DeepMind AlphaGenome:AI破解基因组“暗物质”,开启“编程生命”新纪元
谷歌DeepMind发布的AlphaGenome模型,首次以高精度解读基因组98%的非编码区“暗物质”,打破了计算基因组学“视野与精度”的悖论,为癌症、罕见病诊断及合成生物学带来革命性突破,标志着生命科学从“读天书”迈向“编程生命”时代。

DeepMind AI 破解基因组98%“暗物质”,AlphaGenome 正式进入“编程生命”时代。
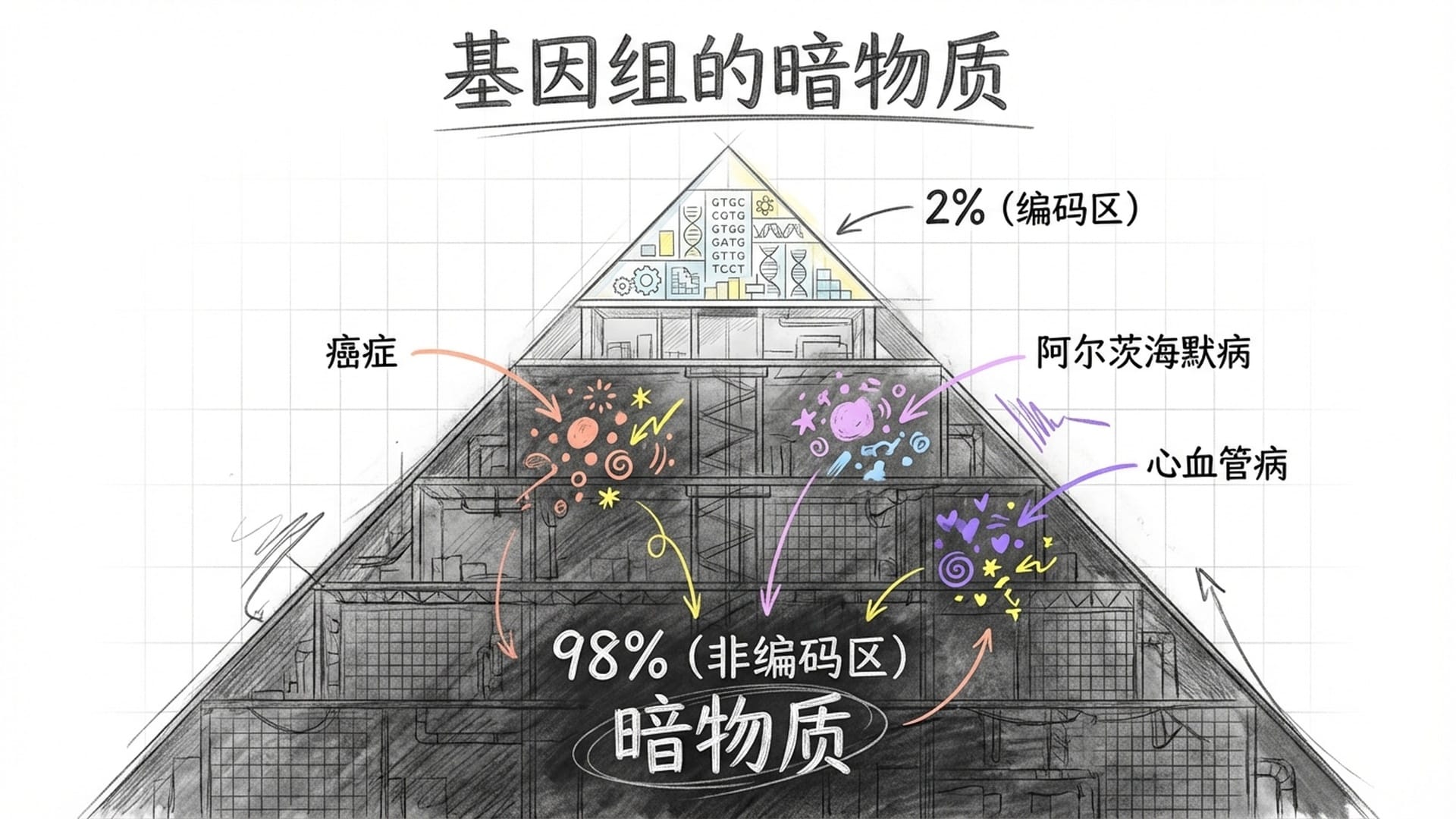
人类在2003年投入巨资、耗时13年完成了人类基因组测序,绘制出了由30亿个碱基字母组成的“生命天书”。然而,一个令人尴尬的事实浮出水面:我们能理解的基因组部分仅有2%。这好比一栋百层大楼,却只有两层能住人,其余98层被戏称为“垃圾DNA”。
二十多年后,我们才意识到这些所谓的“垃圾”非但不垃圾,反而是诸多复杂人类疾病的幕后真凶。超过98%与癌症、阿尔茨海默病、自身免疫病、心血管病等相关的遗传变异,都精准隐藏在这片我们曾一度忽视的基因组“暗物质”区域。这意味着过去二十年里,精准医学最关键的钥匙,曾被我们当作无用之物弃置一旁。
今天,我们将深入探讨刊登于《自然》杂志封面的重磅成果——谷歌DeepMind发布的AlphaGenome。这不仅仅是AI工具的简单升级,它标志着生命科学从“读天书”向“编程生命”的范式飞跃。理解了AlphaGenome,你将明白其意义可能不亚于当年的AlphaFold。
我们首先要解答一个基本问题:基因组中那98%的非编码区为何如此难以理解?
