
李飞飞:AI的下一幕——走出屏幕的智能体
在过去的两年里,我们对人工智能的认知或许还停留在“管中窥豹”的阶段,甚至存在一些“偏差”。许多人可能仍旧认为ChatGPT代表了AI的终极形态,惊叹于它精妙的遣词造句能力。然而,在 李飞飞教授 及其团队看来,如果AI仅仅停留在“说学逗唱”的层面,那么它终究只是一个活在数字“大观园”里的“贾宝玉”,无法真正理解真实世界。
真正的AI,将不再局限于屏幕之内,它正逐步“长出眼睛”、“伸出双手”,甚至开始形成自己的“世界观”。这不是科幻想象,而是当下 AI发展最前沿且反直觉的趋势。李飞飞团队发布了一份长达八十多页的重磅报告——《智能体AI:多模态交互展望》,以及他们在World Labs中的创新实践,这些都预示着我们正站在一个巨大的分水岭上。AI不再是只会撰写优美文章的“文科生”,它将“野蛮生长”,成为一个真正在物理世界中“摸爬滚打”的“社会人”。
李飞飞教授明确指出,单纯的大语言模型已接近理解物理世界的“天花板”。未来的通用人工智能(AGI),必须拥有“身体”和“空间感”。我们正在从“被动生成式AI”跨越到“主动交互式AI”的新时代。
什么是智能体AI?它与传统AI有何本质区别?
传统的AI应用,如我们与ChatGPT的互动,大多在封闭的数字空间中完成。它能够理解文字指令、生成漂亮的文章,但它并 不具备对物理世界的真实感知和互动能力。它不知道“杯子”的重量,“桌子”的高度,甚至不理解太阳为何东升西落。
