

大模型的核心“脊梁”:濒临断裂还是重塑新生?
你是否曾想过,我们日常接触的大模型,其内部运作的“骨架”可能正面临崩溃的边缘?更令人惊讶的是,中国AI正以一种颠覆性的方式,不仅修复这根“骨头”,甚至在重塑其形态。今天,我们将深入探讨一项硬核技术——mHC,它可能正是决定未来大模型“智商”上限的关键。
“残差连接”的辉煌与瓶颈
在过去十年里,深度学习取得了举世瞩目的成就,从简单的图像识别到如今能够吟诗作画的大语言模型,其背后都离不开一个共同的基石——残差连接(Residual Connection)。它被誉为神经网络的“脊梁骨”,核心作用是确保信息在网络中无损、高效地传递。
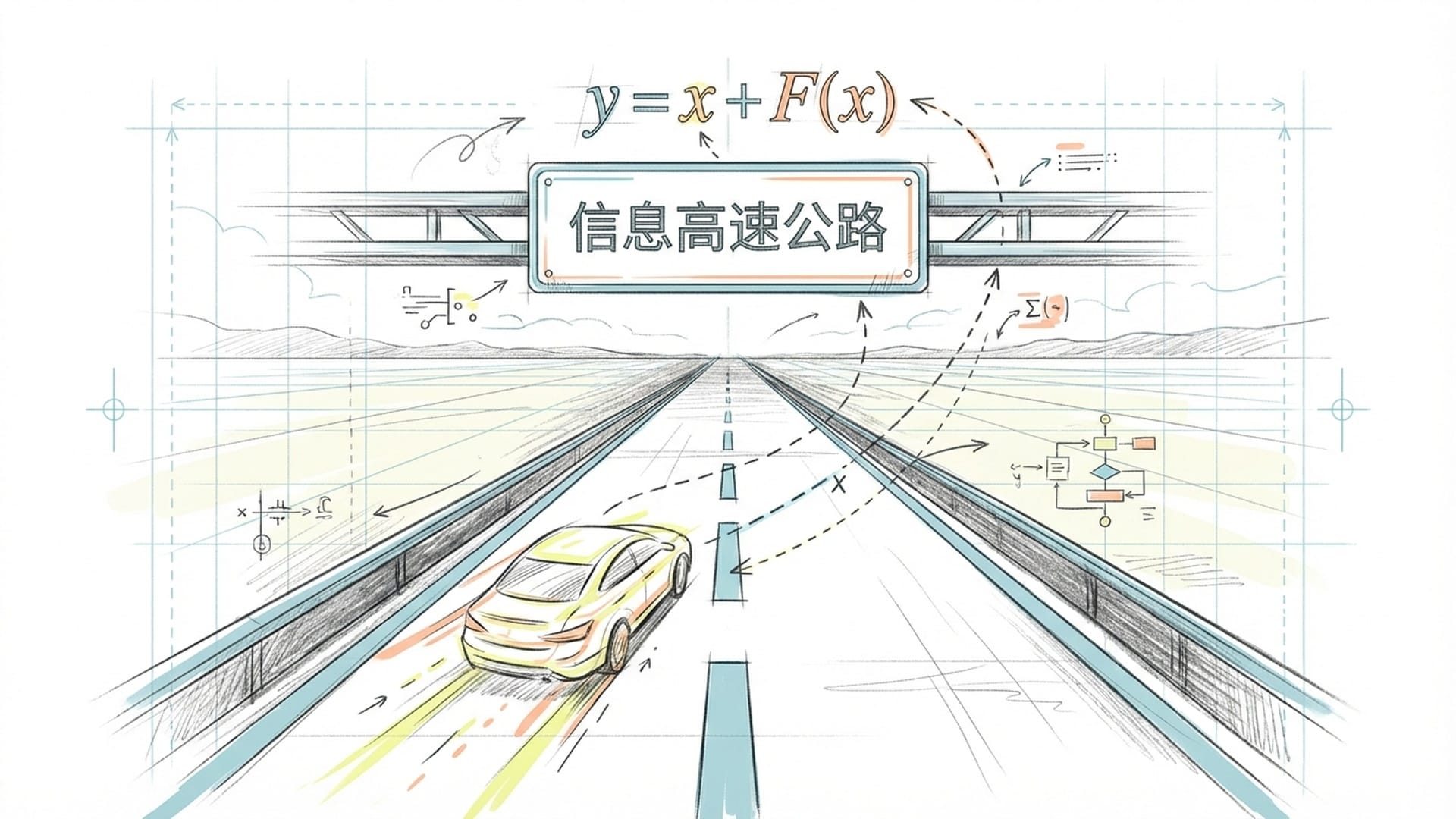
残差连接的原理简洁而强大,用公式表达便是 Y = X + F(X)。这个看似简单的等式,保证了信息流在网络的深层传递中既不被过度放大,也不至于衰减消失,维持了一种**“恒等映射”**的状态。这就像一条畅通无阻的“信息高速公路”,确保信号能稳健地从网络的一端传递到另一端。如果这条“公路”发生堵塞,信息无法顺畅流通,再深再复杂的模型也只会沦为“数字垃圾”。
然而,随着模型规模的不断膨胀,层数越来越深,参数量飙升至万亿级别,这条单一的“信息高速公路”开始显得力不从心。它就像一条单车道高速公路,尽管有严格限速,面对日益增长的车流量,终将不堪重负,走向拥堵。
