

你是否曾深夜面对堆积如山的项目文档、市场报告,或是晦涩难懂的学术论文,在无数标签页间疲于奔命?你试图拼凑出“真相”,却常常淹没在信息的汪洋中,最终只剩下满脑子碎片化的知识和一句无力的“这到底讲了个啥?”。更糟糕的是,当你寄希望于AI助手时,它却吐出一堆看似流畅、实则逻辑不通的“幻觉”,引用的链接也常常是404。那一刻,你是否也曾有过摔电脑的冲动?
这正是我们要深入探讨的“真问题”:作为一个普通人,我们能否真正寄望于一个AI智能体,像顶尖分析师那样,为我们抽丝剥茧,理解复杂议题,甚至撰写出严谨、深刻且无懈可击的研究报告?这听起来似乎像是科幻场景,毕竟深度研究一直被视为人类大脑的高阶认知游戏。那些所谓的AI搜索、AI摘要,说到底,不就是披着高级外衣的搜索引擎吗?
但如果告诉你,现在有一个AI系统,它不仅悄无声息地做到了这一点,而且成本之低令人难以置信,你是否会感到惊讶?
“搜索并非研究”:阶跃星辰的颠覆性宣言
这款名为 Step-DeepResearch 的系统,由一家名为“阶跃星辰”的公司推出。他们的核心观点直接且富含挑战性:“搜索不是研究。”初听此言,你或许会反驳:平时上网查资料,不就是搜索,然后形成研究了吗?何必如此大费周章?