而 智能体AI 则被定义为一套能够感知视觉、语言和各种环境数据,并能做出“有意义的、具身行动”的交互系统。这听起来有些复杂,但我们可以将其拆解为三个核心特征:
1. 多模态感知能力
智能体AI不能仅仅依赖文本信息,它需要拥有“眼睛”去观察,“耳朵”去聆听,甚至未来还需要懂得“触摸”——处理 像素级的图像、波形级的音频,以及未来可能的 触觉数据。这就像一个初生的婴儿,通过看、听、摸来认识世界,而非单纯依靠背诵字典。这种能力是智能体理解复杂物理世界的第一步。
2. “接地气”的关联
智能体AI的输入和输出必须与特定的物理或虚拟环境紧密相连。例如,它不再仅是回答“明天天气怎么样”,而是在特定场景下,如“告诉我这个房间里哪件衣服最适合明天出去穿”。这种“接地性”要求模型不仅理解文字符号的意义,更要深刻理解这些符号所指代的事物,及其在真实世界中的 位置和状态。
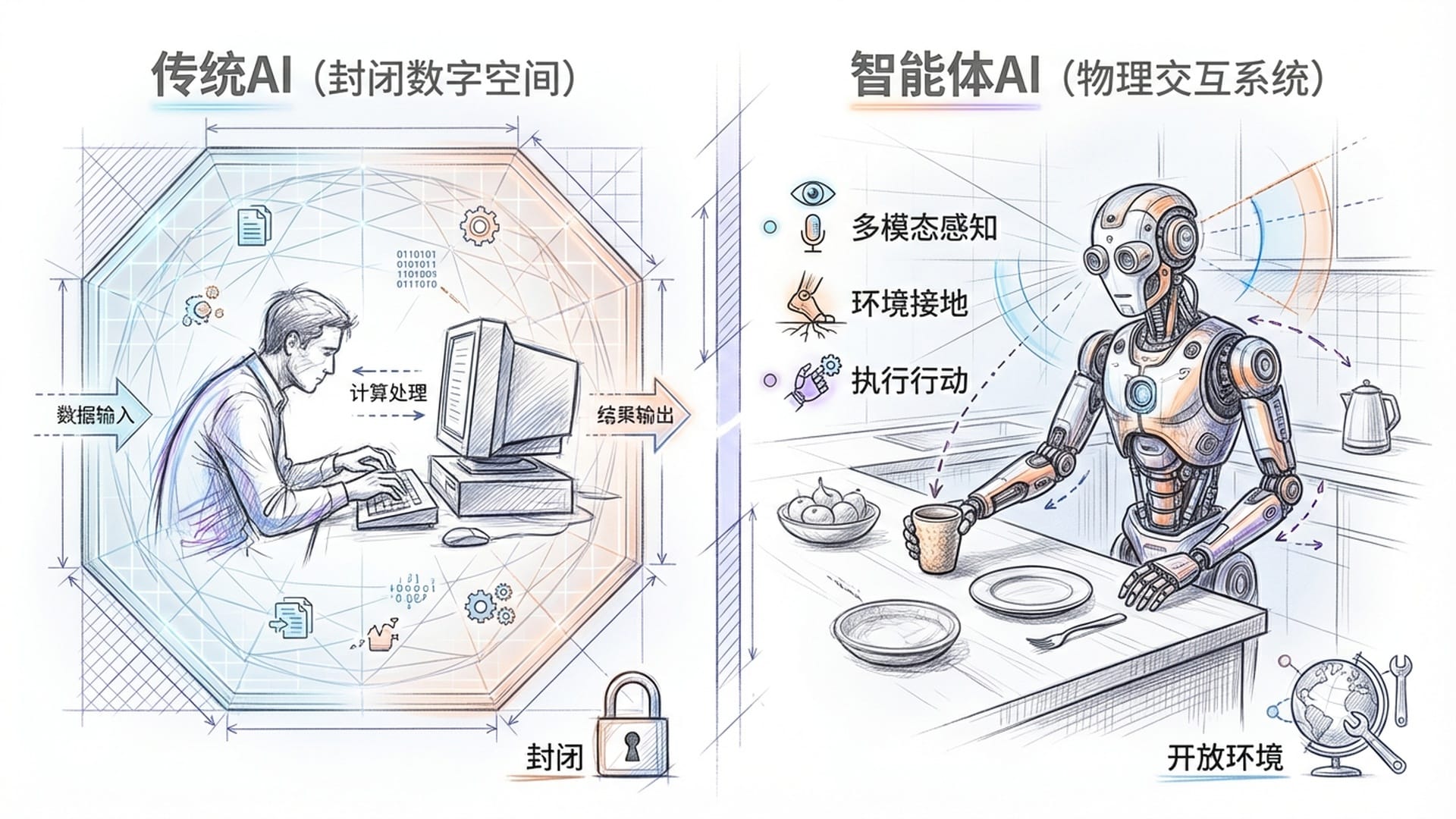
3. 具备“身体”和“行动”
以往AI的输出可能只是一段文字或一张图片,但智能体AI的输出是能够对环境产生改变的 操作指令。例如,“拿起杯子”、“走到那个角落去”、“把这个文件保存下来”。它不再仅仅是“口嗨”,而是能“动手”去改变现实。
李飞飞的报告中一语中的地强调:“智能体AI是通往通用人工智能的必经之路。” 因为通用人工智能不仅要掌握“知识”,更要能够“执行”。这标志着AI发展史上从“只会说”到“真能做”的里程碑式飞跃。