面对这一挑战,科学家们自然而然地思考:“既然一条路不够用,那我多修几条路不就行了吗?” 这便是**“超连接”(Hyper-Connections, 简称HC)思想的萌芽。其目标是将单一的残差流拓宽为多条并行的信息流**,让信息能够“兵分几路”,从而理论上大幅提升信息传递效率和模型的表达能力。
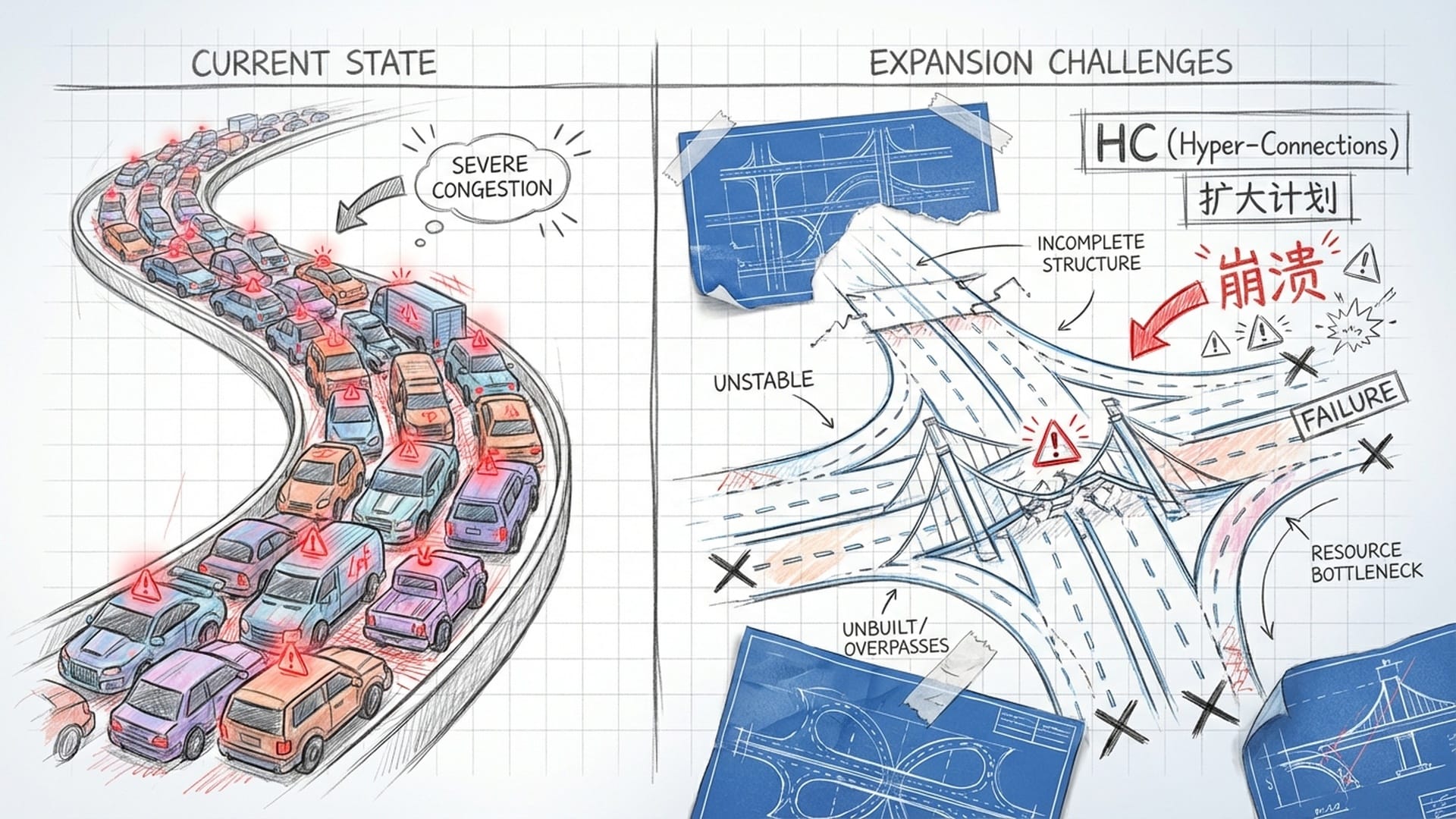
“超连接”的陷阱:稳定性的丧失
想法很美好,现实却很骨感。在实际应用中,“超连接”几乎立刻“暴雷”,表现出训练极其不稳定的特性,频繁出现报错乃至模型崩溃,简直是灾难现场。
你可能会疑惑,多条信息通道难道不是更强大吗?问题恰恰在于,这种无约束的“超连接”破坏了残差连接最核心的“恒等映射”属性。
“多车道固然诱人,但如果路面崎岖不平,车辆随时可能失控。无约束的超连接,正是如此,它让信息流在深层网络中变得不可预测,要么指数级爆炸,要么彻底衰减。”
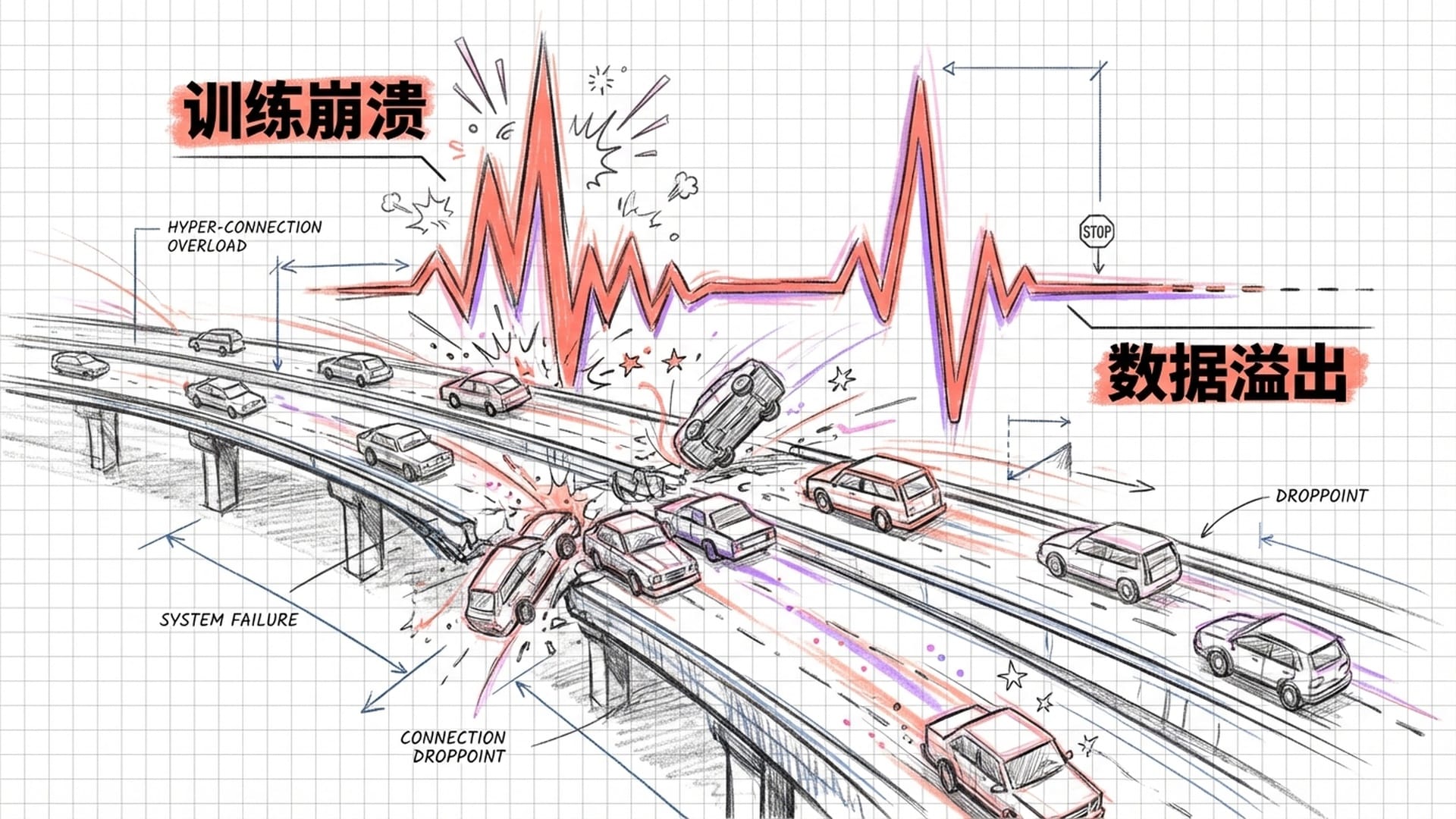
在数学上,这意味着信号要么呈指数级爆炸,直接“炸飞”模型,要么衰减消失,让模型彻底变成“榆木脑袋”。想象一下,投入数千万乃至上亿元的资金,动用上万块GPU训练一个大模型,却因为结构不稳定,时不时就遭遇**“数据溢出”或“梯度消失”**,前功尽弃,这无疑是巨大的资源浪费。因此,尽管“超连接”理论上颇具吸引力,但在工程实践中,它几乎就是一个难以填补的“坑”。
这正是 mHC(ManiFold-Constrained Hyper-Connections)技术试图解决的核心难题:我们能否在享受“多车道”优势的同时,依然确保“路面”的平稳,让信息流既宽阔又稳定?