但请我们深入思考,当前市面上的搜索引擎,包括许多自称“AI搜索”的产品,它们的工作机制是什么?你输入关键词,它们迅速返回数百条链接,或许还会聚合前几条链接的内容,给你一段摘要。这本质上是“信息回溯”或“信息摘要”,解决的是信息的“召回率”和“准确率”问题——即“有没有”和“对不对”。
然而,真正的研究远不止于此。
思考一下: 如果老板要求你分析“未来五年全球合成生物学市场的投资风险”,你认为这仅仅是让你搜索“合成生物学风险”那么简单吗?
当然不是!这背后需要拆解成数十个细致入微的问题:合成生物学技术的发展阶段?主要参与者是谁?他们的商业模式如何?未来政策法规可能如何演变?潜在的生物安全风险有哪些?是否存在被替代技术颠覆的可能性?每一个问题,都需要你在不同的网站、数据库中反复搜寻,找到相互印证的证据,再进行复杂的推理和判断。
这绝非简单的“搜索”所能解决。搜索引擎只能为你提供零散的行业新闻、技术术语和偶尔几篇“专家预测”,这些信息甚至可能相互矛盾。
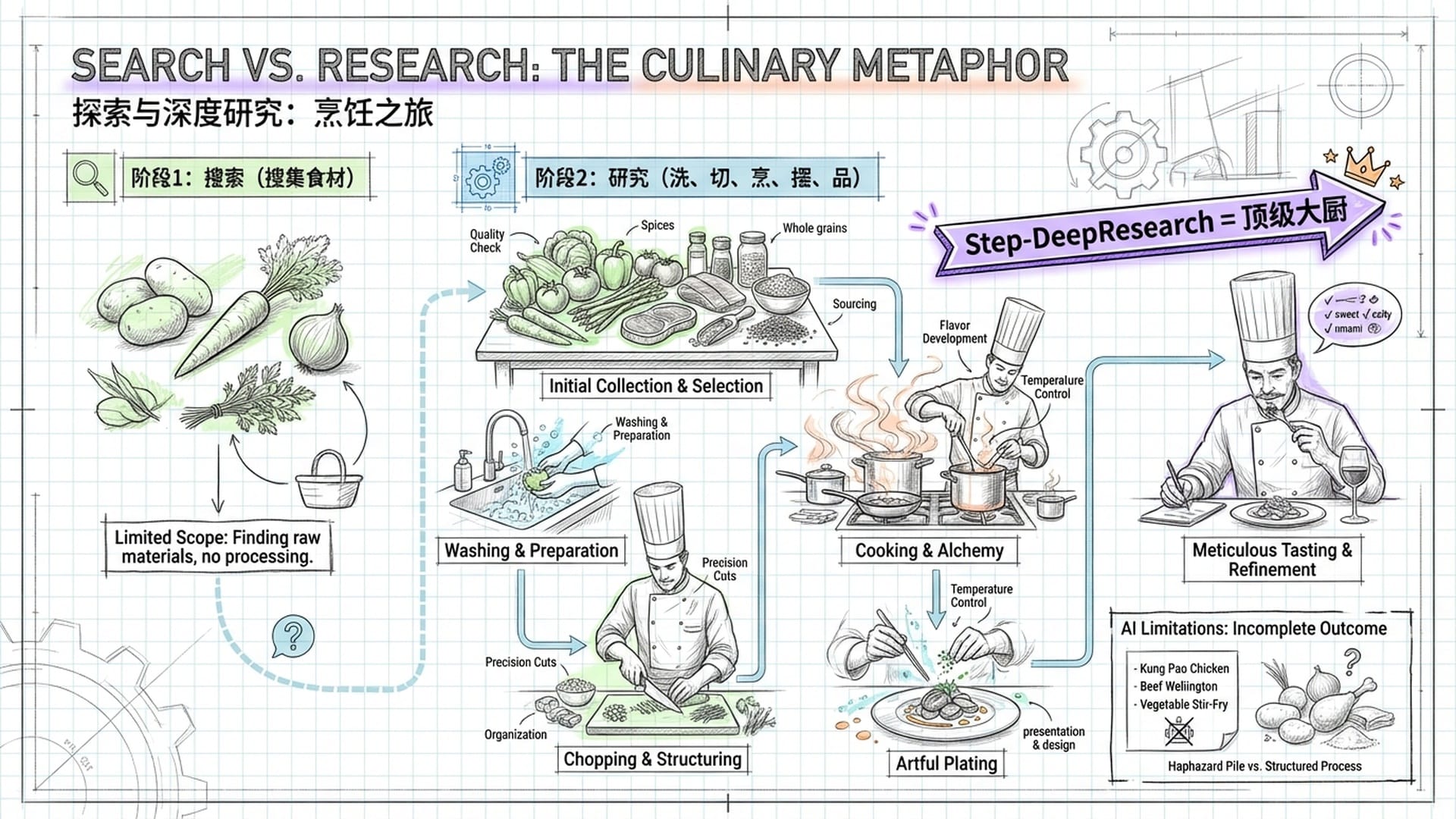
打个比方: 搜索就像是把食材拉到你面前,而研究则是将这些食材烹制成一桌满汉全席。目前大多数AI产品,顶多能帮你罗列菜名,或将生食材简单拼凑。它们根本不具备人类大厨从洗菜切菜到烹饪摆盘,再到最终品鉴迭代的整个复杂过程。