智能体AI的“物种大发现”
你可能会好奇,这不就是机器人吗?诚然,机器人是具身智能体最直观的形态,但智能体AI的范畴远比此更广。报告将智能体细分为几大类:
- 具身智能体:这是我们最直观理解的机器人,如家庭服务机器人、工业机械臂,甚至自动驾驶车辆。它们在物理世界中进行实际的移动和操作。其主要挑战在于如何将模拟器中训练的能力无损地迁移到现实世界。
- 模拟与游戏智能体:这类智能体生活在数字世界中,例如《我的世界》等游戏里的NPC。 生成式AI 能够赋予这些NPC生命,使其能根据玩家行为实时生成对话和行动。例如,《我的世界》中的“Voyager”项目,就是一个能在游戏里自主学习、进步,并能自行制造工具、完成任务的智能体。
- 交互式助手与知识智能体:它们虽无物理身体,却能在数字世界中展现“行动力”。例如,能够操作电脑系统,协助处理Excel、Photoshop,甚至搜寻资料、整理信息的智能体。典型的例子包括AutoGPT、BabyAGI,它们能分解任务,并调用各种工具和数据库来完成复杂工作。
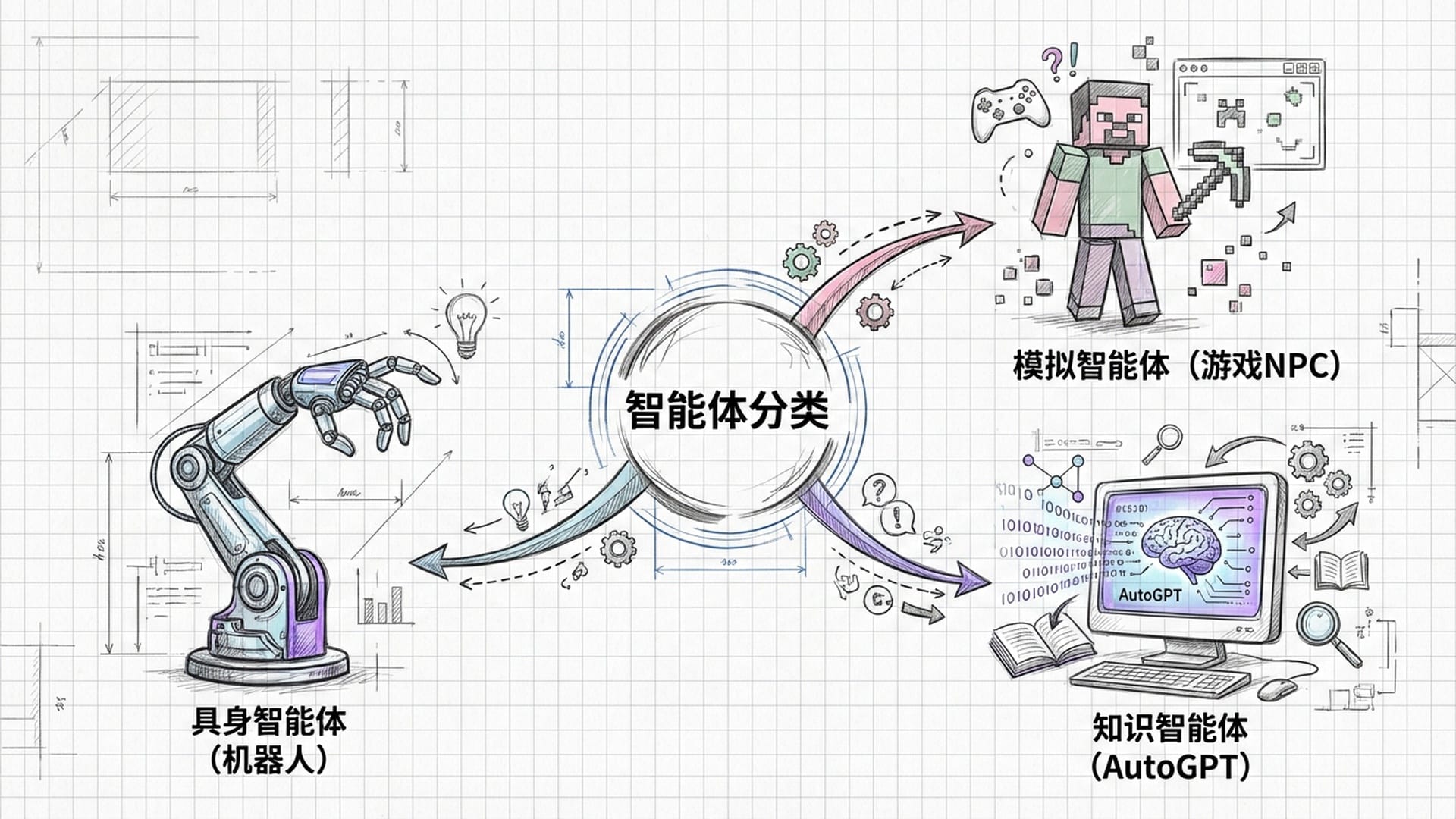
无论是身处物理世界、游戏世界还是数字办公环境,这些智能体的核心逻辑都是一致的:感知环境状态 -> 规划行动序列 -> 执行并获得反馈。这是智能体AI最底层的运行机制。
智能体AI的认知架构:大脑、想法与记忆
智能体AI的“大脑”是如何运作的呢?李飞飞团队在报告中系统地解构了其认知架构。