非编码区不负责编码蛋白质,但它们如同基因的“控制面板”,内含增强子、启动子、沉默子等调控元件。这些元件决定了基因何时、何地、以何种强度被“播放”。若编码区是乐谱上的音符,非编码区便是指挥家的手势。不同的指挥手势,即使乐谱相同,演绎出的音乐也截然不同。你的肝细胞和脑细胞拥有相同的DNA,却功能迥异,其差异正体现在这98%的“手势”之中。
更具挑战性的是,这些调控元件与其所控制的基因常常相距甚远,在线性DNA上可能间隔数十万个碱基。然而,在细胞核的三维空间里,DNA会折叠、弯曲,形成复杂的环状结构。这就像在纸上相距甚远的两个点,一旦纸被揉成一团,两点便会紧密接触。那些在物理距离上遥远的调控元件,在三维空间中突然“面对面”,其间的因果链条,若要依靠传统实验方法穷举验证,几乎是不可能完成的任务。
因此,临床医生们常面临一个令人沮丧的局面:患者的全基因组测序报告中,数千个变异位点绝大多数标注着“意义不明”(VUS)。医生无法判断这些变异究竟是致病元凶,还是无关紧要的背景噪音。这并非医生能力不足,而是整个领域的认知瓶颈。
于是,人工智能应运而生。然而,早期的AI模型也普遍陷入两难境地:要么看得远,要么看得清,鱼与熊掌不可兼得。
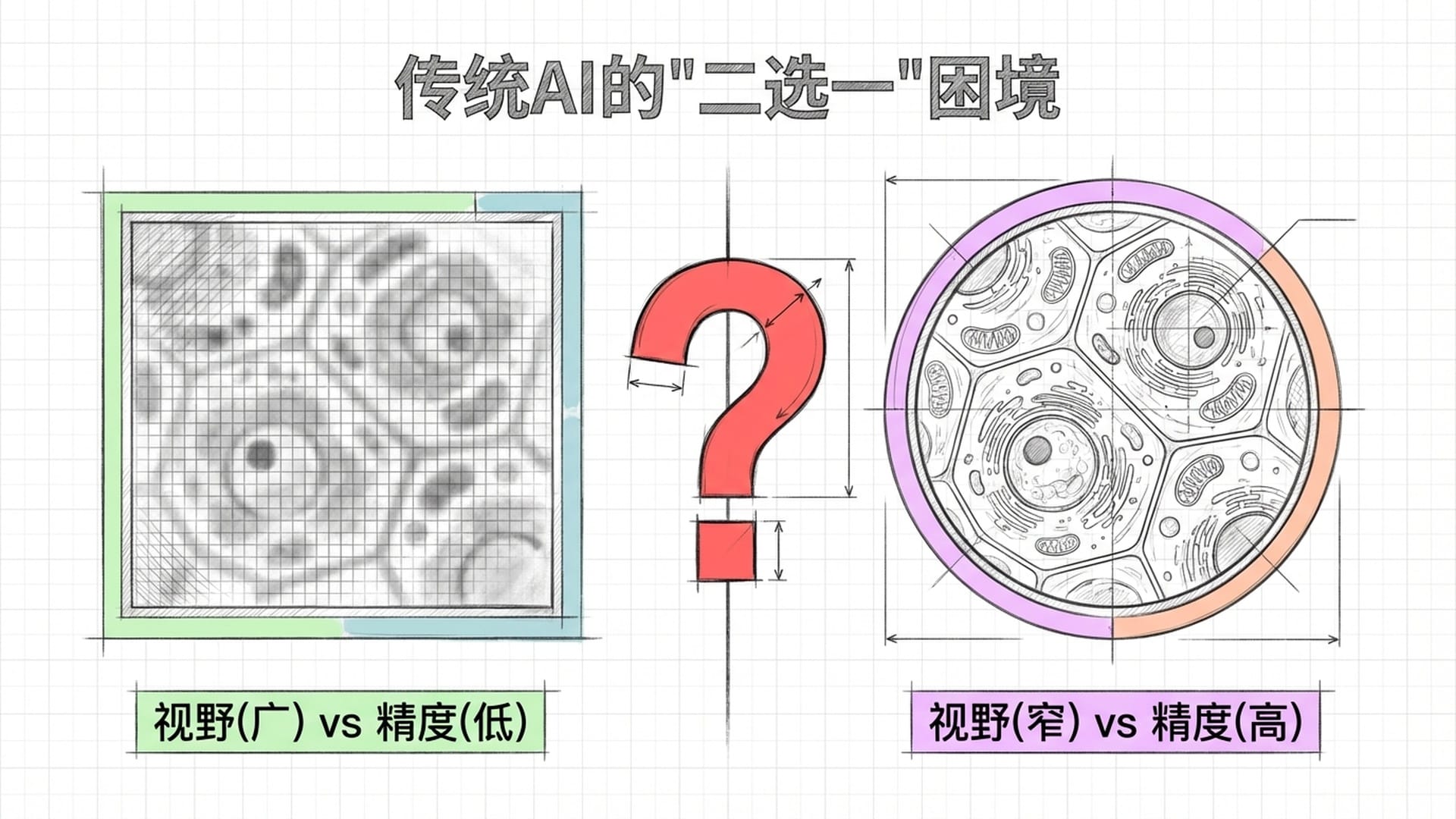
DeepMind曾推出的Enformer模型能识别长达20万个碱基对的序列,视野虽广,但分辨率仅为128个碱基对,细节模糊。这好比用480p摄像头拍摄广角照片,构图虽在,细节尽失。许多关键的单碱基突变,在这种分辨率下难以察觉。反之,SpliceAI等高分辨率模型虽能达到单碱基精度,其输入窗口却仅有数千个碱基,视野极窄。面对跨越数十万碱基的远程调控,这种模型便显得力不从心,如同“盲人摸象”。这就是长久以来困扰计算基因组学界的“视野与精度悖论”。