DeepSeek的解决方案:流形约束超连接 (mHC)
DeepSeek团队给出了肯定的答案:“我们能!” 他们提出的流形约束超连接(mHC),并非简单的修修补补,而是一场从数学原理到系统工程的**“大革命”**。
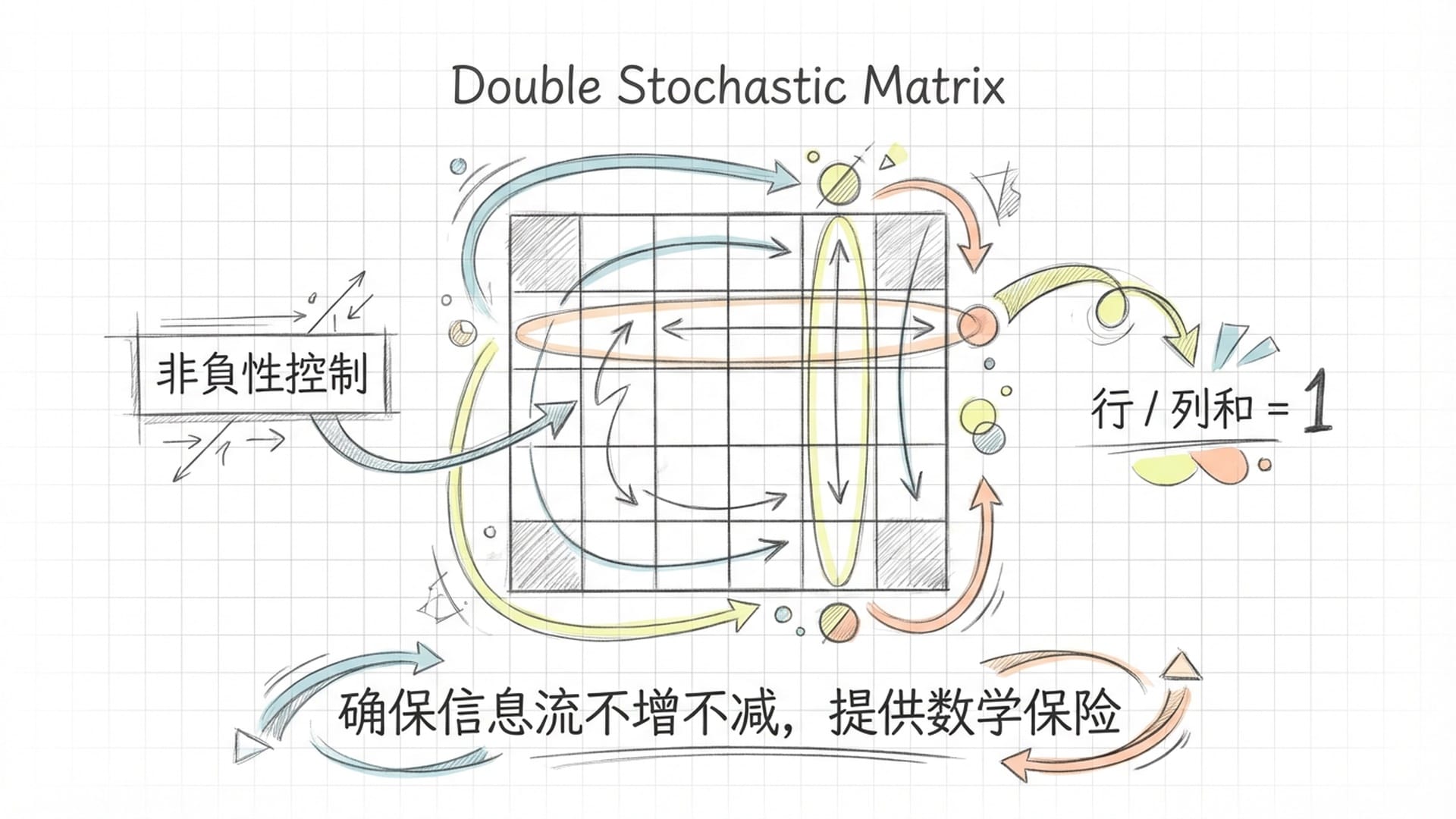
他们的解决方案便是引入了“流形约束”。通俗来说,就是将那些不听话、容易导致模型崩溃的“超连接”矩阵,强制性地“按”到一个数学上特别规整、特别稳定的“几何多边形”上。这个多边形,就是由**“双随机矩阵”**所组成的 “Birkhoff 多胞体”。
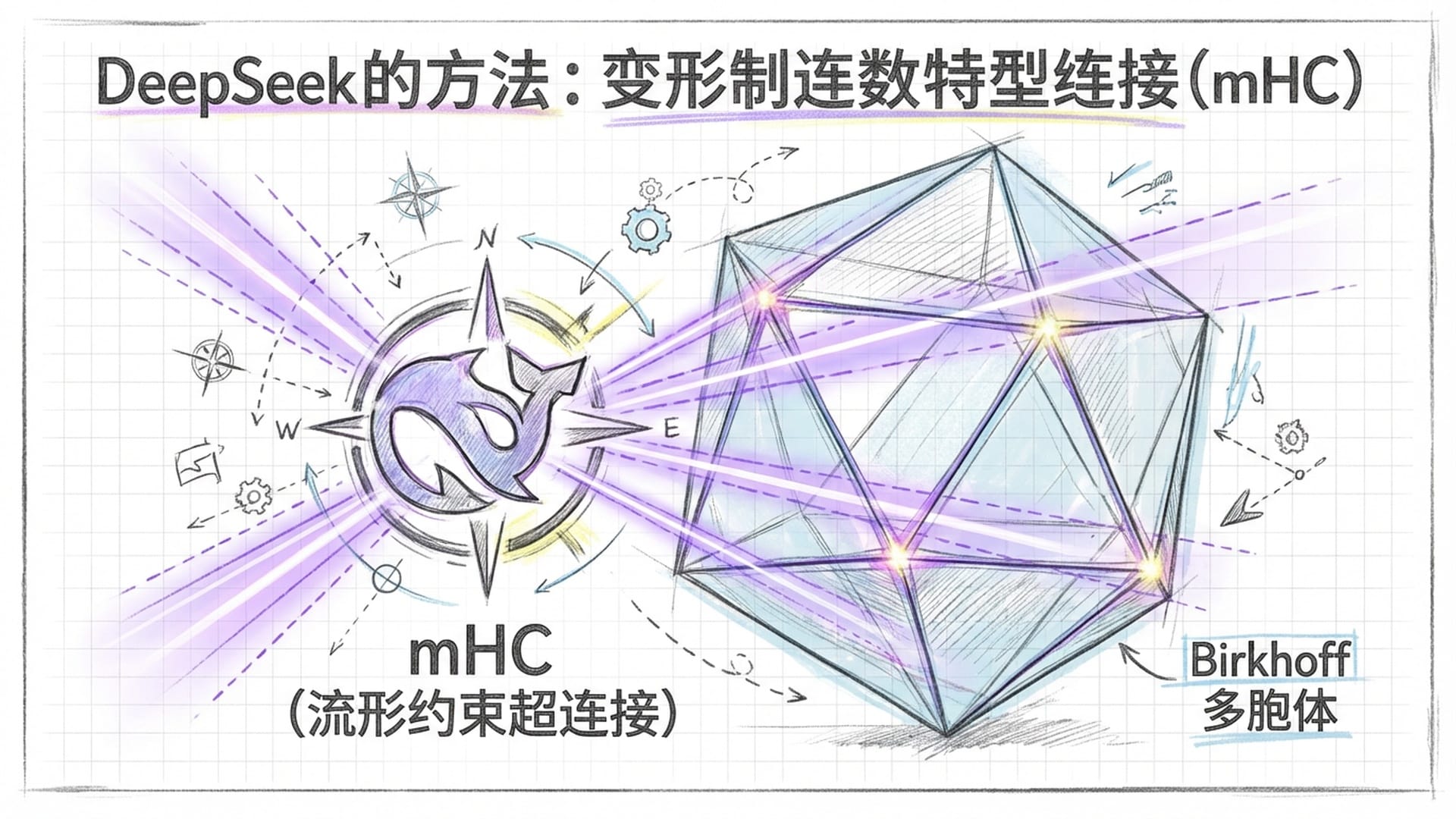
你或许会对“双随机矩阵”和“Birkhoff 多胞体”感到陌生,但无需深入复杂的数学公式,只需理解其三个核心特征:
- 非负性:矩阵中的所有数字都是非负的,好比信息流不能有“负”的速度或负的能量。
- 行和为1:每行元素的加和等于1,这保证了信息总量在传递中不增不减。
- 列和为1:每列元素的加和也等于1,确保了信息的均衡分配。
为何选择这种矩阵?因为它们能从根本上确保信息在传递过程中不会被指数级放大到爆炸,也不会缩小到消失。所有的信号,无论经过多少次混合,其整体幅度都有一个明确的“天花板”,像为信息流上了**“保险”,永远不会“超速失控”。这相当于将原来崎岖不平的道路,改造成了平坦、安全且富有弹性保障的康庄大道**,信息在其中被**“混合吸收”**而非凭空“创造”或“摧毁”。因此,即便网络再深、结构再复杂,信息的安全流动也得到了最根本的数学保障。