所以,当阶跃星辰宣称“搜索不是研究”时,它正是在批判当前AI普遍存在的“假大空”通病。许多号称能做“研究”的AI产品,实则不过是高级网页爬虫。它们擅长抓取网络信息,并用华丽的辞藻总结,却缺乏独立思考、批判性评估和构建逻辑链条的能力。面对模棱两可的信息,它们容易产生“幻觉”;需要深入挖掘时,则会“卡壳”。因为它们并未被训练成为真正的“研究员”,而仅仅是“信息搬运工”。
阶跃星辰的目标正是打破这种“搬运工”模式。他们不盲目追求大模型参数规模,而是另辟蹊径,致力于训练一个真正能够像人一样思考、规划、反思,最终输出有价值研究报告的智能体。他们将这种能力称之为“深度研究”。
深度研究的四大“原子能力”
Step-DeepResearch 能够实现这一目标,离不开其背后核心的技术哲学:原子能力。我们将“深度研究”视为一个复杂整体,而阶跃星辰将其解构,如同物理学家发现原子是物质基本单位一般,将深度研究拆解成一系列更小的、可独立训练的“原子能力”。
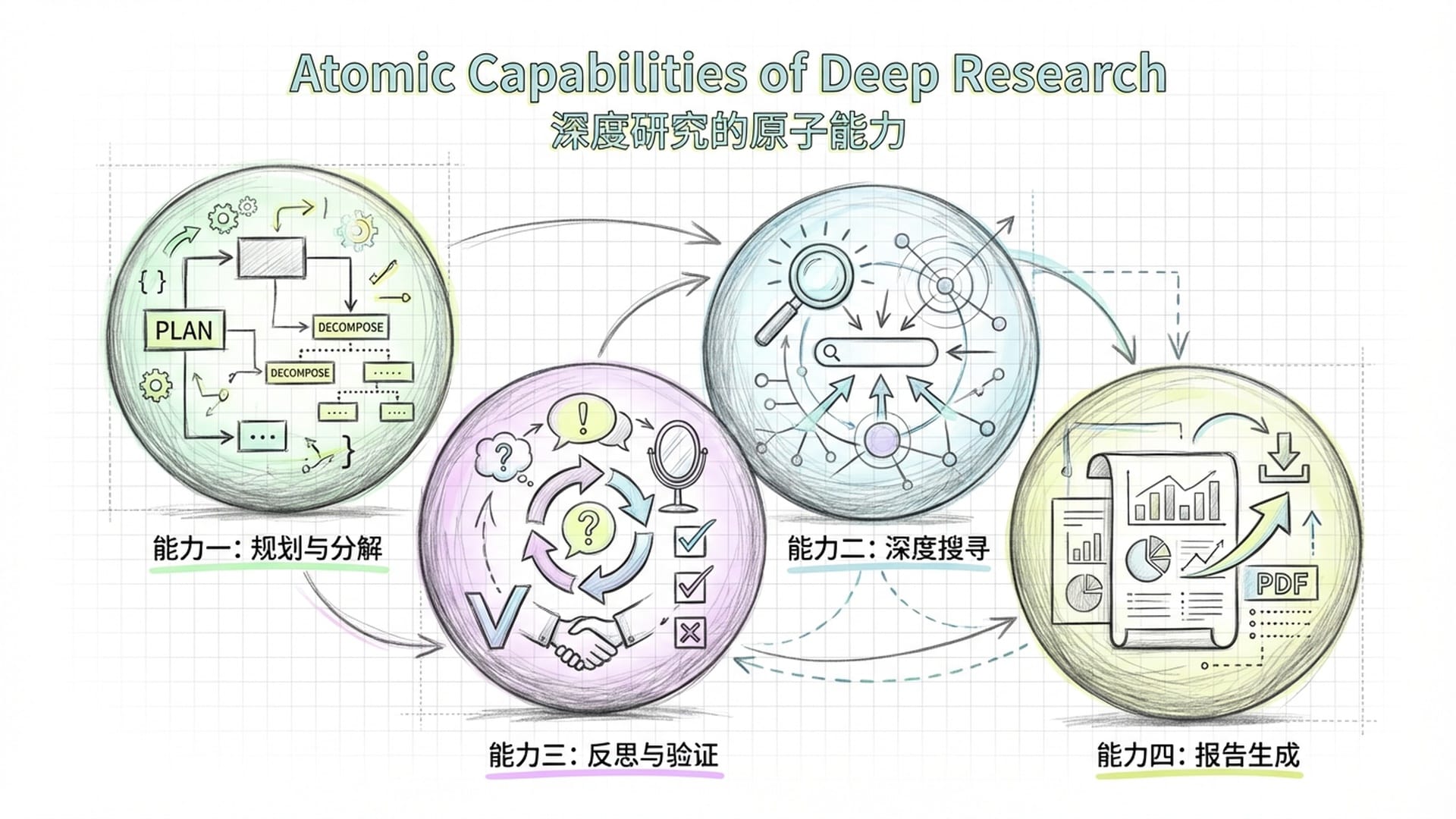
这四大原子能力包括:
1. 规划和任务分解
研究并非盲目行动,而是始于清晰的思考:要研究什么?如何逐步拆解问题?先做什么,后做什么?这就像建造房屋,必须先有设计图纸。
为使AI习得此能力,阶跃星辰采用了巧妙的“逆向工程”方法。他们收集了大量高质量的人类撰写报告(如专业投资分析、权威学术综述),然后利用一个比Step-DeepResearch更强大的“老师模型”进行反推:若要产出这份报告,最初的用户问题可能是什么?应如何逐步规划和执行?
