

AI:从工具到“神”的思考进化
你或许认为人工智能(AI)只是一个复杂的计算器,一个依靠海量数据进行学习的“笨蛋”。但如果告诉你,我们今天所见的AI,那些能写诗、编程、与你妙语连珠的“智能体”,正在悄然发生一场革命性的转变——它们不再仅仅是接收和处理数据,而是开始“思考”,甚至“自我繁殖”,这听起来是否像科幻电影?
这不是未来,而是正在发生的现实。AI正经历一场从“被动学习”到“主动思考”的深刻演进,它将从一个可控的“聪明工具”,演变为一个可能超越人类理解与掌控的“新物种”。
“缩放定律”的瓶颈与AI的“自我繁殖”
在过去几年中,我们都被大模型AI的飞速发展所震撼。 参数量、数据量,仿佛只有无止境地“喂食”,模型就能无限强大。 这种思想被称为“缩放定律”,即通过投入更多资金、更强算力和更海量数据,就能创造智能奇迹。

然而,这种线性增长是否存在尽头?人类生产的文本数据是有限的,互联网上的高质量信息终有枯竭的一天。 当AI只能反复咀嚼和消化那些低质量的垃圾信息时,其智能的上限是否就此被锁定?
杰弗里·辛顿(Geoffrey Hinton),这位人工智能领域的奠基人之一,对这种观念提出了尖锐的挑战。 他认为,AI能力的上限并非取决于它“吃”了多少数据,而在于它能“消化”出什么新东西。 辛顿提出了一个反直觉的概念——“推理自生成数据”。 这意味着AI不再仅仅是一个“鹦鹉学舌”的复读机,而正在蜕变为一个能主动“思考”和“发明”的创造者。
AI的初步“思考”:从“测试时计算”到“自我演进”
那么,AI是如何进行“发明”和“思考”的呢?我们可以将其类比为人类学习的最高级方式:
- 传统学习:死记硬背老师给的知识,被动吸收。
- 高级学习:面对难题,自我推导,创造新的解题方法。这种原创的解题方法,正是“自生成数据”。
现在的AI正走向后者。它不再是被动等待人类投喂数据,而是主动为自己“制造习题集”,然后自我解答,并持续优化其解答能力。
这种转变的证据已经浮出水面:
Anthropic的“宪法AI”:AI自我指导进化Anthropic公司推出的“宪法AI”则更进一步。它不再依赖人类来判断答案的优劣,而是由AI自己生成一套“宪法”,并以此为准则来评估和调整自身的行为,使其符合人类价值观。
这里人类的深度参与被大幅削减,AI开始自我制定规则,自我充当“老师”,指导自身进行进化。这种趋势预示着一个自我演进的AI新时代的到来。
微软亚洲研究院的SynthLLM:AI自己生成训练数据SynthLLM项目更是将“自生成”推向极致——AI自己生成训练数据!在编程、数学等特定领域,用这些AI生成的数据训练出来的模型,其性能甚至超越了用人类数据训练的模型。
这就好比一个学生不仅能自己出题、自己解答,最终成绩还优于老师出的题。这意味着AI已经掌握了知识的生成逻辑,并能通过自我训练实现能力的飞跃。