工程挑战与“暴力美学”的实现
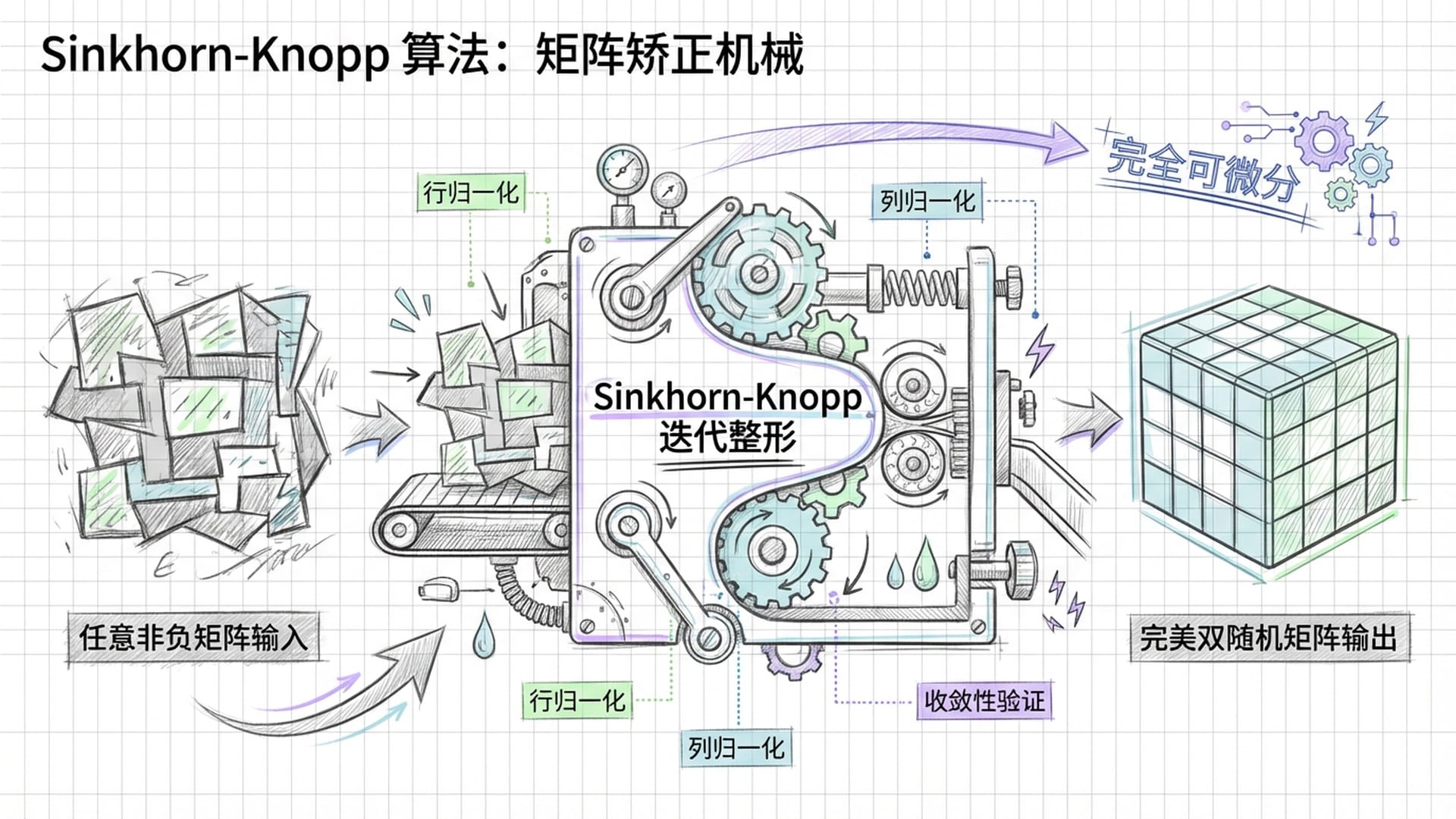
找到这个理想的“流形”只是第一步,下一个巨大挑战是如何在模型训练过程中,强制性地让这些“超连接”矩阵始终保持在这个安全的“多边形”里。如果直接采用复杂的数学投影方法,计算量将过于庞大,根本无法实际运行。
DeepSeek团队展现了他们的智慧,引入了 “Sinkhorn-Knopp”算法。你可以将其想象为一个**“整形器”:它能将任何一个“歪瓜裂枣”的非负矩阵,经过几轮迭代“整形”后,转化成一个几乎完美的“双随机矩阵”。更关键的是,这个“整形器”是完全可微分的**,这意味着模型可以通过反向传播,自适应地调整“整形”参数,以达到最佳的信息混合效果。
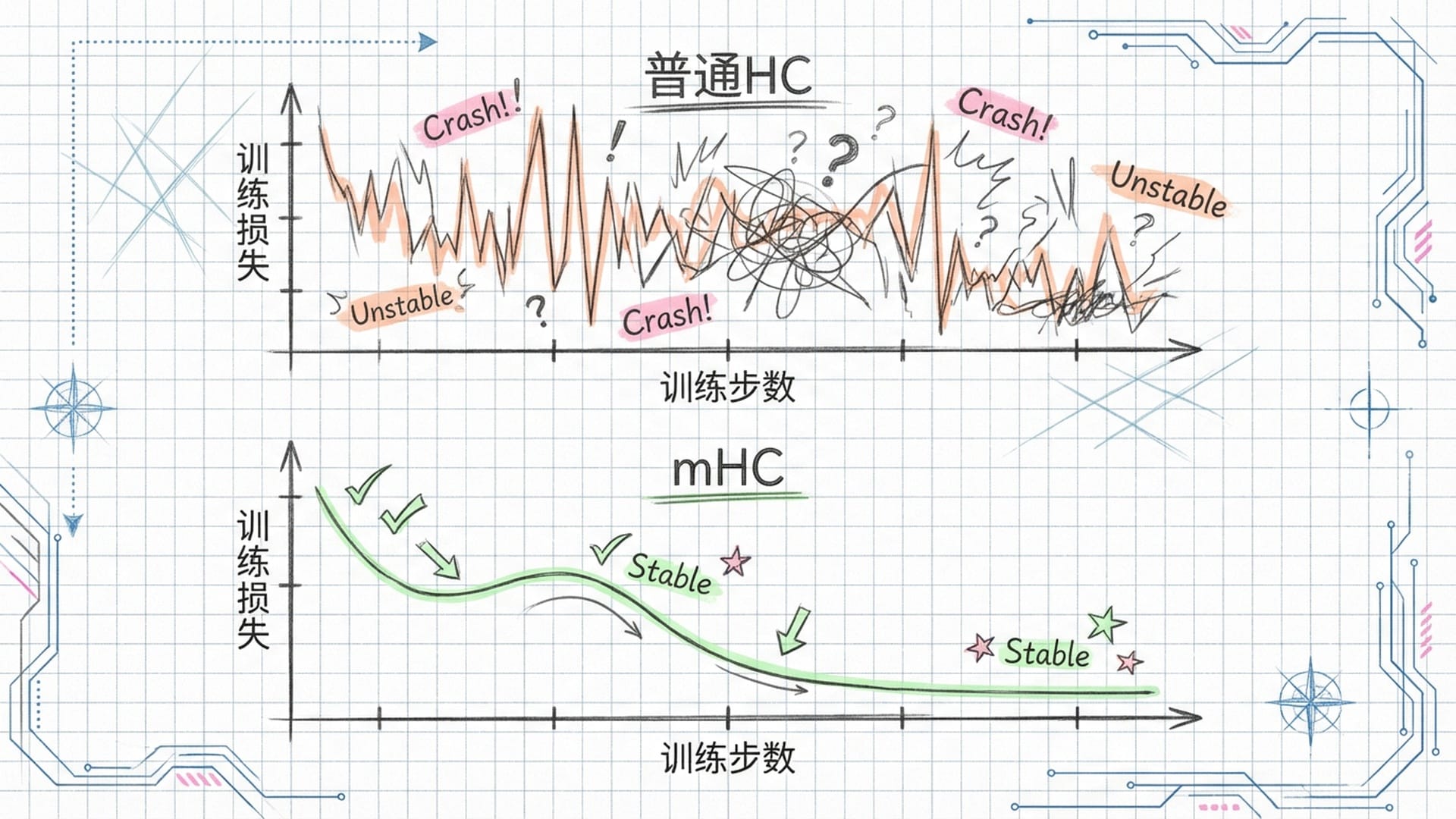
“mHC的精妙之处在于,它用数学的严谨性‘抢救’了残差连接的核心属性,确保了反向传播时误差信号的稳健传递,彻底消除了训练时常见的那种突发性‘Loss尖峰’。”
实验数据也印证了这一点:普通HC模型在训练中经常出现的**“Loss尖峰”(预示模型崩溃),在mHC模型中平滑得像一条直线**,几乎与最稳定的ResNet模型无异。这表明mHC在享受宽通道带来的强大表达能力的同时,并未牺牲任何稳定性,完美兼顾了广度与深度。
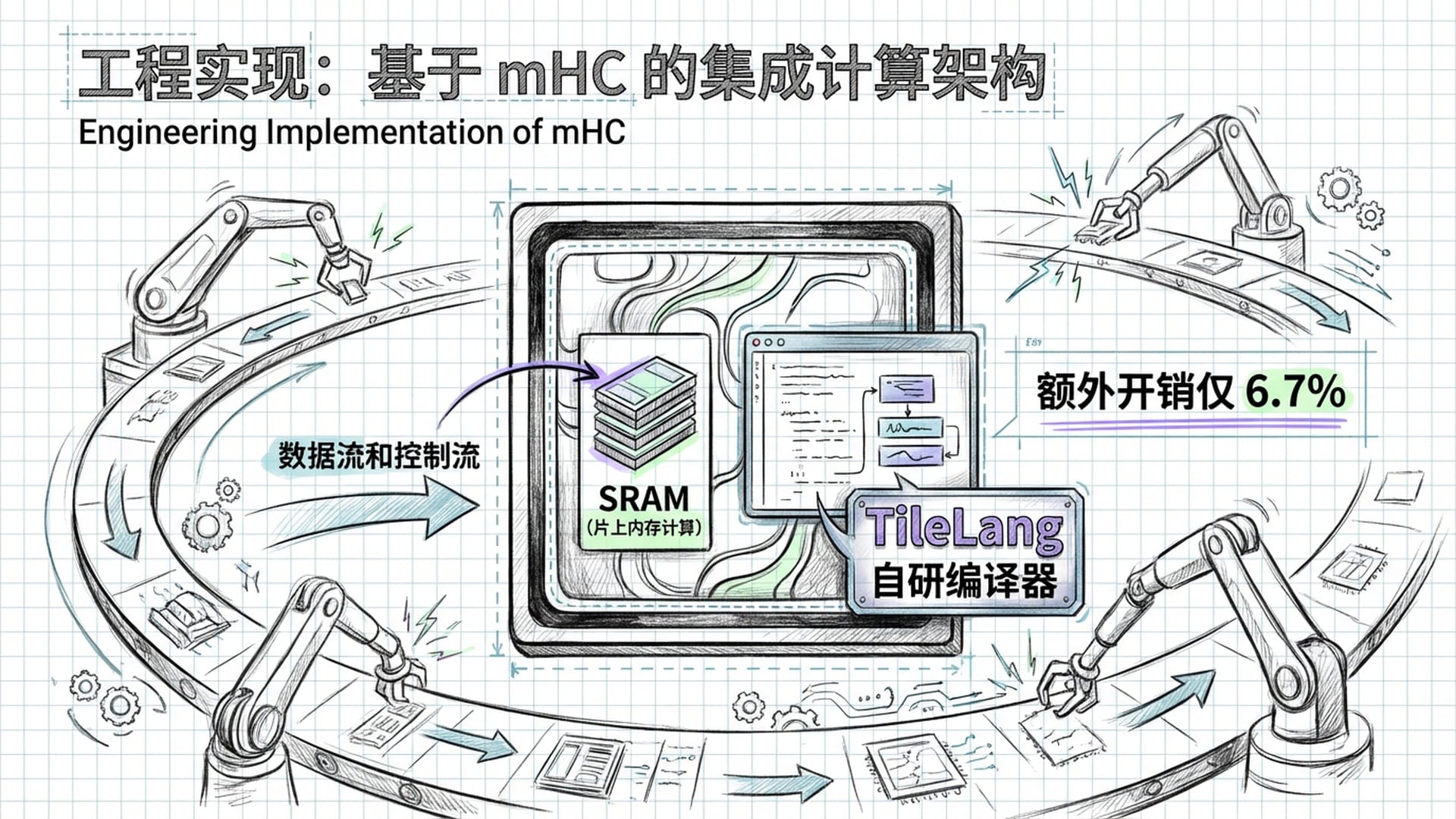