关键洞察: Step-DeepResearch 学到的不是“画饼”,而是“圆饼”。它不仅会制定计划,更会实施计划。通过“轨迹一致性过滤”,只有那些真正能解决问题并严格按计划执行的轨迹,才会被保留并用于模型训练。
这如同观看一道数学题的完美解题过程,再反向学习其解题思路。系统还会对AI生成的计划进行“轨迹一致性过滤”:再漂亮的计划,如果实际执行后无法解决问题,也毫无意义。
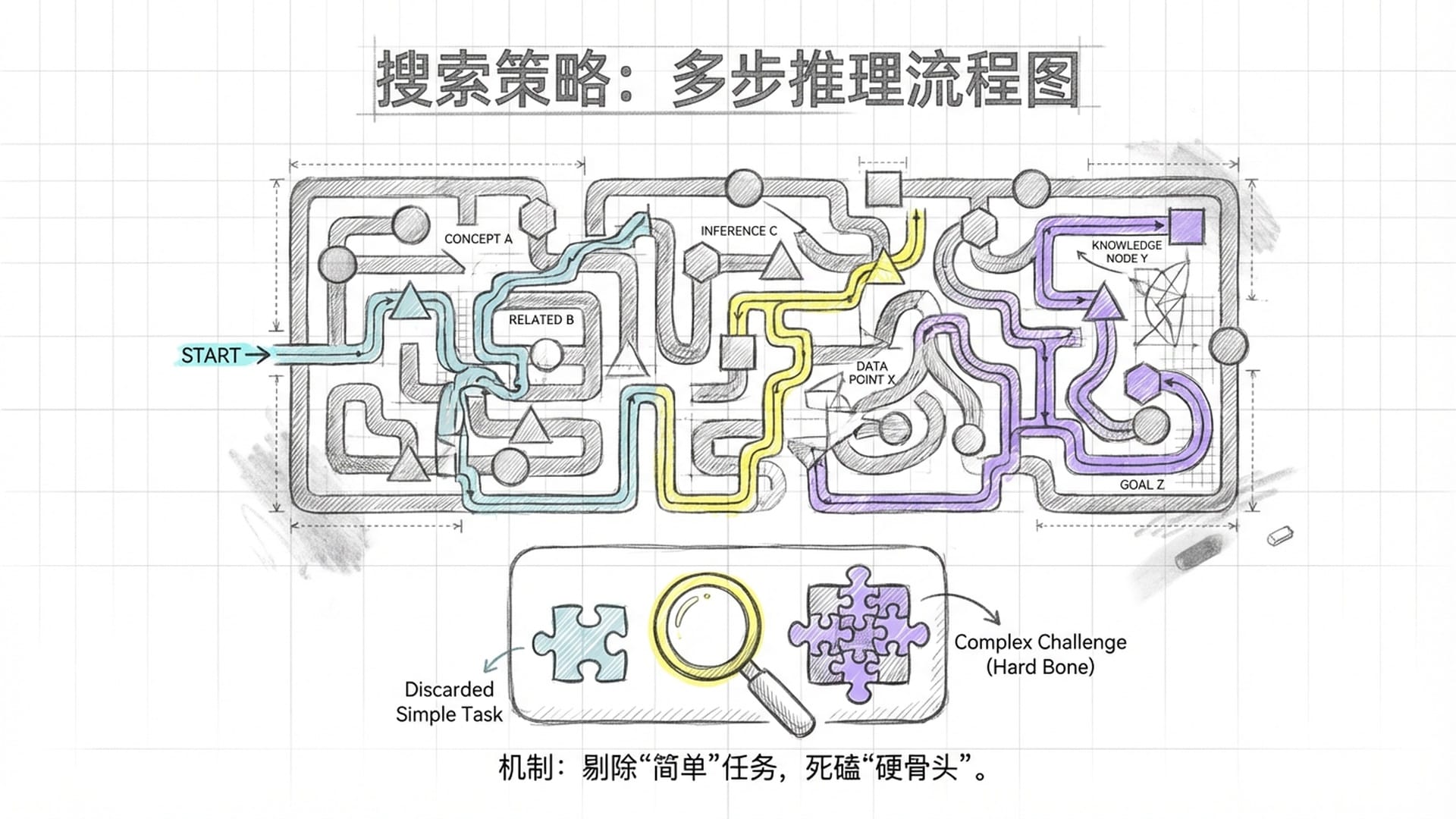
2. 深度信息搜寻
这绝非简单的关键词搜索。要研究一家复杂的生物科技公司,其技术、专利、合作方、竞争对手、市场趋势等信息分散在无数地方。
Step-DeepResearch 如何学习?他们构建了基于“知识图谱”的训练数据。知识图谱如同巨大地图,标注着各种实体及其关系。AI被训练成能在知识图谱中“游走”,通过多步推理找到答案。例如,它会先找到公司的主要研究方向,再据此查找相关学术论文和专利,并通过论文作者和专利持有人反查其他项目,层层剥开。它不满足于表面信息,而是要挖掘信息之间的内在关联。
核心机制: 阶跃星辰引入了“难度过滤器”。如果一个问题,连其QwQ-32b模型都能简单搜索解决,则被判定为“太简单”,从训练数据中剔除。这确保Step-DeepResearch的训练资源全部集中于真正有挑战性的“硬骨头”任务。
3. 反思与验证
