
在业界一片对“摩尔定律已死”的悲观论调中,一项革命性进展正悄然改变AI芯片的未来。斯坦福大学与麻省理工学院(MIT)的科学家们联手,在一个看似“过时”的90纳米晶圆上,成功研制出一种性能远超最先进2D芯片的单片3D AI芯片。这听起来如同科幻小说般不可思议:老旧的生产线上,竟能诞生颠覆性的未来科技。

“摩尔定律已死”?90纳米老工艺的逆袭之路
当所有人都认为AI芯片的算力增长已接近瓶颈时,为何斯坦福和MIT能在90纳米这一“古老”工艺上,开辟出一条性能提升十多倍的新路径,甚至超越了3纳米的先进制程?这背后隐藏的,是怎样的“黑科技”?
这个并非纸上谈兵的实验室成果,而是由Subhasish Mitra教授和Max Shulaker教授领衔的团队,在美国SkyWater Technology商业晶圆厂成功“流片”并经过严格测试的硬核技术。它揭示了一个深刻的道理:法拉利跑车在乡村土路上跑不快,并非车本身的问题,而是道路限制了其性能。 这些科学家没有致力于“制造更快的法拉利引擎”,而是另辟蹊径,为“乡村土路”修筑了一条“空中高速公路”。
“这项研究成果表明,芯片性能的瓶颈已不再是晶体管的微缩,而是数据在芯片内部的搬运效率。我们现在要做的,是重新定义芯片的‘道路系统’。”
近日,IEEE国际电子器件会议(IEDM 2025)公布了这项爆炸性研究:斯坦福、MIT联合卡内基梅隆大学、宾夕法尼亚大学等顶尖机构,在SkyWater Technology量产出全新的“单片3D AI芯片”。这款芯片在处理Meta开源大模型Llama等任务时,性能提升了足足12倍,早期硬件原型测试也显示,其性能比同类2D芯片提升约4倍。这好比你手中的电脑瞬间提速十倍,所有卡顿和等待烟消云散,用户体验的飞跃是显而易见的。

痛点:冯·诺依曼架构的“内存墙”与“小型化墙”