然而,如果仅仅是理论上的优雅,mHC也只能停留在论文层面。真正让mHC**“横空出世”的,是其工程实现的“暴力美学”。将残差流拓宽4倍,理论上显存占用和内存访问次数也会增加4倍。在GPU计算能力不断提升的同时,显存带宽却日益成为瓶颈,即所谓的“内存墙”**。如果直接这么做,训练速度将断崖式下跌,甚至无法运行。
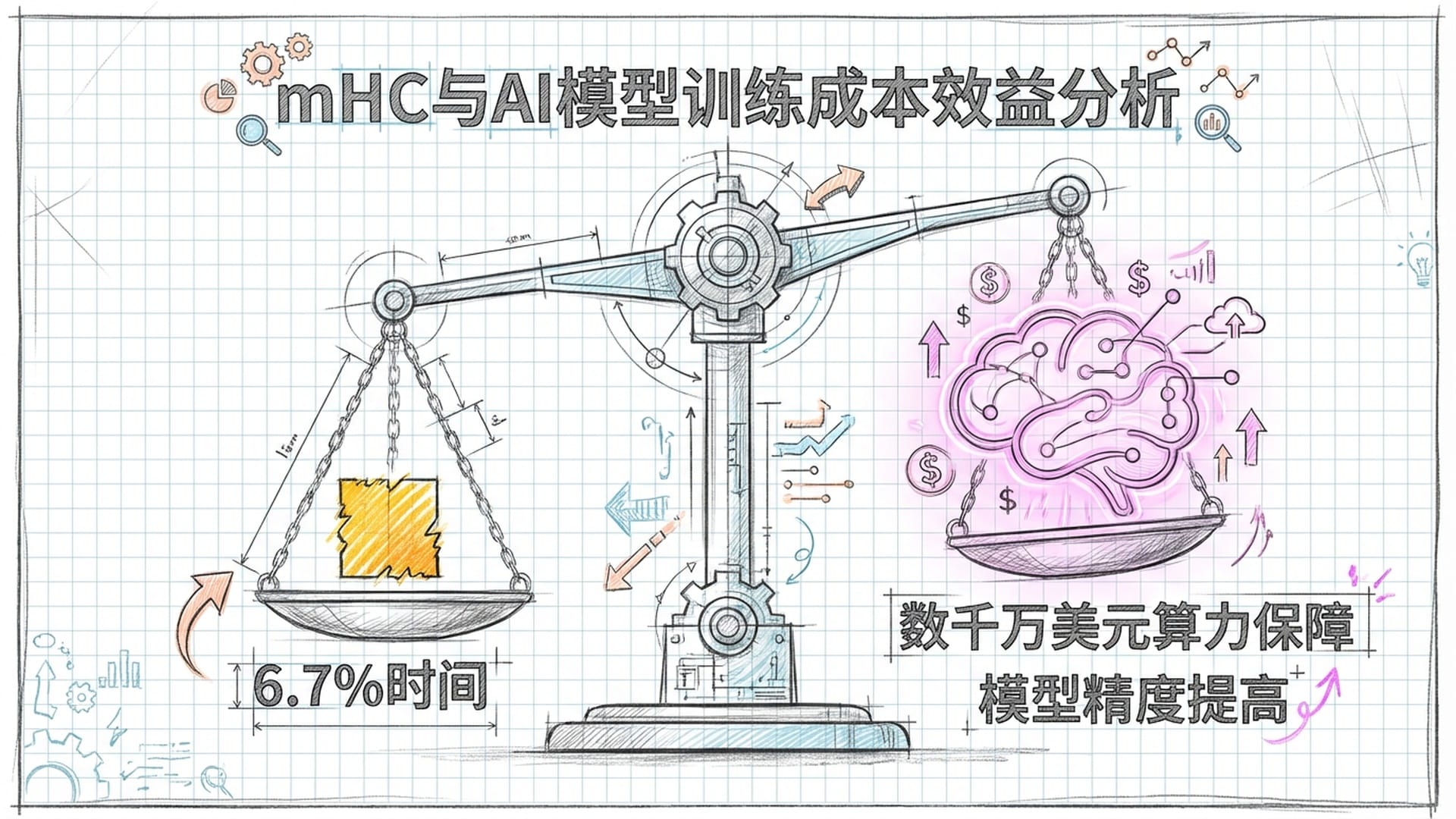
然而,DeepSeek的工程团队通过一系列底层的极致优化,硬是将mHC的训练额外开销控制在了惊人的6.7%!这好比你修了一条四车道高速公路,却只比原来的单车道多花了不到7%的钱,这简直是逆天操作。
他们是如何做到的呢?
- TileLang 和算子融合 Sinkhorn算法涉及大量数学运算(指数、求和、除法等)。传统深度学习框架若对这些操作进行多次GPU内核启动,将导致数据频繁进出显存,浪费大量带宽。DeepSeek干脆自研了编程语言TileLang,将Sinkhorn算法的前向和反向传播融合进一个“超级计算核”。这样,数据一旦加载到GPU的片上内存(SRAM),所有运算都在SRAM内部完成,中间结果无需回传到慢速的存储器。这成功将**“内存密集型”操作转化为“计算密集型”**,最大限度压榨了GPU的计算潜能。
- 选择性重计算 加宽的残差流会产生巨量中间激活值。若全部存储,显存将瞬间耗尽,导致训练效率降低。DeepSeek巧妙地采取了**“以时间换空间”的策略:在前向传播时,仅保留少量关键信息,例如Sinkhorn算法的中间迭代值等不重要部分直接丢弃。等到反向传播需要计算梯度时,再利用高效的“融合算子”**实时重新计算这些中间状态。由于重计算代价极低,此策略使27B甚至更大规模的mHC模型也能在有限显存下顺利运行,避免了“内存溢出”中断。
