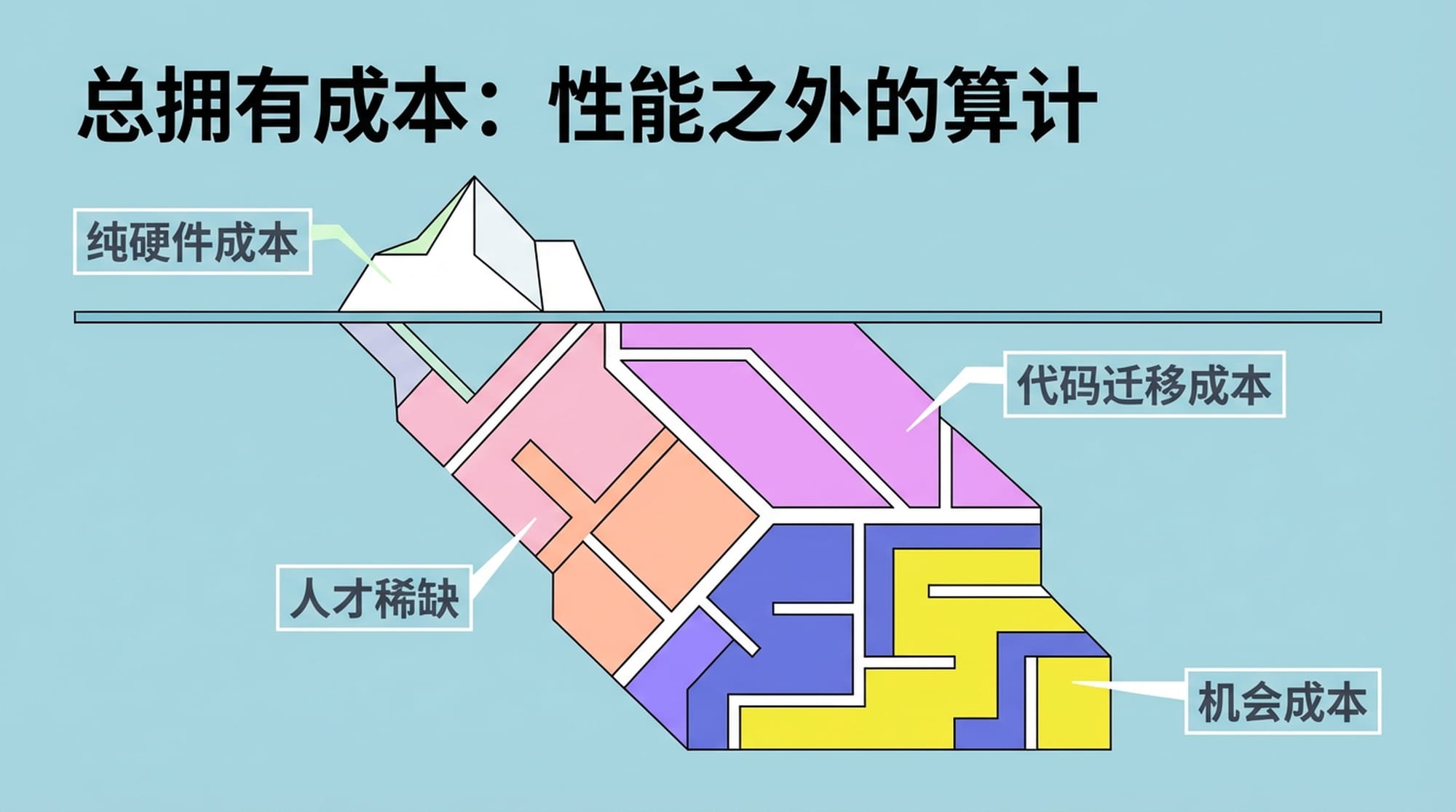
这里隐藏着一个巨大的**“迁移税”**:
- 代码迁移成本:从CUDA生态迁移到JAX或Neuron需要重写大量代码,这可能意味着数月的工程停滞。一个5人高级工程师团队,三个月的迁移成本就高达37.5万美元。
- 人才稀缺:熟悉特定ASIC架构的工程师人才数量有限,增加了招聘和维护成本。
- 机会成本:迁移带来的延误可能导致市场机会的丧失。
因此,企业在选择AI硬件时,需要全面考量这些隐性成本。短期看,ASIC成本更低;长期看,生态系统的兼容性和开发效率可能更重要。
供应链:CoWoS的战略地位
2024年到2027年的市场份额,在很大程度上将由台积电的CoWoS先进封装产能决定。AI芯片不是“设计”出来的,很大程度上是“封装”出来的!目前CoWoS产能极度紧缺,这使得拥有更强议价能力和预订能力的厂商占据优势。
CoWoS封装技术是高性能AI芯片实现其算力密度和互联能力的关键。谁能获得更多的CoWoS产能,谁就能更快地将高性能AI芯片推向市场,从而抢占先机。
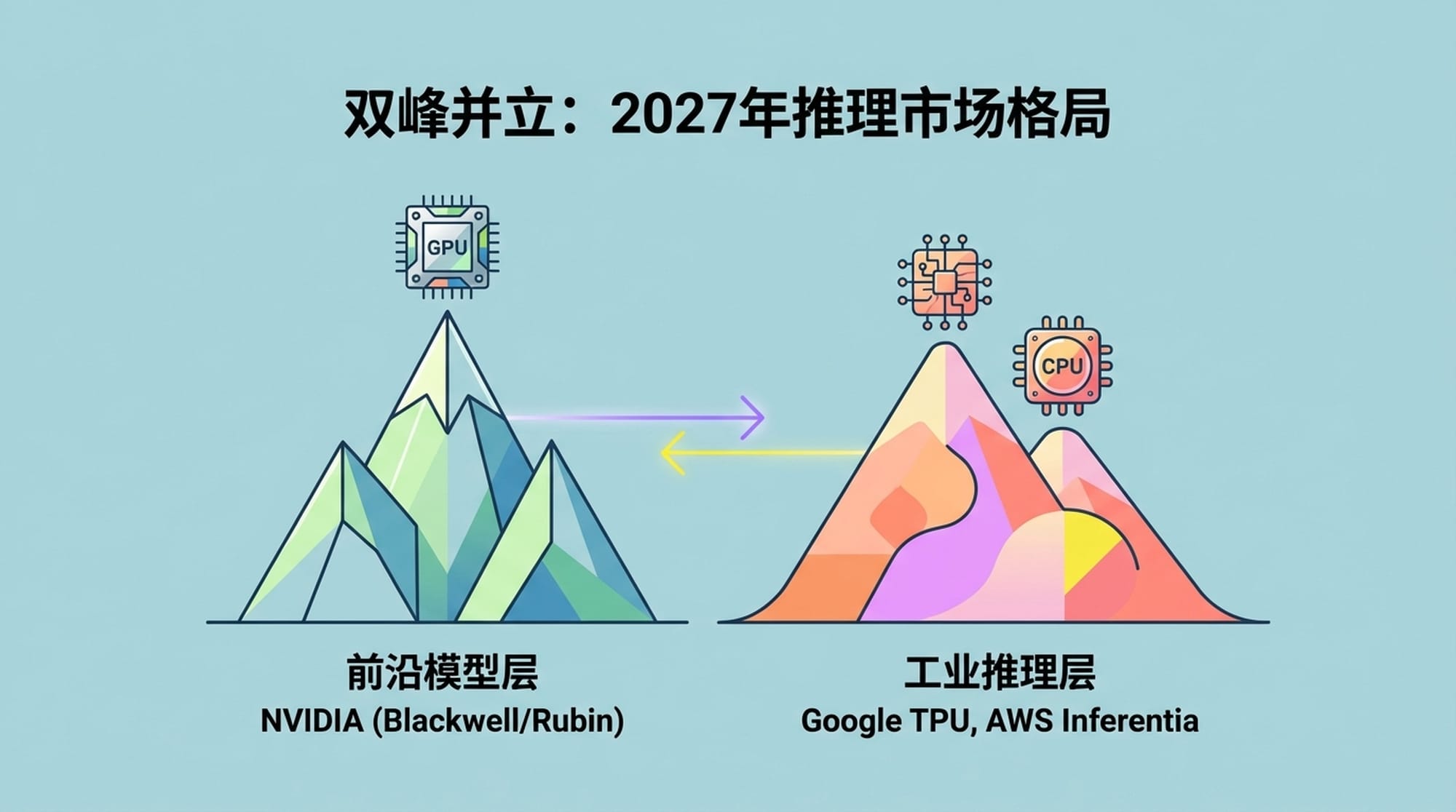
2027年AI推理市场格局展望:双峰并立
展望未来,2027年的AI推理市场将呈现清晰的**“双峰”结构**:
- 前沿模型层 (Frontier Model Layer):运行GPT-5、Claude-4这类级别的超大模型。这将是英伟达的天下,其Blackwell和Rubin架构将凭借通用性、高性能和成熟生态系统占据主导地位。
- 工业推理层 (Industrial Inference Layer):运行Llama 3 8B/70B、Mixtral等标准化开源模型,处理日常的海量低成本负载。谷歌TPU、AWS Inferentia等ASIC将在各自的云生态内占据主导地位,专注于成本效益和特定场景优化。
代理智能:新变量与潜在影响
我们还需要考虑一个新的变量:代理智能 (Agentic AI) 的发展。AI正从单纯的“聊天机器”向能够自主规划、调用工具、多步推理的“智能代理”演进。
代理在做出反应前可能需要进行多步思考和复杂决策,这大幅增加了推理的计算量,不仅仅是内存读取,更涉及到复杂的控制流和工具调用。
这种变化可能会重新利好通用性更强的GPU,因为ASIC脉动阵列在处理这种复杂、非线性的逻辑时可能会力不从心。GPU的灵活性和编程能力使其能够更好地适应代理智能带来的新挑战。
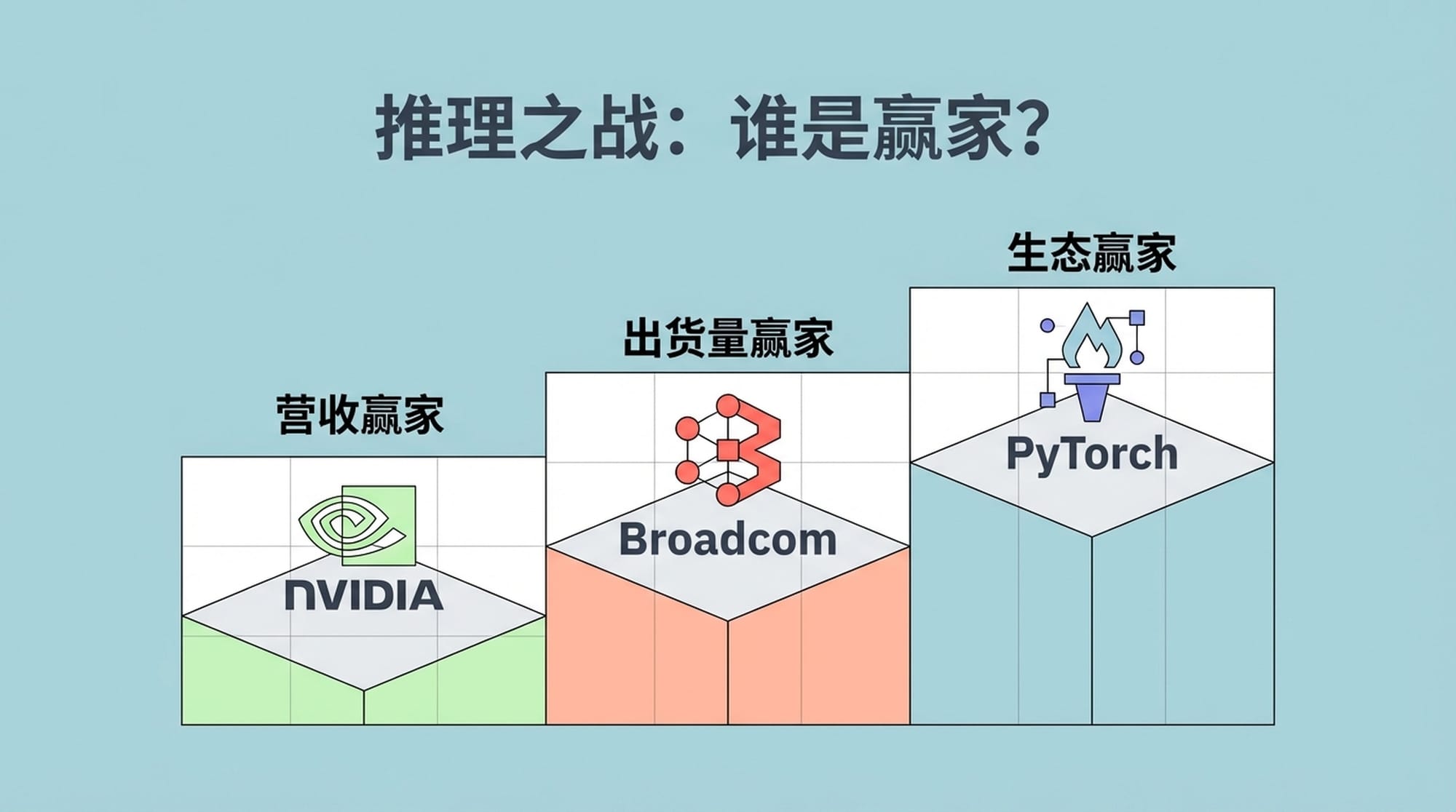
推理之战:谁是赢家?
那么,谁才是这场推理大决战的最终赢家呢?