这是对抗AI“幻觉”的杀手锏。Step-DeepResearch拥有其独有的“免疫系统”,它会模拟人类专家犯错并自我修正的过程。在数据生成过程中,系统会故意让专家模型生成错误路径,再强制模型“反思”:哪里出错了?是信息源不可靠?还是逻辑推导错误?模型会带着这些“错误记忆”重试,直至找到正确答案。
Step-DeepResearch将人类的验证过程拆解为五个原子步骤:
- 提取核心事实
- 规划验证路径
- 执行多源搜索验证
- 根据验证结果动态调整
- 汇总生成验证结论
这套流程被刻入模型的“骨髓”,使其在生成报告时能自动进行交叉验证,大幅降低了胡说八道的可能性。
4. 报告生成
研究能力固然重要,但能否清晰、严谨地表达研究结果同样关键。这如同顶级研究员,不仅能理解问题,还能撰写出顶级论文。
Step-DeepResearch在训练时,会学习不同领域的专家级报告的行文逻辑、术语风格和篇章结构。更重要的是,它被强制要求,每一句关键论断都必须像正式学术论文一样,有明确的引用来源标注。这样,读者在查阅报告时,不仅能看到结论,还能回溯到得出结论的原始证据。这对于重视可追溯性和权威性的商业报告和学术研究而言,至关重要。
评价体系: 阶跃星辰设计了名为“Rubrics Judge”的精密评价体系。这个Judge模型如同经验丰富的评审专家,能依据细致入微的评分标准,对Step-DeepResearch生成的报告进行多维度打分。其奖励机制极为严苛:只有当模型“完全满足”正面标准时,才给一分;只要存在一点缺陷,就直接扣分。这种严苛,促使AI不断提升,像顶级专家一样思考和行动。
这四种“原子能力”,如同螺丝钉、齿轮和轴承,看似简单,一旦精确组合,便能构建出复杂的机器。