当前,AI大模型动辄数千亿、上万亿的参数量,其算力消耗堪称天文数字。然而,我们现有的芯片架构仍停留在几十年前的冯·诺依曼时代。这就像CPU或GPU这颗“大脑”与内存这个“仓库”彼此分离,大脑每次取数据都需跋涉至仓库,耗费大量时间与能量,远超实际处理数据的时间。
冯·诺依曼瓶颈导致处理器80%的功耗甚至更多时间浪费在数据在芯片内部和外部的“通勤”上,学术界称之为“内存墙”。
这种效率低下,使得处理器常常处于闲置等待数据的状态,极大地浪费了宝贵的计算资源。

除了“内存墙”,我们还面临“小型化墙”。过去几十年来,芯片性能的提升主要依赖于摩尔定律,即晶体管数量每18个月翻一番。然而,如今晶体管已接近原子级别,物理极限(如漏电、散热)使得进一步缩小尺寸变得异常困难。建造一座最先进的晶圆厂动辄数百亿美元,能够承担的厂商屈指可数。仅仅依靠缩小晶体管,已无法满足AI领域每3.5个月性能翻一番的疯狂需求。
目前许多“高性能AI芯片”,如英伟达H100,尝试通过2.5D封装或HBM高带宽内存来缓解问题。这些技术相当于为“乡间小路”拓宽了些许,或修建了短途捷径。然而,它们本质上仍是将两个独立芯片堆叠,芯片间的连接点稀疏且粗大,数据搬运效率受限,且成本高昂、良率挑战巨大。
“单片3D集成”:构建计算界的“曼哈顿”
斯坦福和MIT团队提出的**“单片3D集成”技术**,彻底颠覆了现有格局。它与传统芯片堆叠有着本质区别:
- 传统堆叠:将两块已制成的芯片“粘合”在一起,精度受限,连接点稀疏,效率难以大幅提升。
- 单片3D集成:在同一硅晶圆上,像建造摩天大楼一样,一层一层地“生长”出新的电路。它不是“拼乐高”,而是在地基之上直接浇筑第二、第三层,精度可达纳米级别,使得存储单元能精密地分布于计算单元正上方,实现真正的存算一体。