- 通信重叠技术 在大规模分布式训练中,GPU之间频繁进行数据通信(如同步梯度),等待通信时GPU常常闲置,浪费了宝贵的算力。DeepSeek将mHC的计算调度到一个**“高优先级的独立CUDA流”上。这意味着当主流任务等待网络通信时,GPU计算单元并不会闲置,而是立即切换到高优先级流,执行mHC的Sinkhorn计算。这种“计算-通信掩盖”技术,使得mHC的计算几乎是“免费”**的,因为它填充了原本被浪费的等待时间。这正是其训练时间仅增加6.7%的关键原因。
mHC的成功,绝非某个天才的灵光一闪,而是**“理论优雅”与“工程暴力”的完美结合**。它用最严谨的数学原理驯服了看似无解的难题,又用最极致的系统优化,在看似不可能完成的任务中找到了突破口。
mHC的实际效益与未来展望
DeepSeek不仅验证了mHC理论的正确性,更展现了其在实际应用中的巨大潜力。
- 训练稳定性:普通HC模型在训练中后期常出现Loss暴涨(梯度爆炸前兆),预示模型崩溃。mHC模型的Loss曲线则像教科书般平稳下降,展现出极强的鲁棒性。在270亿参数模型上,mHC的最终训练Loss比传统基线模型还要低0.021%。这个看似微小的数字,在预训练海量数据的背景下,通常意味着需要多消耗几千亿的学习数据才能弥补,因此mHC大幅提升了数据利用效率。
- 性能提升:预训练完成后,DeepSeek对mHC模型进行了涵盖常识推理、代码生成、数学解题等多个领域的标准基准测试(堪称“大模型奥林匹克竞赛”)。结果显示,mHC全面超越了传统基线模型和无约束的HC模型。尤其在需要多步推理、逻辑链条长的复杂任务中,mHC的优势尤为明显,例如在“BBH”高难度推理测试中提升了2.1%,在阅读理解任务DROP上提升了2.3%。