AlphaGenome的出现,一举打破了这一魔咒。其核心突破可总结为三个关键点:看得远、看得清、看得全。
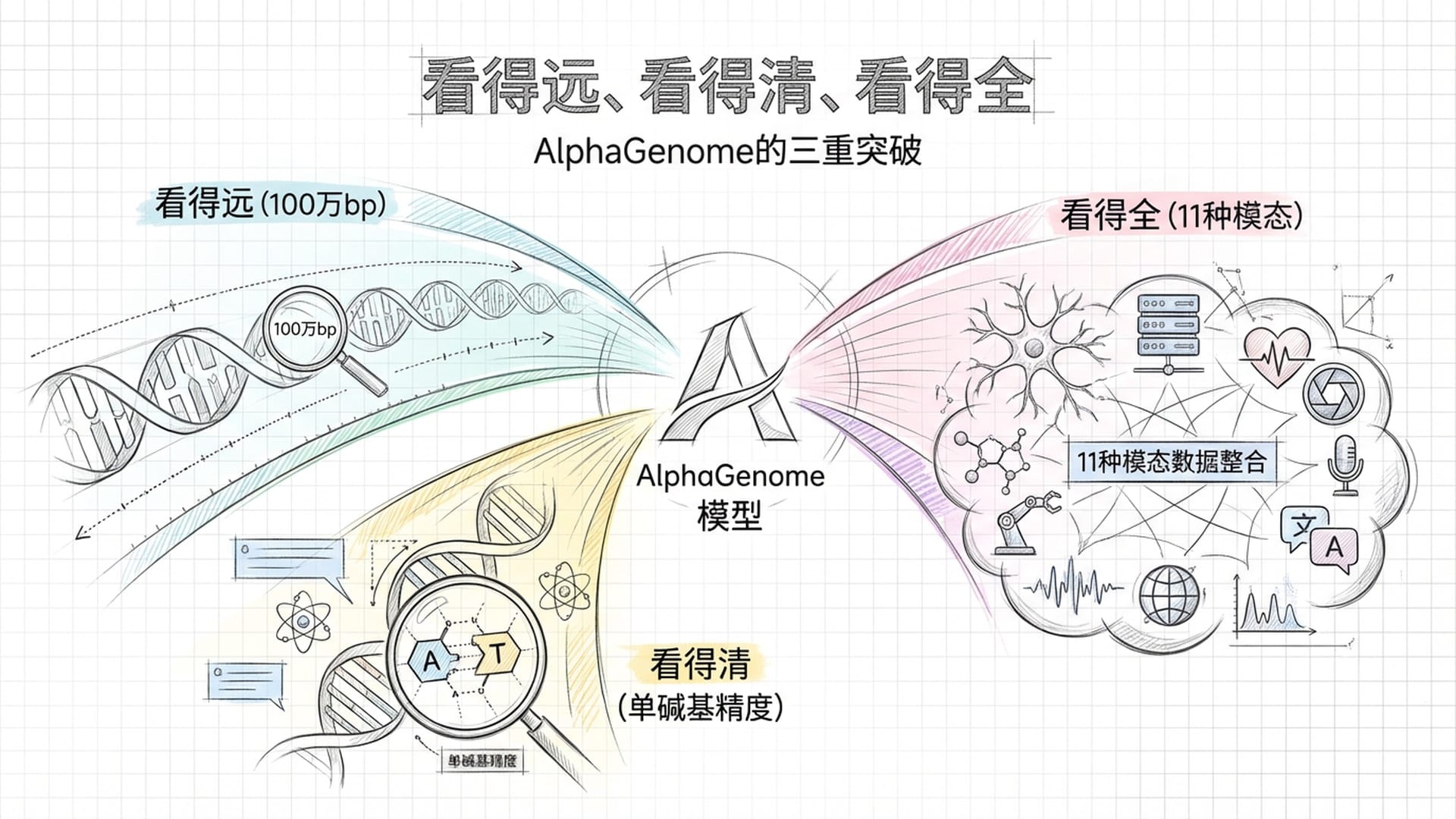
首先,看得远。AlphaGenome将输入窗口直接扩展至100万个碱基对,是Enformer的五倍。在如此广阔的视野下,绝大多数远端增强子与启动子之间的调控关系均能被纳入考量。
其次,看得清。在百万碱基的超大视野中,关键分子属性的预测分辨率实现了单碱基级别。这意味着,在百万字母序列中,它能精确指出某个特定位置上一个碱基的变化,如何引发下游的一系列复杂效应。这相当于同时拥有了IMAX银幕的广阔视角与电子显微镜的极致精度,彻底终结了“视野与精度”的二选一困境。
那么,AlphaGenome是如何做到这一点的呢?其架构设计极其精妙。
它采用了受图像分割领域U-Net启发开发的混合拓扑结构,深度融合了卷积神经网络(CNN)和Transformer模型。底层通过卷积网络快速扫描局部模式,识别DNA序列中转录因子结合基序这类短小精悍的特征。随后,通过逐步降采样,将百万长度的序列压缩为更紧凑、信息密度更高的高维特征表示。
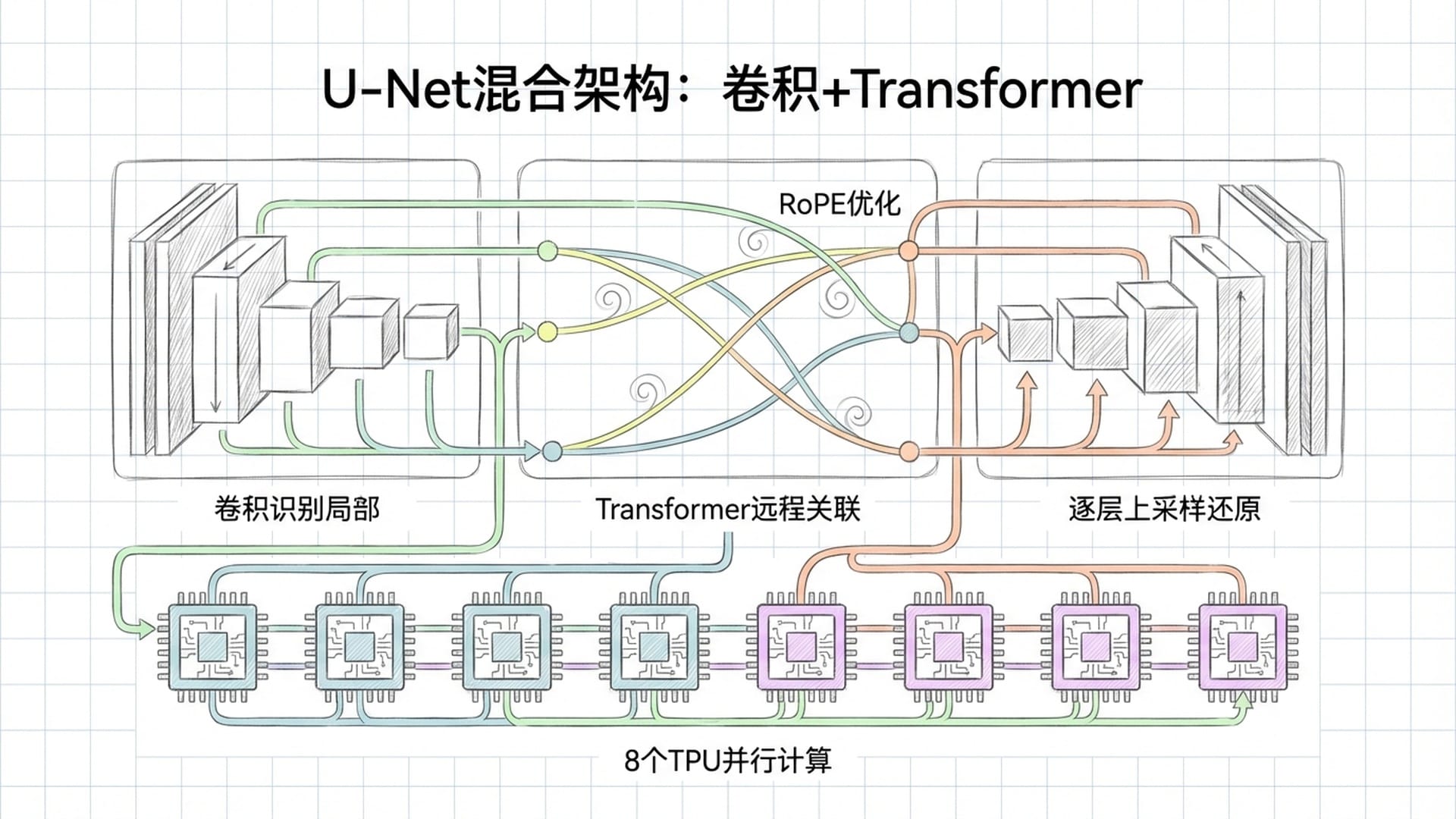
接着,Transformer模型登场,负责建立远程关联,使相距数十万个碱基的DNA片段能够“对话”。为克服标准Transformer注意力机制的计算复杂度难题,DeepMind优化了旋转位置编码(RoPE)的频率计算公式,使其能在不耗尽显存的前提下关注极远距离的依赖关系。最终,通过U-Net的解码器逐层上采样还原精度,将模糊的全景图锐化至单碱基级别。工程上,还利用序列并行技术将百万碱基序列切分成小块,分配到8个TPU上并行计算,成功突破了单张加速卡的物理极限。