- 营收赢家:英伟达 (NVIDIA)。凭借其领先的硬件技术和日益成熟的软件生态(NIMs),将持续在高性能AI领域占据主导地位。
- 出货量赢家:博通 (Broadcom) 和 Marvell。作为ASIC芯片背后的技术提供者,它们将受益于云巨头的大规模自研芯片部署。
- 生态赢家:PyTorch。无论底层是CUDA、XLA还是Neuron,PyTorch已成为事实上的API标准。硬件的差异化将逐渐被上层框架所屏蔽,开发者可以基于统一的接口进行开发。
异构计算新世界:企业家的战略选择
对于各位企业决策者而言,2024到2027年的AI硬件选择,不再是一道简单的单选题,而是一道基于业务生命周期的战略题。
- 探索和研发阶段:英伟达GPU是无可替代的加速器,它提供了最大的灵活性和最快的迭代速度,帮助企业快速验证想法和迭代模型。
- 大规模稳定运营阶段:一旦业务进入成熟期,拥抱TPU或ASIC带来的投资回报,将成为企业盈利的关键。通过高度优化的ASIC,企业可以显著降低运营成本,提升效率。
这场推理市场的战争,最终不会产生一个单一的胜利者,而是会形成一个各安其位、高度专业化的异构计算新世界。不同的AI应用场景,将匹配最适合其需求和成本效益的底层硬件。理解并选择正确的路径,将是未来几年AI领域成功的关键。