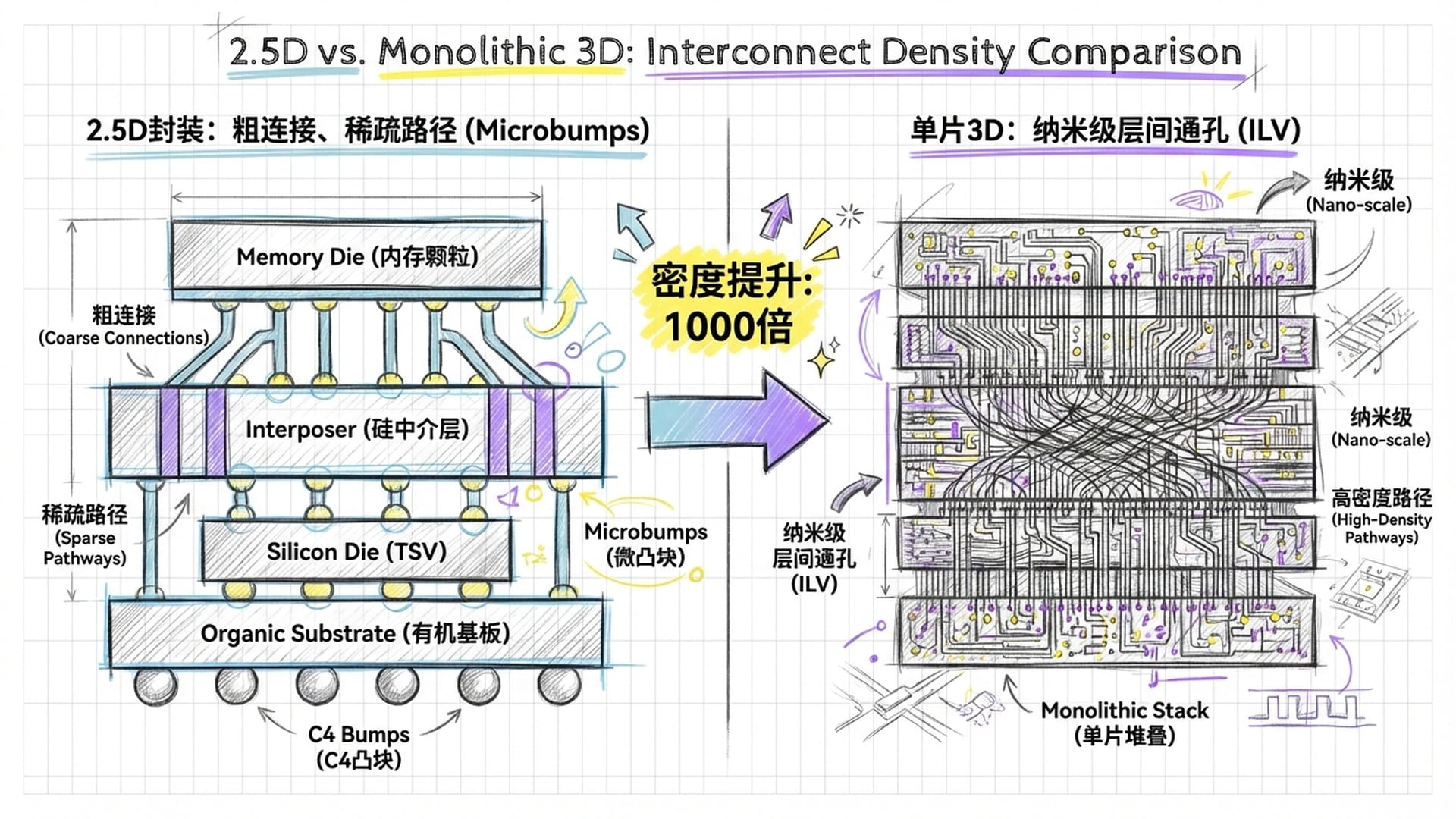
这项技术的核心是实现**“纳米级层间通孔”(ILV)。这些直径仅几十到一百纳米的“超高速电梯”,使得每平方毫米芯片面积能容纳数亿个连接点,比传统堆叠方式提升千倍!这意味着设计师可像连接芯片内部逻辑门一样,随心所欲地在垂直方向上布置数亿数据通道,从而实现计算单元与存储单元的“零距离”通信**。
研究人员形象地将这种设计比喻为“计算界的曼哈顿”。传统2D芯片如乡下大平房,组件分散,数据传输距离远。而单片3D芯片则在有限空间内建起摩天大楼,所有数据在垂直方向瞬间移动,极大提升效率。
在这种“曼哈顿”架构中,芯片整体结构如同一个“三明治”:
- 底层:采用SkyWater 90纳米工艺制造的标准硅CMOS电路,作为“大楼地基”,负责核心计算、全局控制以及模拟电路(如“隐蔽式灵敏放大器”)。
- 中间层:多层堆叠的RRAM存储阵列,用于存储数据,其容量随层数线性增加。
- 最上层:CNFET逻辑层,充当可以进行简单计算的“小大脑”,直接处理来自紧邻RRAM层的数据,实现存内计算或近存计算。
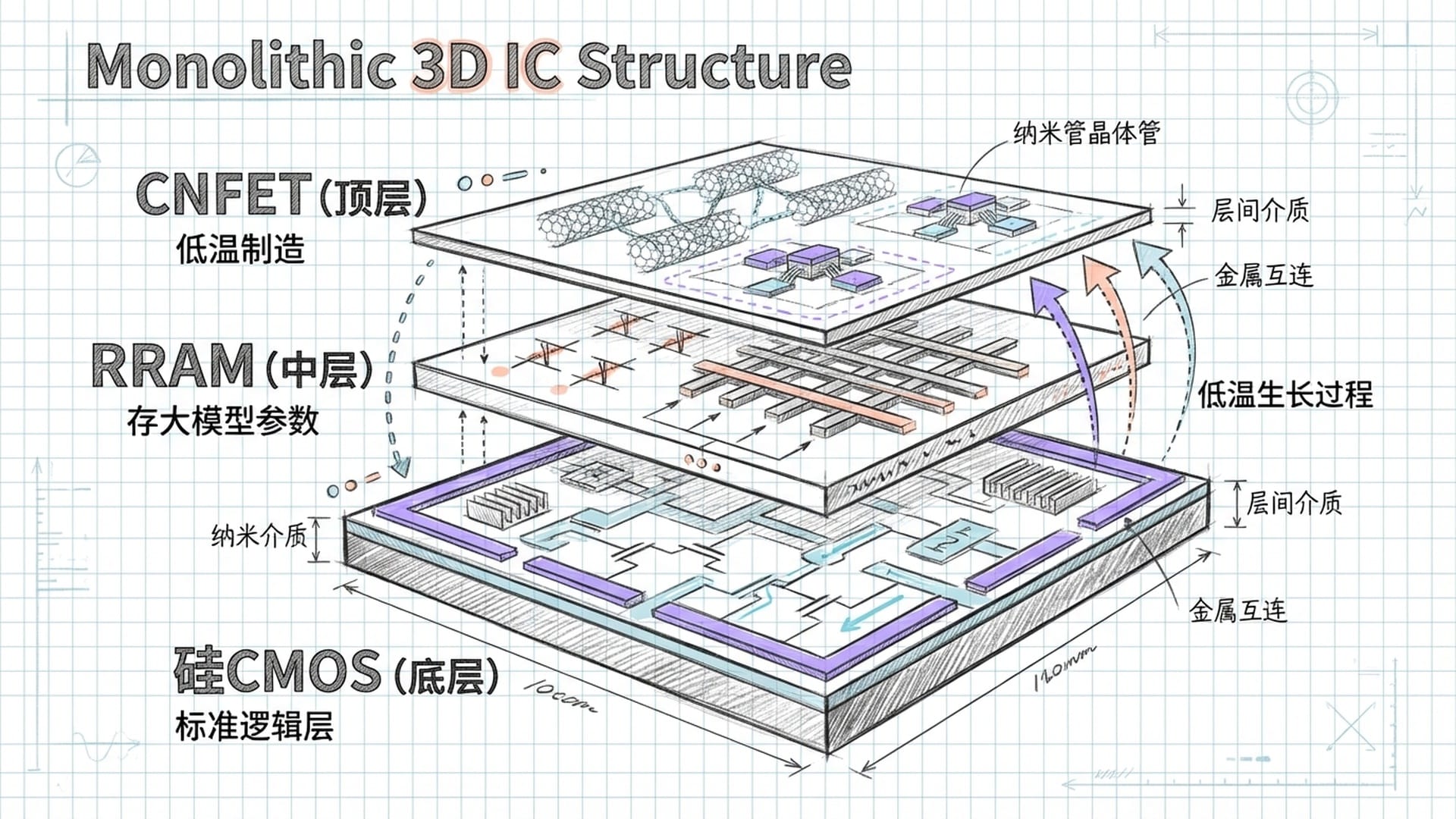
这种异构集成策略将各种材料的优势发挥到极致:硅CMOS提供稳定可靠的基础,RRAM提供超高密度存储,CNFET提供低温制造的高性能逻辑,共同应对AI大模型的复杂负载。
突破:低温制造的“黑科技”组合
实现“单片3D”的关键挑战是温度。传统半导体工艺需千度高温,若在此高温下在底层电路之上“生长”新层,底层金属布线将熔化。斯坦福和MIT的突破在于整合了两种可在低温下制造的“黑科技”:
- 碳纳米管场效应晶体管(CNFETs): CNFETs可在低于400摄氏度甚至室温下制造,这意味着它们可以直接在已完成的CMOS底层逻辑上“安全生长”,无需担心高温损坏。此外,CNFETs电学性能优异,比同尺寸硅晶体管更省电、速度更快。MIT Max Shulaker教授团队经过长期深耕,解决了碳纳米管提纯、排列等世界性难题,才使CNFETs的大规模高良率生产成为可能。在新的3D芯片中,CNFETs负责上层逻辑电路的本地处理和控制,响应速度极快。
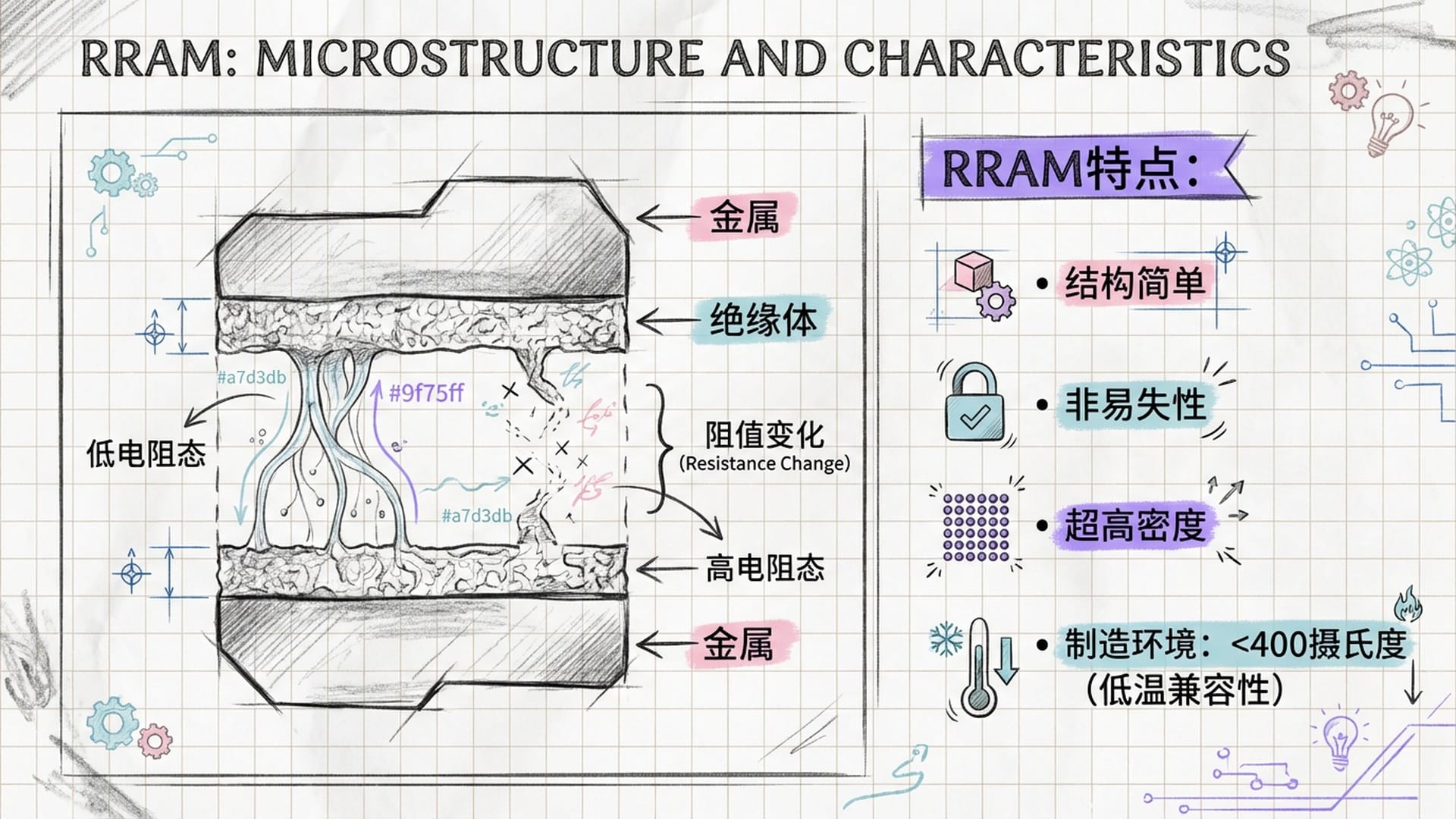
- 电阻式随机存取存储器(RRAM):RRAM结构简单,通过改变绝缘材料的电阻来存储数据,单元面积极小且具有非易失性(断电数据不丢失)。这使其成为AI大模型海量参数存储的理想选择。更重要的是,RRAM的制造工艺完全兼容芯片后端制程,可在低温下完成,直接在金属互连层中制造。通过多层RRAM堆叠,芯片内部存储密度惊人,几乎可将整个AI模型参数封装在芯片内,彻底解决数据频繁出入片外内存的问题。
图:RRAM存储结构微观图
这项技术的成熟并非一蹴而就。早在2017年,《Nature》杂志便刊登过Max Shulaker团队的论文,展示了CNFET和RRAM组成的单片3D芯片原型,验证了低温集成的可行性。随后,美国国防高级研究计划局DARPA资助的“电子复兴计划”促成了MIT、斯坦福和SkyWater的合作。2020年,SkyWater发布了业界首个基于CNFET的90纳米工艺设计套件,标志着该技术走向商业化、标准化,为IEDM 2025的重磅成果奠定基础。
架构创新:隐蔽式灵敏放大器与性能飞跃
此次IEDM 2025论文不仅展示了材料创新,还披露了专门为单片3D特性定制的电路架构创新,其中最引人注目的是**“隐蔽式灵敏放大器”**。
在传统存储器设计中,灵敏放大器扮演着将存储单元微弱电流信号转换为数字信号的“翻译官”角色。它通常占据较大面积,且只能置于存储阵列边缘,限制了存储密度和数据读取速度。