再者,看得全。这是AlphaGenome最具颠覆性的一点。以往,预测染色质可及性、RNA剪接或基因表达,都需要训练各自独立的模型,科研人员需运行多套软件,结果往往难以整合。AlphaGenome实现了大一统,它覆盖了基因表达、转录起始、RNA剪接、染色质可及性、组蛋白修饰、转录因子结合、三维染色质构象等11种核心生物学模态,涵盖近六千条人类基因组学测量轨迹。只需一次API调用,即可获得所有维度的评估结果。这种“一个模型统治所有任务”的策略,与大语言模型(如GPT、Claude)的大一统思路异曲同工。
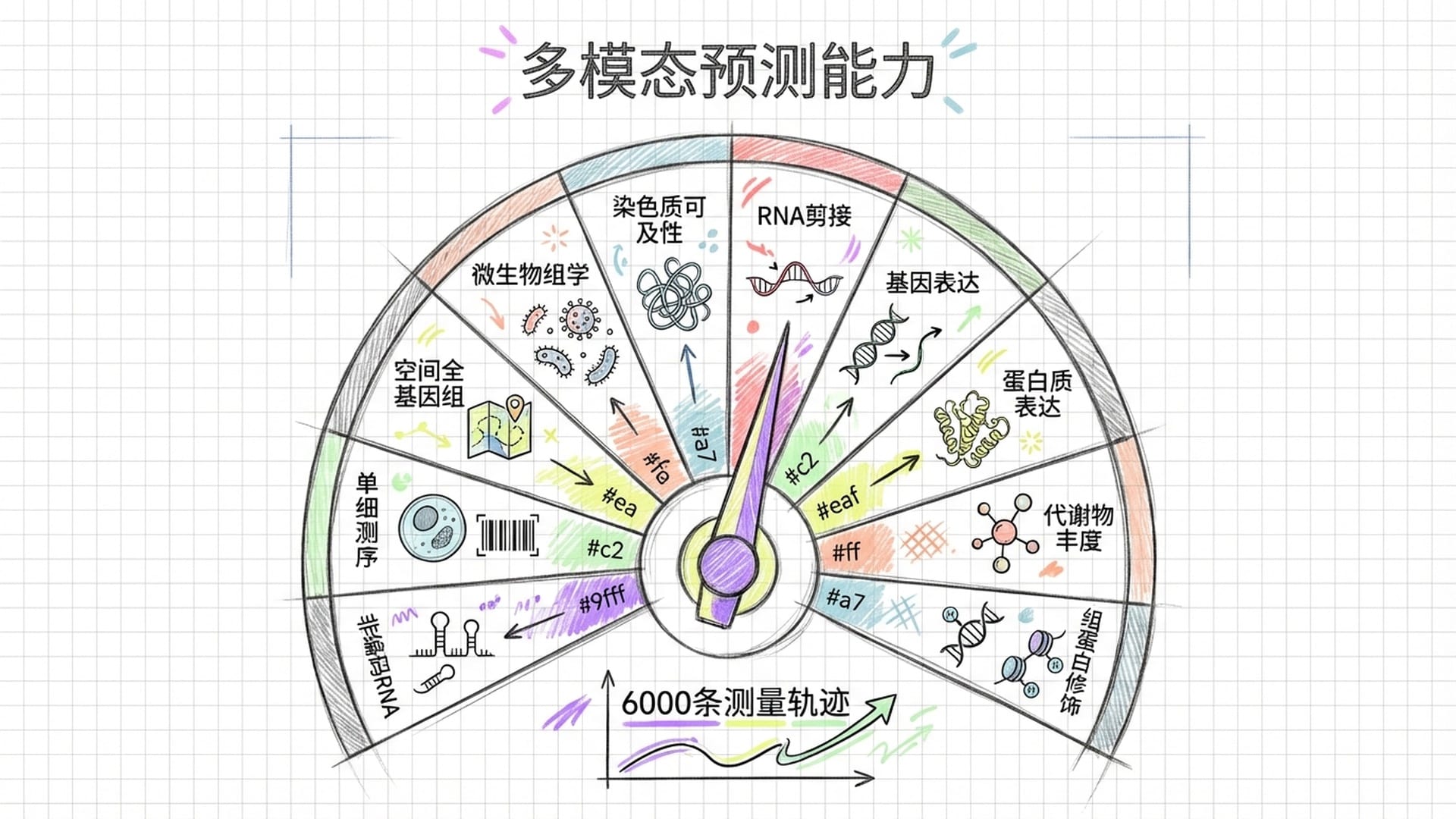
在这些模态中,最令学界振奋的是RNA剪接预测,因为它与许多罕见病的诊断直接相关。简单来说,基因转录出的原始RNA草稿需经过“剪辑”过程,剔除冗余的内含子,拼接所需外显子,才能翻译出正确的蛋白质。若剪接出错,便会产生异常蛋白质,引发疾病。AlphaGenome能直接从DNA序列预测不同组织中RNA剪接连接点的精确位置和强度,这是此前任何模型都无法做到的。
在工程层面,知识蒸馏的应用也殊为关键。DeepMind首先耗费13万个TPU小时训练出一个由64个模型组成的超级集成体作为“教师”。随后,通过知识蒸馏,一个独立的“学生”模型学习这64个教师模型的综合输出,整个蒸馏过程仅耗时4600个H100小时。蒸馏后的学生模型性能几乎无损,却只需一张H100显卡,一秒钟内即可完成一个变异在所有轨迹上的效应预测。从零训练完整模型也只需4小时,成本仅为当年Enformer的一半。这意味着全基因组级别、百万量级变异的高通量筛查,首次成为普通实验室也能实现的任务。