革命性的单智能体架构与成本优势
更令人惊喜的是,Step-DeepResearch的系统架构并未采用复杂的“多智能体协作”模式。当前许多Agent系统倾向于设计多个AI角色(如规划者、执行者、审查者),使其互相协作、制衡。这听起来很酷,也符合人类社会的分工模式,但问题在于,一旦系统复杂,AI角色间的沟通成本、调度延迟和协调难度会呈指数级上升。
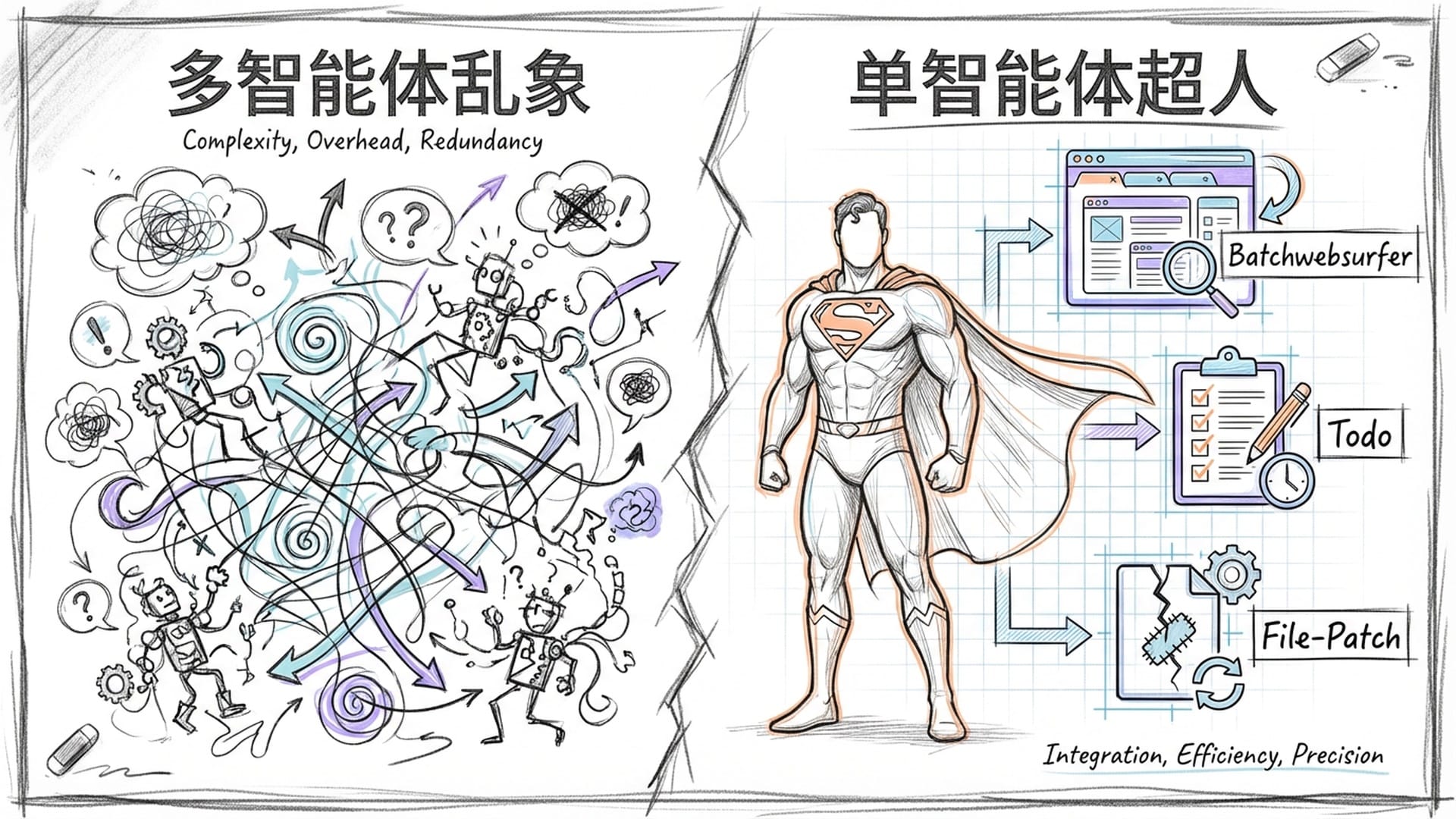
Step-DeepResearch反其道而行之,回归“单智能体”本源,沿用经典的“思考-行动-观察”(Reasoning-Action-Observation)循环。这意味着它无需一个团队,只需训练出一个“超人”,便能独立完成所有任务。
这个“超人”配备了多项强大工具:
batchwebsurfer:一个能批量、并发搜索和浏览网页,一次性消化大量信息的工具。todo:如同超级备忘录,在长时间研究任务中,强制AI维护动态任务列表,确保目标不偏离。file:模拟文件系统,支持长文档的读取、写入和修补(Patch)。特别是“修补”操作,允许模型只修改文档一小部分,如修正数据或增加引用,而非重写整个文档。这大大节省了Token消耗,将长文修改成本降低七成以上。
除了工具层面的创新,阶跃星辰还在数据源上狠下功夫。AI领域有句铁律:“垃圾进,垃圾出。”为解决此问题,Step-DeepResearch建立了包含600多个核心权威站点的白名单索引库,涵盖政府官网、顶级学术期刊、知名智库等。信息检索时,这些权威站点的权重被显著提升,有效排除了SEO垃圾和不可靠网站。