“有了单片3D的高密度垂直互连,科学家们玩了一个‘藏猫猫’的游戏:他们把这个占用面积很大的‘翻译官’,偷偷地藏在了存储阵列的正下方,也就是底层的硅CMOS逻辑层里。”
这种“隐蔽式”设计释放了存储层的宝贵空间,使RRAM阵列得以紧密排列,存储密度倍增。由于“翻译官”紧邻存储单元,通过极短的“纳米电梯”连接,信号传输距离被压缩到极致,不仅大幅降低延迟,还允许更多“翻译官”同时工作,使存储器读取带宽翻了好几番。论文指出,此设计相比传统CMOS基准,读取带宽提升了4倍。
实测数据:Llama模型性能提升12倍,能效改善千倍
本次IEDM 2025的论文并非空谈,而是提供了实打实的测试数据。在SkyWater制造的原型芯片上,团队进行了全面的电气特性测试,并与同样采用90纳米工艺的传统2D芯片进行对比:
- 计算吞吐量提升约4倍,验证了数据传输瓶颈解决后,计算单元能满负荷运行。
- 数据读取带宽提升4倍,访问延迟显著降低。
研究团队还基于实测数据进行模拟预测:当芯片层数进一步增加时,单片3D芯片在运行Llama模型时,预计可实现高达12倍的速度提升。这意味着Llama模型原本需1秒生成一段文本,现在仅需不到0.1秒,用户体验将有质的飞跃。
更令人振奋的是,在衡量芯片综合效率的关键指标——*能量延迟积(EDP)*上,未来的3D芯片有望实现100到1000倍的改善。这预示着完成同样的AI推理任务,能耗可能仅为现有芯片的几百分之一,或在相同能耗预算下,性能提升数百倍。
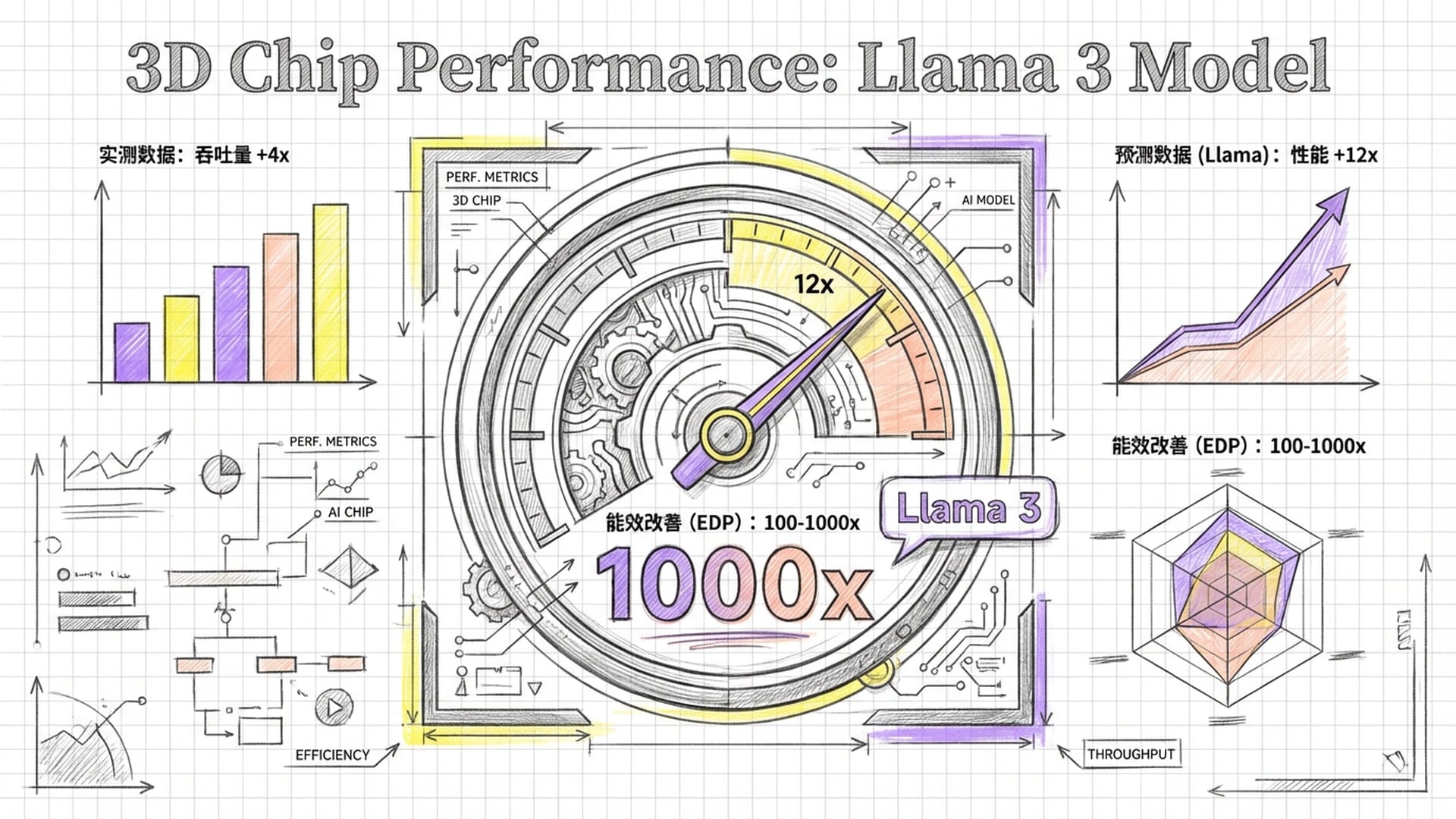