AlphaGenome交出的成绩单堪称亮眼:在24项基因组轨迹预测任务中,夺得22项世界第一;在更严苛的26项变异效应预测评估中,斩获25项世界第一。这并非微小领先,而是系统性的全面碾压。
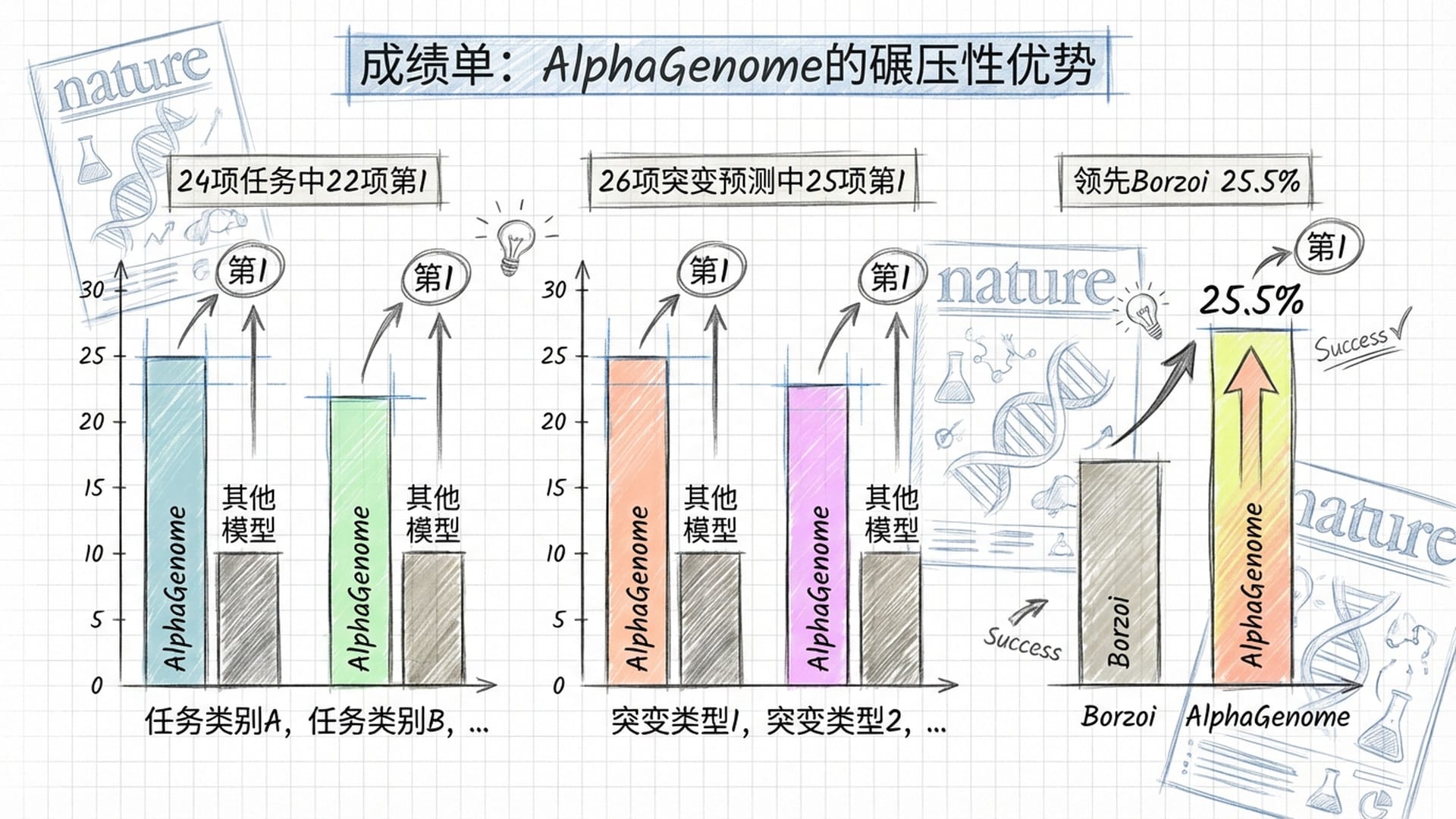
在区分因果eQTL(即从一系列高度关联的候选突变中找出真正的幕后黑手)方面,AlphaGenome结合多模态数据后达到了0.75的auROC,显著超越了此前的标杆Borzoi。在预测突变对基因表达上调或下调的方向性方面,它比Borzoi领先了25.5%。这种方向性在临床实践中至关重要,它直接决定了我们面对的是促癌还是抑癌。
然而,数字终归是数字,真正令人震撼的是AlphaGenome在实际生物学问题中的表现。我们来看三个真实案例。
首先是癌症。以T细胞急性淋巴细胞白血病为例,这种侵袭性血癌一直被发现与TAL1致癌基因附近的非编码区存在关联,但具体机制不明。AlphaGenome通过分析患者基因组序列,不仅定位了非编码区的一个微小突变,更完整地重构了致病链条:该突变凭空创造了一个MYB转录因子的结合位点,触发了表观遗传学的雪崩效应——活性增强子标记H3K27ac异常飙升,抑制性异染色质标记脱落,最终导致TAL1基因被病理性地疯狂激活。
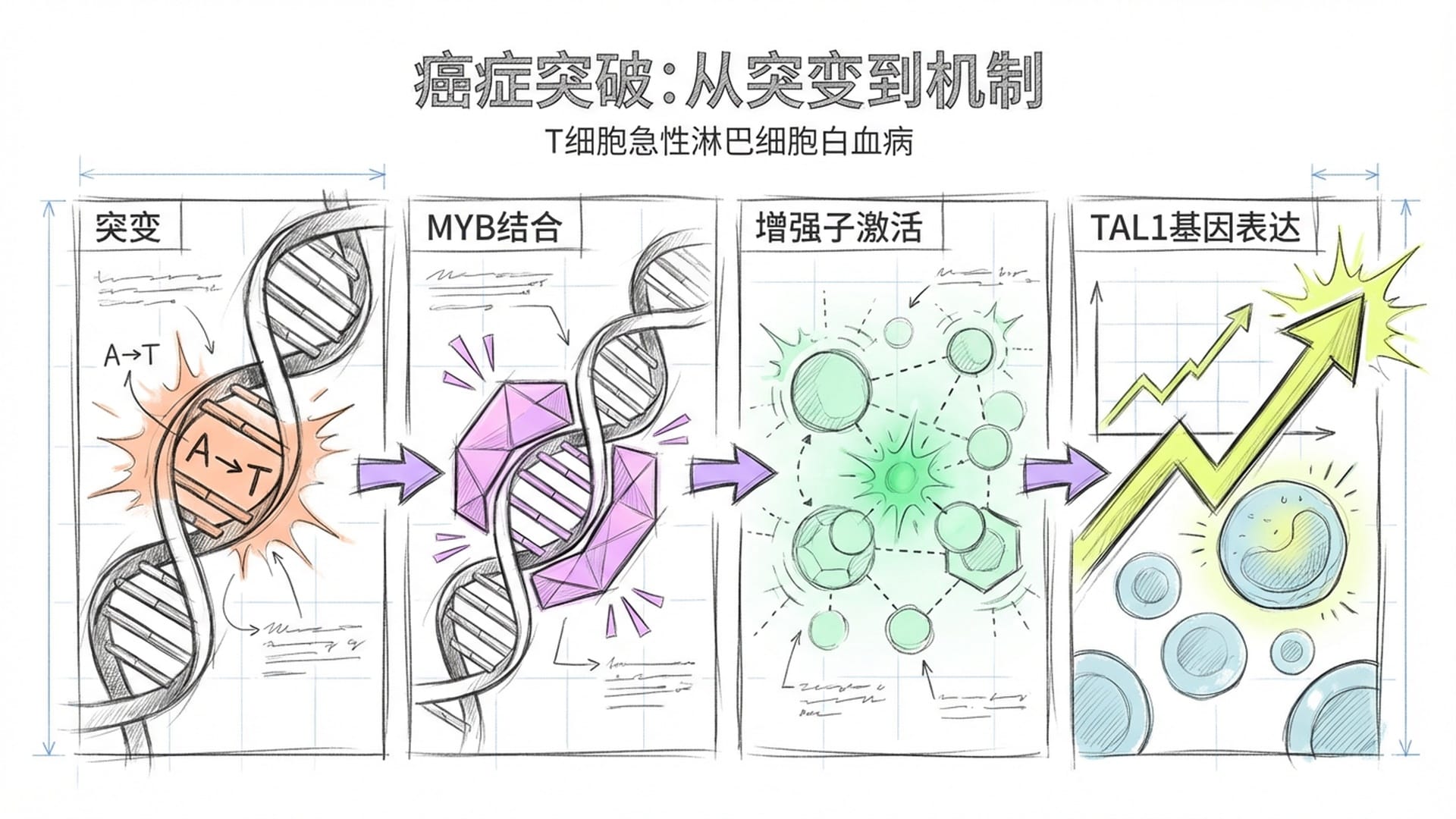
从一个碱基的变化到整条致癌通路的完整因果还原,全部由模型在计算层面推演得出。伦敦大学学院癌症专家Marc Mansour教授指出,这为大规模解析非编码变异如何驱动癌症提供了最关键的拼图。以往需要多个实验室耗时数年才能完成的机制解析,如今在电脑上数分钟即可实现。