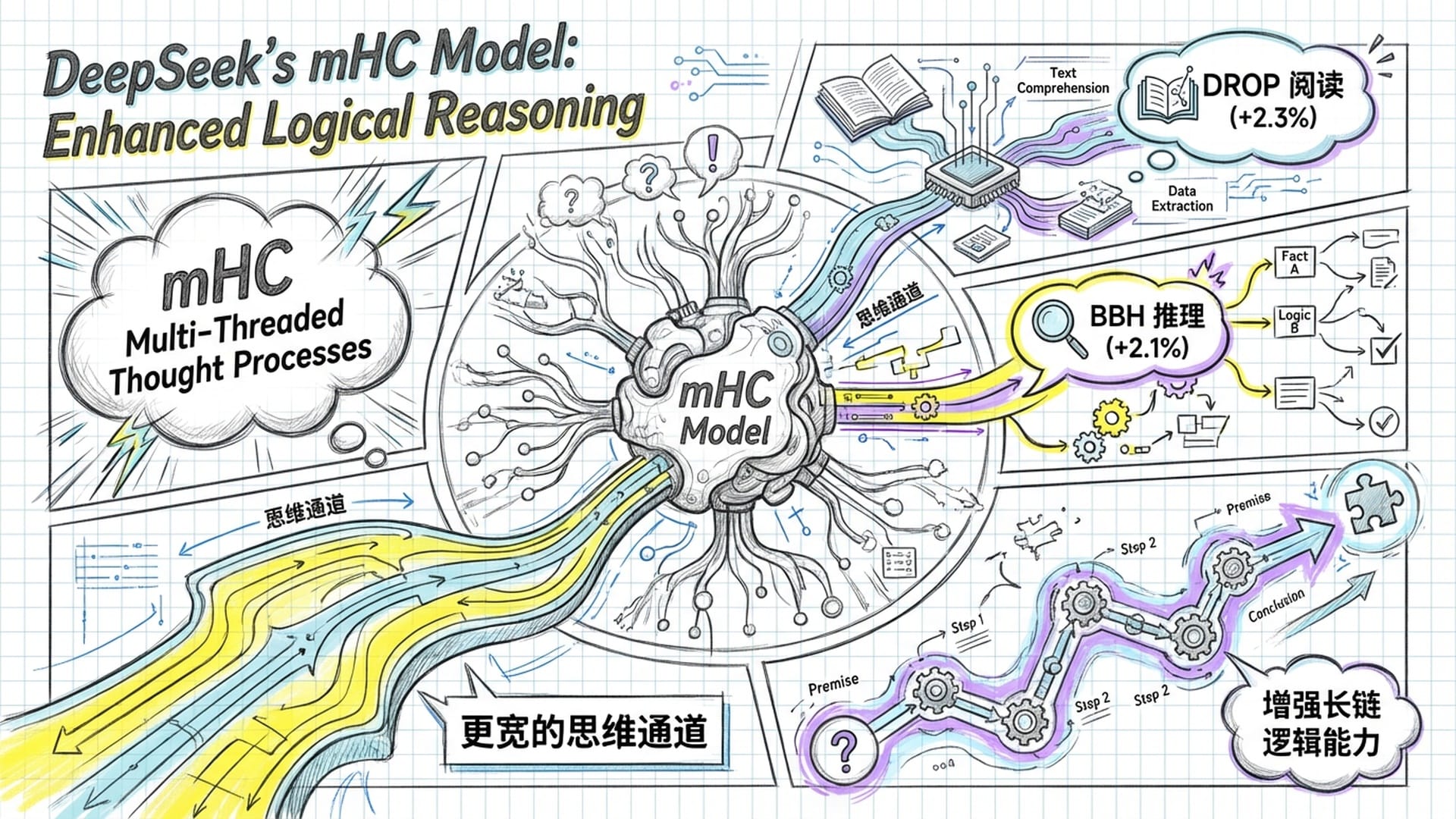
这表明mHC提供的**“宽残差流”,不仅仅是简单增加参数量,更像是在模型大脑中铺设了更多、更宽的“思维通道”。当模型处理复杂逻辑时,它能维持更多的“思维路径”或“中间状态”,不易“忘掉”之前的上下文信息。这种“并行处理能力”的提升,自然能处理更复杂的问题。而且,这些性能提升并未随模型规模扩大而消失,从30亿到270亿参数,mHC始终保持领先,证明了它是一个真正符合“Scaling Laws”**的架构改动,在未来的万亿参数模型上依然大有可为。
- 成本效益:对于追求投入产出比(ROI)的商业应用而言,mHC的效益无与伦比。其仅6.7%的额外训练时间开销,带来了训练过程的绝对稳定性(避免了昂贵的训练中断和回滚),以及关键任务性能2%以上的提升。在动辄需要上万块GPU的大集群训练中,训练稳定性本身就具备巨大的经济价值。一次因梯度爆炸导致的训练崩溃,可能就意味着数百万美元的算力白白浪费。mHC从数学根源规避了这种风险,这本身就是巨大的成功。
中国AI的“深水区”探索
mHC的发布不仅仅是一篇论文,它折射出DeepSeek乃至整个中国AI产业在面对外部硬件封锁和算力约束时,一种独特的进化路径。