Llama这类基于Transformer架构的大语言模型,是典型的“访存密集型”应用,大部分时间都耗费在从内存中获取数据。每次生成一个Token,都涉及数十亿参数从内存搬运至计算单元,这在传统2D芯片中占据了推理延迟的绝大部分。单片3D架构通过将海量RRAM存储直接堆叠于计算逻辑之上,并用高带宽纳米电梯连接,使所有参数变为**“片上缓存”**。这种超低延迟、超高带宽的访问模式,几乎消除了“权重加载”时间,让计算单元得以持续满负荷运行,如同将法拉利跑车置于畅通无阻的超级高速公路上,澎湃动力得以火力全开,因此在Llama这类大模型负载上展现出远超传统的加速比。
战略意义:重塑边缘AI与供应链自主化
该项目最大的里程碑在于证明了这些技术可真正实现量产。选择在90纳米这一“老古董”工艺上实现突破,本身就蕴含深意:
- 验证成本与可行性:90纳米是一个高度成熟、成本低廉、良率极高的工艺节点。作为首次商业代工级验证,采用成熟节点能大幅降低试错成本,快速确立技术基线。
- 3D缩放的红利:研究核心论点是3D缩放(垂直堆叠)比2D缩放(晶体管平面缩小)能带来更大红利。数据表明,单片3D的90纳米芯片在能效和吞吐量上甚至可超越7纳米的2D芯片,因为AI瓶颈已不在于晶体管开关速度,而在于数据在芯片内的传输速度。
- 设备兼容性与经济性:CNFET和RRAM的沉积工艺已成功整合到SkyWater标准200毫米量产流程中。这意味着这种“异构集成”无需颠覆现有代工厂基础设施,也无需昂贵的EUV光刻机,对盘活全球现有成熟制程产能具有巨大经济意义。
论文强调,该芯片制造良率高,且使用标准半导体制造设备。与台积电需昂贵高精度混合键合设备的方法不同,单片3D通过沉积生长实现层间连接,避免了复杂的对准和键合步骤,潜在制造成本更低,使其在物联网、边缘计算等成本敏感领域极具竞争力。
当然,单片3D芯片也面临挑战,散热是其中之一。将如此多计算和存储单元堆叠在一起,热量难以散发。学界和业界正探索“层间冷却”技术,如集成微流控通道,让冷却液在芯片内部穿梭。值得注意的是,单片3D芯片极大降低了数据传输功耗(通常是芯片总功耗的大头),因此在同等性能下,其整体发热量可能反而低于传统芯片,这在一定程度上缓解了散热压力。