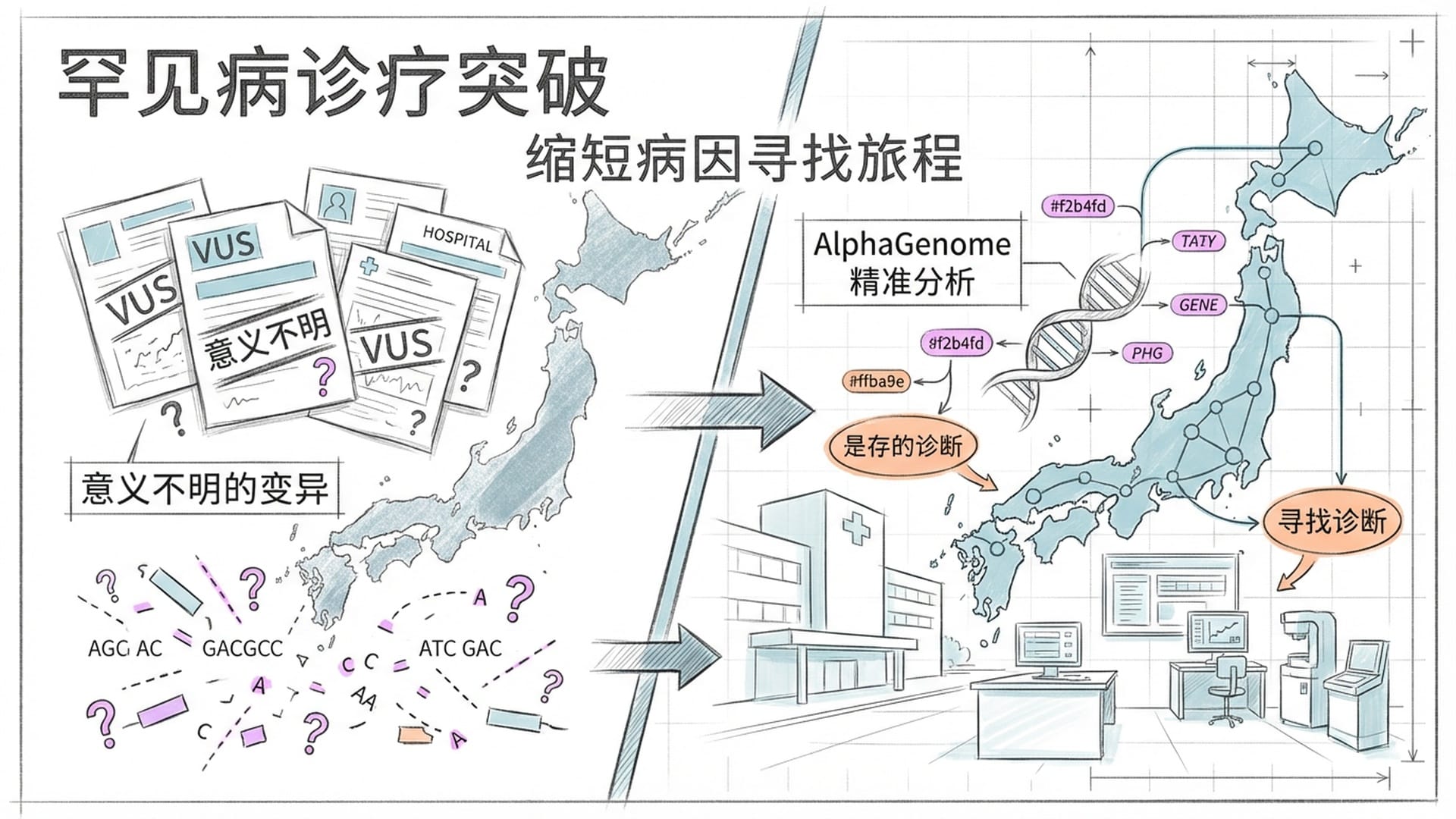
其次是罕见病。全球范围内,许多家庭带着患有严重发育迟缓或先天缺陷的孩子进行全基因组测序,却只得到一堆“意义不明”的报告。这些致病变异很多隐藏在非编码区,它们并非直接破坏蛋白质,而是扰乱了RNA的剪接逻辑,导致外显子异常跳跃或内含子错误保留。凭借其卓越的剪接预测能力,AlphaGenome能精准地对这些VUS进行“计算分诊”——将数万个不确定的变异筛选至寥寥数个最可疑的,并能解释具体机制。日本国家级的“未诊断疾病倡议”项目已将AlphaGenome整合进常规分析流程,用于重新筛查过去十年中那些悬而未决的疑难病例。这种“计算分诊”能力,正大幅缩短罕见病患者寻找病因的漫长旅程。
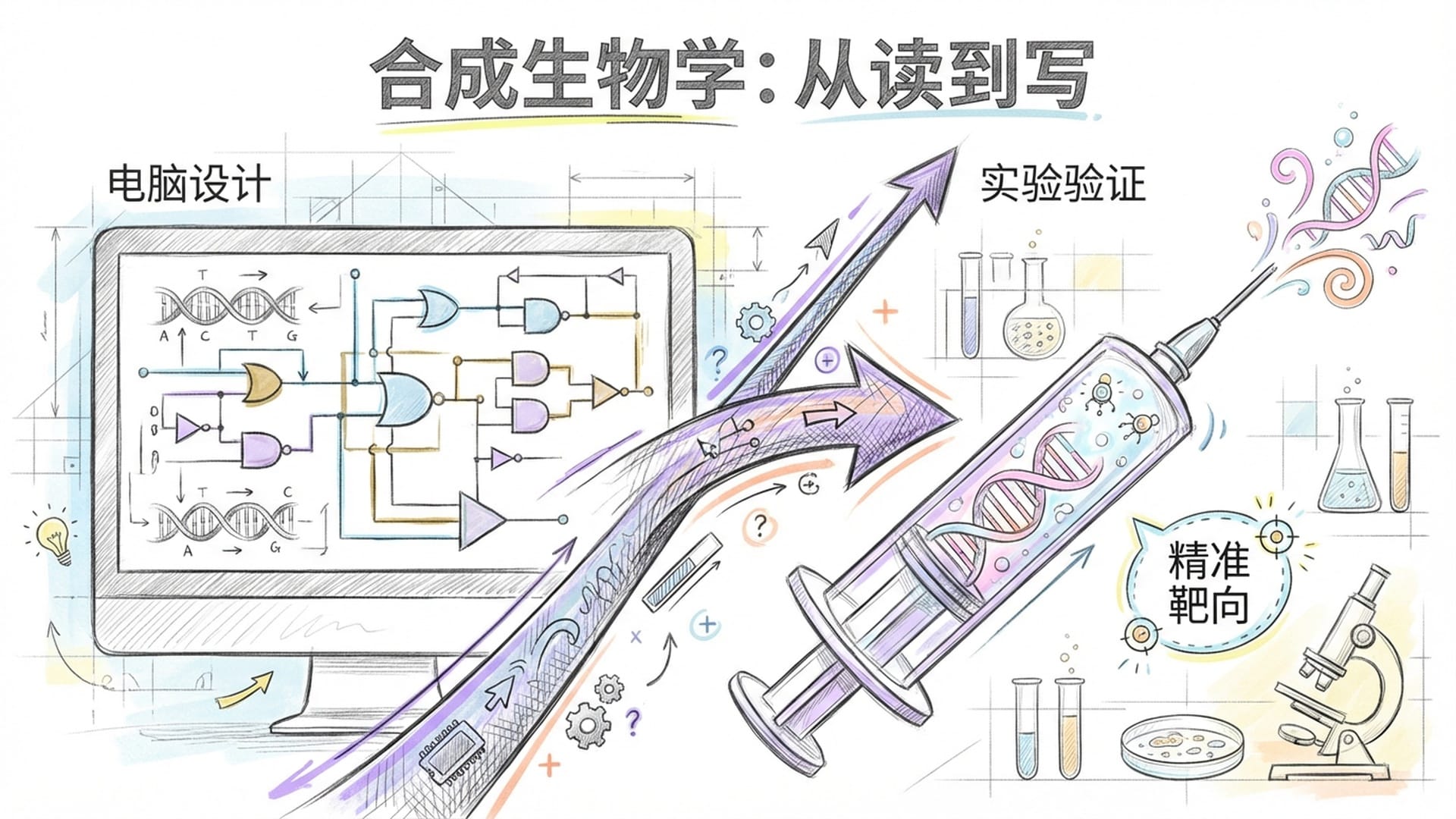
最后,也是最令人兴奋的一点——合成生物学,即从“读”生命到“写”生命。基因治疗面临的一大挑战是确保治疗基因只在特定靶细胞中表达,避免在其他部位“泄漏”。传统方法是盲目试错。如今,凭借AlphaGenome,合成生物学家可在电脑中设计数千种虚拟增强子序列,让模型评估哪条序列能使基因“只在受损神经元中高表达,而在肌肉细胞中保持沉默”。找到最优解后再进行实验验证。这好比建筑行业从“边盖边改”进化到“先在BIM软件中模拟再施工”。生命科学正在从经验驱动迈向计算驱动。在核酸药物领域,它还能加速反义寡核苷酸药物的设计迭代,大幅减少临床前阶段的盲目动物实验。通过对整个基因组调控网络的系统级模拟,制药企业甚至有望在药物立项早期阶段就前瞻性地规避脱靶毒性风险。