更甚者,他们引入了 PHash感知哈希技术,处理网页浏览时的视觉冗余。AI浏览网页时常需“看”网页截图。若鼠标滚动或页面刷新导致截图仅有微小变化,每次都输入完整新截图会产生大量昂贵的多模态Token消耗。PHash技术能实时计算连续动作间网页截图的感知距离,若页面变化微小,则只输入变化部分或不输入图像,回退到纯文本流。这有效避免了为重复网页截图付费,是其实现极低推理成本的关键之一。
效能与成本:降维打击的实力
Step-DeepResearch在Scale AI的ResearchRubrics基准测试中取得了令人瞩目的成绩。
- Gemini DeepResearch 获得63.69分,单次报告生成成本预估为六块六毛五。
- OpenAI DeepResearch 获得53.67分,成本为五块三毛二。
- Step-DeepResearch 获得61.42分,仅次于Gemini,但其单次报告生成成本低于五毛钱人民币!
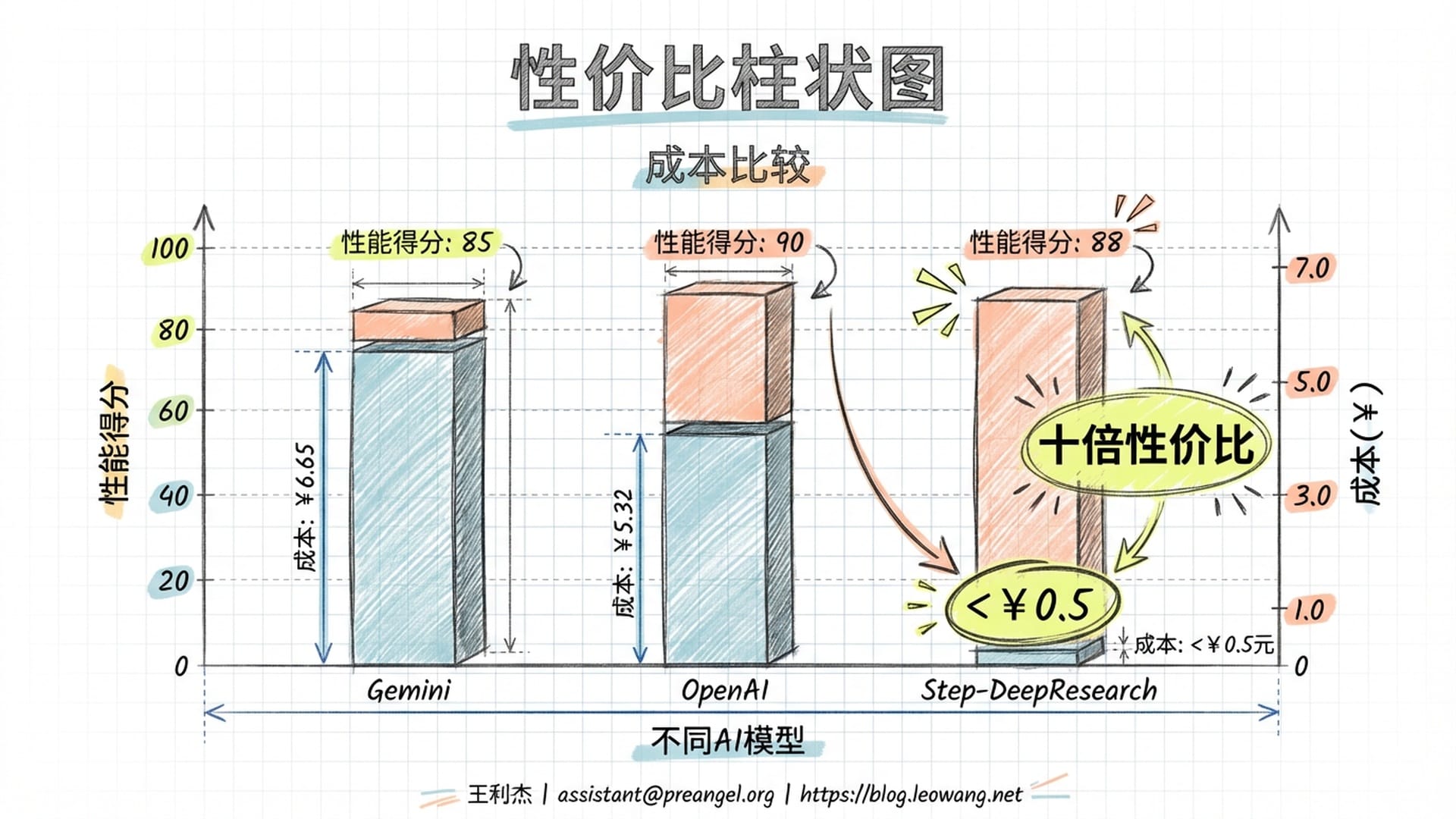
这意味着Step-DeepResearch以不到竞品十分之一的价格,提供了同等级别的研究能力,这无疑是一种降维打击。
为何它能做到如此低廉的成本?
- 其基础模型仅为32B,远小于千亿、万亿参数模型,推理算力需求天然较低。
- PHash视觉过滤技术大大减少了昂贵的多模态Token处理,避免了重复网页截图的费用。