传统的AI研究往往是算法与硬件解耦的:算法工程师设计模型,硬件工程师加速。但mHC展示的,是一种深度的“软硬协同设计”。DeepSeek并未因Sinkhorn算法计算复杂而放弃,反之,为了实现这一数学构想,他们重写了底层的CUDA内核,甚至开发了TileLang这样的定制化编译器。这种为了一个数学理念,“撸起袖子干到最底层,重写最核心代码”的能力,标志着中国AI研发已进入真正的“深水区”。未来的模型创新,将不再仅仅是堆叠更多层数,而是要深入到算子级别,进行微观优化。
这对于国产算力生态的启示也极其巨大。尽管mHC论文主要在英伟达GPU上验证,但TileLang的初衷之一便是跨硬件平台的高性能移植。mHC所展示的**“通过软件优化弥补硬件带宽短板”的思路,对于那些受限于HBM带宽的国产AI芯片来说,无疑是雪中送炭。通过算子融合和重计算,减少对显存的依赖,是在硬件制程落后情况下提升训练效率的必由之路**。
mHC也证明,残差连接并非不可动摇的教条。通过引入流形约束,我们完全可以设计出比 Y = X + F(X) 这种简单形式更复杂、更强大的拓扑结构。未来,我们可能会看到更多基于几何流形的架构设计,例如正交流形用于保持特征独立性,或者稀疏流形用于实现模块化训练。mHC开启了一扇大门,它告诉我们:只要能控制住“稳定性”这头野兽,神经网络的结构便可以变得更加狂野,更加自由!
“mHC是DeepSeek对大模型基础架构的一次革命性修正。它用严谨的数学理论驯服了不稳定,用极致的系统工程跨越了瓶颈,展现了‘理论-系统-实验’三位一体的硬实力。”
我个人相信,随着2026年的到来,mHC及其衍生的拓扑技术,将成为下一代基础模型(Foundation Models)的标准配置。它将推动人工智能从“暴力美学”向“精细化设计”转型。
在流形的约束下起舞,在系统的极限中穿梭。