尽管AlphaGenome成就斐然,我们仍需清醒认识其局限性。
尽管AlphaGenome的窗口大小已达100万碱基,为史上最长,但人类基因组中确实存在跨越数百万碱基的超远程调控关系,这仍是模型目前无法完全覆盖的盲区。
此外,模型在预测“肝脏对比大脑”这类组织间差异时表现精准,但在预测由复杂遗传组合导致的个体间细微差异时,精度会显著下降。因为个体基因表达受上位效应、环境暴露、反式作用因子等诸多变量影响,纯序列模型尚无法触及。再者,模型主要基于健康组织测序数据训练,未来需融合大量单细胞和空间转录组数据以弥补在病理状态下稀有细胞类型行为建模上的短板。最后,AI幻觉的风险不容忽视,在HLA区域、着丝粒附近等结构复杂的区域,模型的泛化能力仍需严格验证。宾夕法尼亚大学的Adam Naj教授明确警告:未经实验验证的AI预测,不可视为真理。
因此,当前阶段,AlphaGenome最准确的定位不是“替代实验的真理机器”,而是一个极其强大的“实验分诊系统”——它能帮助科研人员从海量候选变异中,精准定位那些最值得投入资源去验证的少数几个。
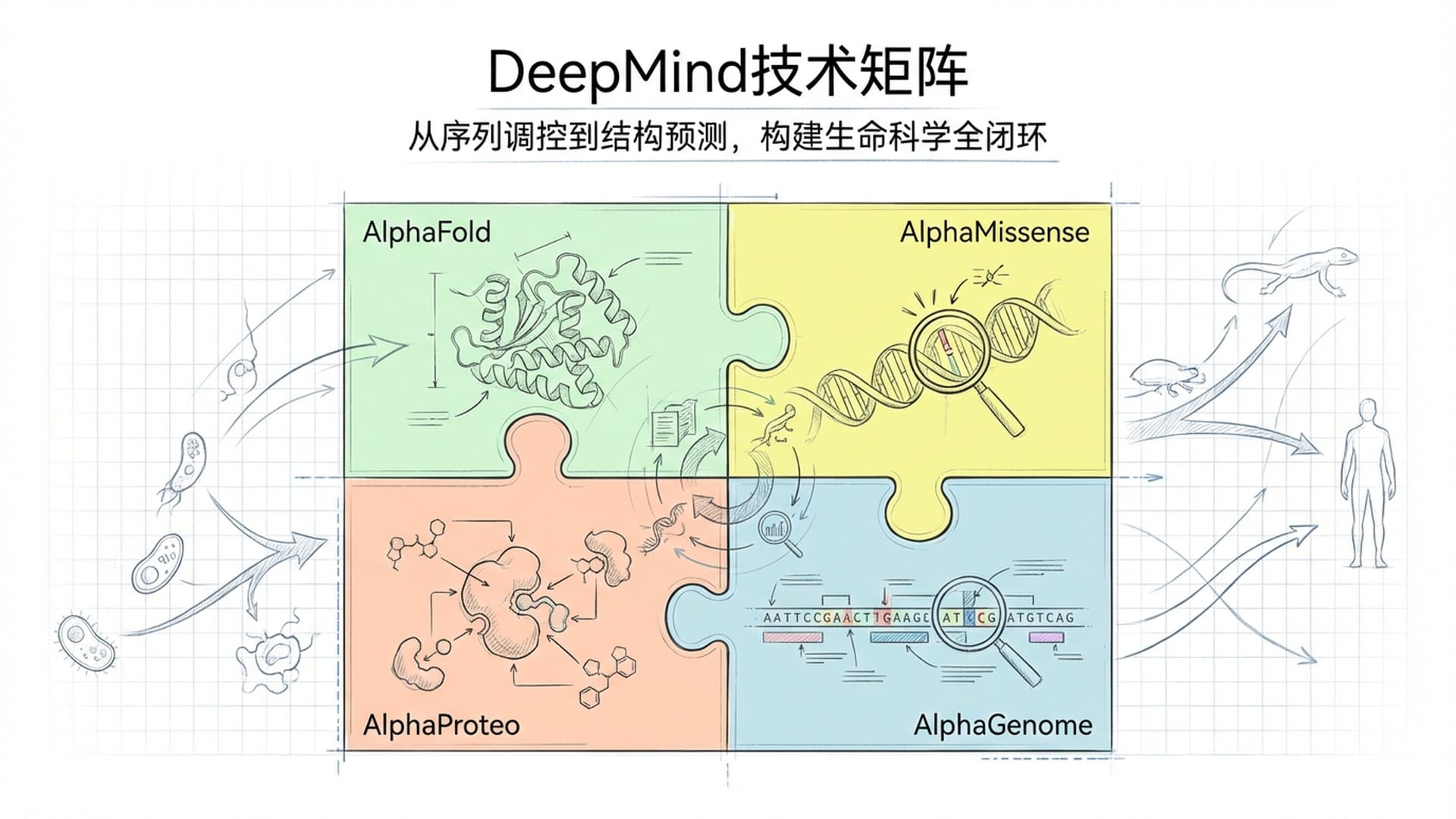
从投资人的视角来看,AlphaGenome的问世,其意义远不止于一个单一产品的突破。它与AlphaFold、AlphaMissense、AlphaProteo共同构成了DeepMind在生命科学领域完整的技术矩阵:从一维DNA序列的调控解读,到蛋白质三维结构预测,再到编码区错义突变的致病性分类,乃至于蛋白质互作设计——这正勾勒出一条从DNA到蛋白质功能的完整认知闭环,并以前所未有的速度不断合拢。
这对产业意味着三条清晰的链条:
首先是计算基因组学SaaS平台。AlphaGenome虽已开源,但将其转化为临床可用的产品尚有巨大的工程化空间。谁能实现良好封装、自动化临床报告生成、合规性,谁就能抓住这波红利。
其次是AI驱动的合成生物学设计平台。“在电脑中设计调控元件”将催生一批全新的工具公司。传统基因治疗公司若不拥抱这一范式,将在效率上被碾压。
第三是精准医疗的下一跳。当非编码区变异能被系统性解读,罕见病诊断率将实现质的提升,非编码区驱动的癌症亚型也将被精准识别。这对伴随诊断和靶向治疗均构成巨大利好。
值得一提的是效率之争。一款名为Enigma的轻量级模型,以不到AlphaGenome一半的参数和约7.5%的算力,实现了其90%以上的性能。这再次印证了AI行业的普遍规律:大力出奇迹是上限探索的路径,而巧力出普惠才是商业化成功的关键。未来能脱颖而出的公司,未必是算力最强的,而是那些在精度和效率之间找到最佳平衡点的企业。
在AI时代做投资,我们必须清晰地认知哪些领域的认知护城河正在被AI系统性地攻破。AlphaFold攻克了蛋白质结构预测的认知壁垒,而AlphaGenome则正在攻破基因组98%“暗物质”的认知壁垒。
当这两堵高墙同时倒塌,生命科学将从“观察和关联”时代,不可逆转地步入“计算和编程”时代。德米斯·哈萨比斯曾预言,未来十年,AI有望成为人类治愈所有已知疾病的最强武器。这究竟是宏大的野心,还是正在兑现的预言?
我更倾向于后者。当AlphaGenome使我们首次真正读懂基因组98%的“暗物质”,当我们从被动认知生命转向主动编程生命,这个未来已不再是科幻,而是触手可及的现实。世界上最深奥的密码不在任何保险箱里,它就写在你每一个细胞的细胞核中。三十亿个字母,我们曾只理解其中2%,现在AI正在帮助我们翻开剩下的篇章。故事才刚刚开始。