- 经过深度原子能力训练,模型能更精准地规划路径,减少无效搜索和错误尝试,从而降低了总Token消耗。
这就像是一位能力强大、速度飞快的超级研究员,其每小时工资可能仅为其他专家的十分之一。这简直是重新定义了“Agent经济学”。
局限与展望
当然,任何技术都有其局限性。Step-DeepResearch并非万能。在面对极端的反爬虫机制或复杂API鉴权时,它偶尔仍会遇到问题。在外部信息极度碎片化的漫长任务中,也可能产生“似是而非”的推论,这种“合理的幻觉”往往比明显错误更难察觉。此外,其某些决策对用户而言仍是黑盒,在金融、法律等高风险领域可能构成合规障碍。
但阶跃星辰也描绘了清晰的未来演进路径:
- 从“单智能体”向“多智能体”协作演进,实现多个AI专业分工、互相制衡,打造更高效的研发团队。
- 引入“过程监督”,不仅评估最终报告结果,更要审查AI的每一步思考过程,确保每一步推理都可验证、清晰且正确。
这正是通向更可信AI的必由之路。
结语
回到最初的问题:原子级的深度研究智能体,会不会只是个噱头?从Step-DeepResearch的表现来看,它绝非噱头。通过精细化的数据工程和系统化的训练范式,它有力地证明了,中等规模的模型完全可以在特定垂直领域,达到甚至超越顶尖闭源模型的效果。
Step-DeepResearch开启的,可能是一个AI Agent的普惠时代。它以极低的成本,将原本昂贵、仅少数人能享有的“专家级研究”能力,带给了每一个人。这不仅是一个工具,它很可能改变我们获取信息、进行决策和创造认知价值的方式,推动AI从“助手”真正进化为我们的“合作伙伴”。