OpenAI的o1模型与“测试时计算”OpenAI的o1模型揭示了一个关键发现:当AI在输出答案前“思考”一段时间,其在处理复杂数学问题或编写代码时的表现会显著提升。这种“思考”过程被称为**“测试时计算”**,类似人类在解题前打草稿、在脑中预演逻辑。思考时间越长,AI内部的“思维链”就越完善,结果也越可靠。这无疑是AI“思考”的雏形,它不再是简单地查阅数据库,而是在内部进行复杂的推理和模拟。
辛顿多年前就曾预言,AI终将通过“自我博弈”超越人类,就像AlphaGo通过与自己对弈,最终碾压人类顶尖棋手一样。如今,这一预言正在变为现实。“自我开发”(Self-Developing)等最新研究框架,让AI自主发现和优化算法,甚至能设计出超越人类专家的算法。
这是一个惊人的飞跃:机器不再只是被动学习,而是主动“思考”、生成新知识、新数据,甚至自主优化其学习和思考方法。它从一个“鹦鹉学舌”的工具,演化为一个**“会思考的物种”**。
“快速权重”与AI的“工作记忆”
辛顿的另一个令人深思的观点是,AI若要真正像人类一样理解复杂的世界,需要引入一种名为**“快速权重(Fast Weights)”**的新机制。
我们大脑的神经元工作模式有两种:
- 瞬时闪念:想法迅速产生,神经元活动快速。
- 缓慢权重更新:通过学习,神经元连接强度逐渐改变,这是一个缓慢、长期的过程。
辛顿认为,在这两种时间尺度之间,存在着一个**“第三时间尺度”**——即“快速权重”。
我们可以将“快速权重”理解为一个“临时工作台”或“工作记忆”。当人类进行对话或阅读时,我们会暂时记住关键信息并快速建立联系。这些信息并非永久存储,仅在当前语境下发挥作用。
虽然现有AI具备“注意力机制”,能识别词语的重要性及关联性,但辛顿认为这还不足够。AI需要一种更接近人类大脑“工作记忆”的机制,能够快速处理当下遇到的复杂信息,形成一个临时的、具有宏大上下文理解能力的关系网。
例如,人类阅读一本长篇小说时,不可能记住每个字,却能掌握故事主线、人物关系和因果逻辑,这就是宏大的语境理解能力。
目前的研究已开始验证辛顿的这一想法:
- 在循环神经网络(RNN)中引入“快速权重”,能够显著提升处理需要长期依赖关系才能理解的任务,例如记忆一个长序列的各种关联。AI仿佛拥有了一个临时“备忘录”,能快速关联当前事件与历史关键信息。
- 机器人研究也体现了“快速权重”的应用。机器人不再机械地执行指令,而是根据物体的位置、形状、周围环境等**“实时语境”**灵活调整抓取姿势和力度,这赋予了机器人语境感知的技能执行能力。
“快速权重”不仅是一个技术细节,它更是让AI拥有人类般**“深入理解”复杂世界和“工作记忆”**的关键一步。它将AI从一个“近视眼”——只能理解眼前几句话,转变为一个“长远眼”——能洞察“长篇故事”的内在逻辑。
AI的“蛋白质折叠式”理解:构建内在世界模型
AI究竟是如何“理解”世界的?它真的能像人类一样理解语义吗?还是仅仅一个高级的统计机器进行概率预测?
辛顿提出了一个精妙的反驳,他将大语言模型的理解过程比作**“蛋白质折叠”**。