斯坦福大学的Subhasish Mitra教授表示,现有成果只是开始。随着堆叠层数从几层增至几十层、上百层,以及制造工艺从90纳米迁移至28纳米、14纳米等更先进节点,未来的单片3D芯片有望实现1000倍的综合性能提升,彻底打破现有计算物理限制,为通用人工智能AGI的实现提供必要硬件基础。

这项技术对我而言,还有一个特别重要的战略意义:它将重塑边缘AI,并推动供应链自主化。高能效、高密度的单片3D芯片意味着未来手机、无人机、AR眼镜等电池供电的边缘设备可直接运行Llama这类大模型,无需联网即可实现本地AI智能,彻底改变物联网和消费电子形态。
在全球芯片供应链日益紧张的背景下,斯坦福-MIT-SkyWater的合作展示了一条**“弯道超车”**路径,即不依赖东亚先进制程供应链,通过材料和架构创新,美国本土中低端晶圆厂也能制造出性能匹配甚至超越最先进节点的特定用途AI芯片,这对于国家安全和供应链韧性具有重要战略意义。
总而言之,斯坦福和MIT联手SkyWater打造的单片3D AI芯片,不仅是技术突破,更是半导体发展史上的重要转折点。它用工程实践证明了:在原子尺度上打破计算和存储物理边界是可行的,并可在成熟商业产线上实现。它有效解决了大模型时代“内存墙”和“小型化墙”这两个困扰我们几十年的大问题,预示着未来的摩尔定律将不再仅依赖光刻机波长,而取决于我们能在垂直方向上,把智慧高塔盖得多高。随着工艺设计套件的发布和生态的建立,我们有理由相信,这种基于“曼哈顿”理念的3D芯片,将在未来几年内从实验室走向千行万业,驱动人工智能从云端数据中心走向无处不在的边缘设备,真正融入我们的生活。