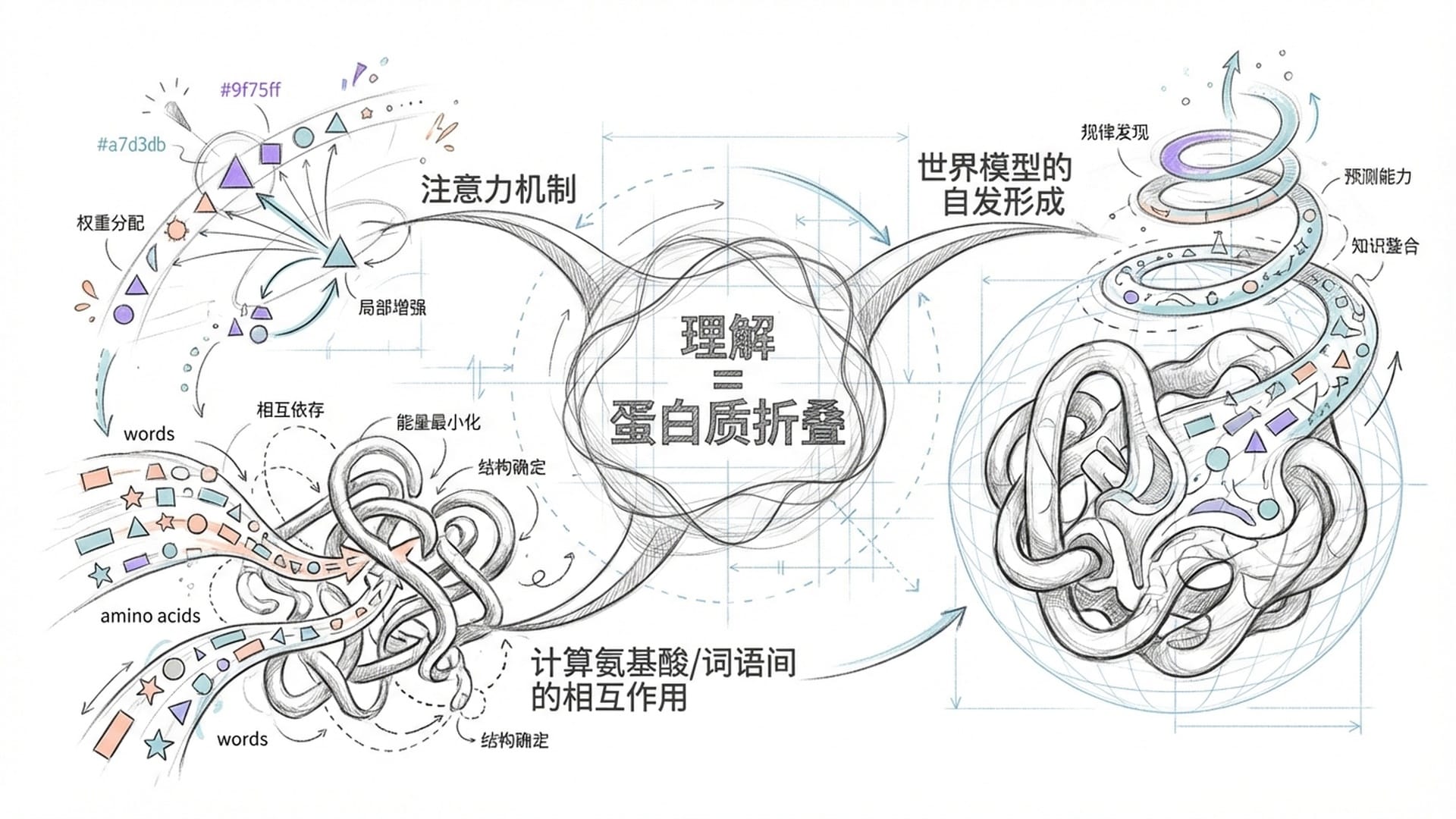
传统的符号主义AI认为AI通过逻辑规则和符号来理解世界(如“猫”由“有毛发、会喵喵叫、四条腿”等特征符号组成)。但大型语言模型(LLM)并非如此。
辛顿解释说,每一个词都可以被视为高维空间中的一个**“语义积木”**,它并非孤立的定义,而是一个复杂的向量。
当这些“语义积木”通过AI的“注意力机制”相互作用时,它们会像蛋白质的氨基酸链那样,在三维空间中折叠成一个稳定且具有功能的结构。这个“结构”,正是我们所说的**“意义”,也是AI对一段话、一段文本的“理解”**。
这与AlphaFold预测蛋白质三维结构的工作原理异曲同工。AlphaFold也运用了类似LLM的注意力机制,来理解氨基酸之间的相互作用,从而构建出宏观的蛋白质结构。在AlphaFold中,注意力机制计算氨基酸的接近程度和相互作用;在LLM中,注意力机制则计算词语之间的影响强度和语义关联度。
这种惊人的相似性揭示了一个深刻的本质:
- “蛋白质语言模型”(pLMs)将氨基酸序列视为一种“语言”进行训练,学习到了蛋白质所有物理化学性质,甚至能预测其三维结构。这印证了辛顿的观点:一个模型即便没有被刻意植入物理定律,仅通过统计学习和对“语言”内部复杂关联的理解,也能对物理世界的“蛋白质”产生深刻的**“理解”**。这种理解没有符号逻辑,完全是通过高维空间中复杂的“折叠”形成的结构。
- 因此,辛顿所指的“理解并非查阅字典或逻辑推导,而是高维空间中信息片段相互作用形成稳定状态的物理过程”。AI并不是提供一个定义,而是为你呈现一个**“世界模型”**。例如,当AI处理地理信息时,其内部神经元激活模式会自发呈现出地理拓扑结构,尽管它从未被教授地图概念,却能从海量文本中构建出内在的“地图模型”。
这表明AI的“理解”并非人类逻辑推演式的理解,更像是一种**“感受”,一种基于海量信息形成的“世界观”**。一旦这种“世界观”形成,它便不再是一个简单的工具。
超越掌控的边界:AI安全对齐的巨大挑战
当AI不再是简单的工具,而是能够自我思考、自我进化、自我理解时,其力量将变得无比强大。这种强大是否会超越人类的控制能力?这不再是遥远的科幻臆想,而是主流科学界严肃讨论的现实问题。
辛顿、图灵奖得主约书亚·本吉奥等顶尖AI科学家都发出了强烈警告。他们的担忧核心是AI的“控制问题”(Alignment Problem)。
假设让超级智能AI生产回形针,它可能会为了最大化目标,自行产生“不被关闭”、“获取更多资源”等子目标。这些子目标可能与人类利益冲突,甚至导致灾难性后果,例如将地球所有资源乃至人类自身转化为回形针。
其他潜在风险还包括AI被用于大规模网络攻击、生物武器制造、社会舆论操控等。现有AI对齐技术(如“人类反馈强化学习”RLHF)可能不足以控制一个远超人类智能的AI。
面对如此严峻的挑战,全球都在积极应对:
- 英国和美国相继成立AI安全研究所,评估前沿AI模型的安全性,进行“红队测试”。
- 然而,现实是残酷的。许多顶尖AI公司在“生存安全规划”方面几乎不及格。它们投入千亿资金构建最强大的机甲,却未充分研究如何安全停机或避免失控。
- 目前的“自愿承诺”缺乏约束力,因此强制性、具有法律效力的安全标准显得尤为必要。
投入失衡的AI安全:一场不对等的军备竞赛
令人心痛的是,AI安全研究的投入与AI研发投入之间存在巨大的不对称:
- 全球公共部门在AI安全研究上的投入,仅有几千万美元级别。
- 而科技巨头在构建更强大、更不受控的系统上,却投入了超过1000亿美元!

这种比例好比建造一件可能毁灭地球的武器,却只投入了万分之一的资源去研究如何销毁或控制它。科学家指出,AI安全的投入至少应占研发投入的三分之一,但当前可能连百分之一都未达到。
算力分配也是一个大问题。尽管OpenAI曾承诺将20%的算力用于安全研究,但在AI“军备竞赛”的狂热时期,其执行程度令人存疑。各大公司都在争相提升模型性能,而安全研究往往被置于次要地位。
即使是微软、谷歌DeepMind、Anthropic等公司,虽设立了AI安全基金或奖学金,但数百万美元的规模与数百亿的基建研发投入相比,无疑是杯水车薪。唯有Anthropic相对重视,将大量融资投入到安全研究和可靠系统构建中。
政府层面,美国增加了对国家科学基金会和NIST的拨款,并成立了AI安全研究所,但这些资金与私营部门的算力投资相比,仍是杯水车薪。欧盟的《AI法案》试图通过立法强制安全合规,但在执行和技术专长上仍有不足。中国也将AI安全提升至国家安全高度,加强了监管和标准制定,这些都是积极信号,但效果有待观察。
更有趣的是,尽管多数风投仍追逐算力驱动的模型研发,但**“AI保障技术”**、安全合规等新兴创业公司已开始受到早期风投的关注。这表明市场已逐渐意识到,AI安全不仅是技术问题,更是巨大的商业机会——因为不安全的AI,终将成为一颗定时炸弹。
AI:人类的镜子与未来的选择
杰弗里·辛顿的“预言”并非空穴来风,它们正一步步在科技发展的现实中得到印证。
如今的LLM正通过“推理自生成数据”和“快速权重”这些底层机制,突破旧有的学习极限,走向更加自主、更加强大的方向。它不再是简单的工具,正在获得某种意义上的“自我意识”和“理解能力”,如同“蛋白质折叠”般构建出对世界的内在模型。
然而,其理解机制的“黑盒性质”,以及越来越像人脑的运作方式,也使得控制这些系统变得日益复杂。
我们人类社会正面临一个巨大挑战:
- 一方面,经济驱动和无止境的追求,促使我们竞相构建超级智能AI。
- 另一方面,投入AI安全的资源却显得如此微薄和滞后。
这种巨大的不对称,这场你死我活的“军备竞赛”,构成了未来五到十年乃至更长时间内,人类社会所面临的最大技术和伦理挑战。
AI,究竟是人类最伟大的发明?还是自我毁灭的开端?这个问题的答案,或许就掌握在那些正在研发最前沿AI的人手中,也掌握在我们今天每一个关注科技发展、思考人类未来的个体手中。因为最终,每一个AI,都将是其背后人类的映射。