1. “大脑核心”:推理引擎
我们可以将整个智能体想象成一个人。它的“大脑核心”通常是我们熟悉的大语言模型(LLM)或视觉-语言模型(VLM)。但在这里,大模型不再是单纯的“话痨”,它升级为 推理引擎。它利用庞大的知识库,理解当前环境,推断用户意图,进而制定行动计划。这要求大模型具备更高的 逻辑一致性 和 指令执行力,能够凭借“常识”解决以前未遇到的问题。
2. “想法”:规划能力
拥有“大脑”还不够,智能体还需要“想法”,即 规划能力。聊天机器人只能逐句对话,而解决现实问题往往需要多步骤、非直线的规划。因此,智能体AI必须学会“深谋远虑”。
报告中提到了几种前沿规划算法:
- 思维链(Chain of Thought, CoT):让AI逐步展现其思考过程,提高问题解决的可靠性。
- ReAct范式:智能体在“思考-行动-观察”的循环中,像侦探一样查询信息、执行动作,并根据反馈进行推理,从而减少“胡说八道”的情况。
- 思维树(Tree of Thoughts, ToT):针对复杂任务,智能体能像下棋一样预演不同决策的后果,选择最优路径,这接近人类的“多线程思考”。
- 反射与修正(Reflexion):智能体在失败后自我分析原因,将“教训”储存起来,提升自主进化能力。
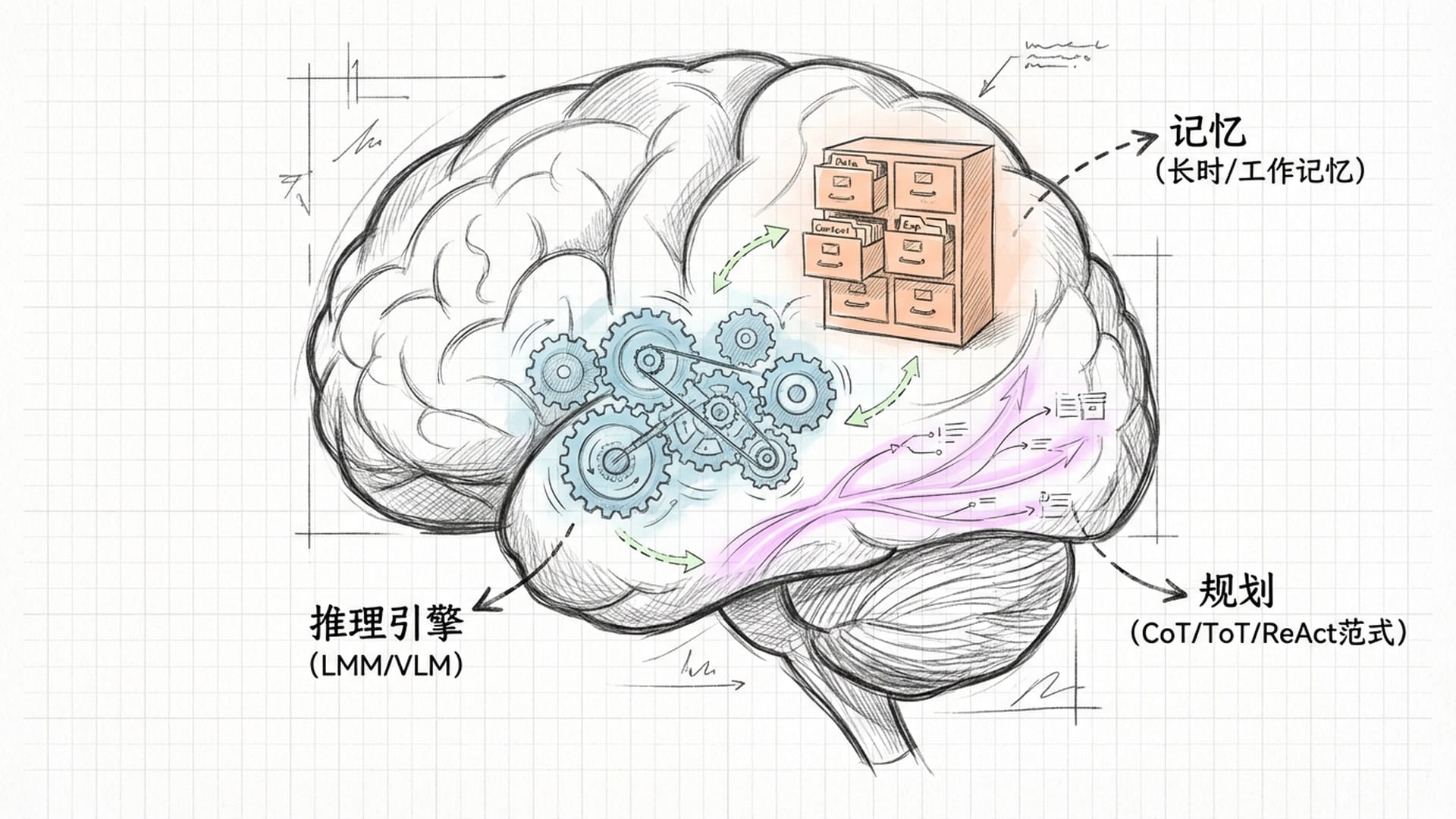
3. “记忆”:工作与长时记忆
智能体AI也像人类一样需要记忆来积累经验:
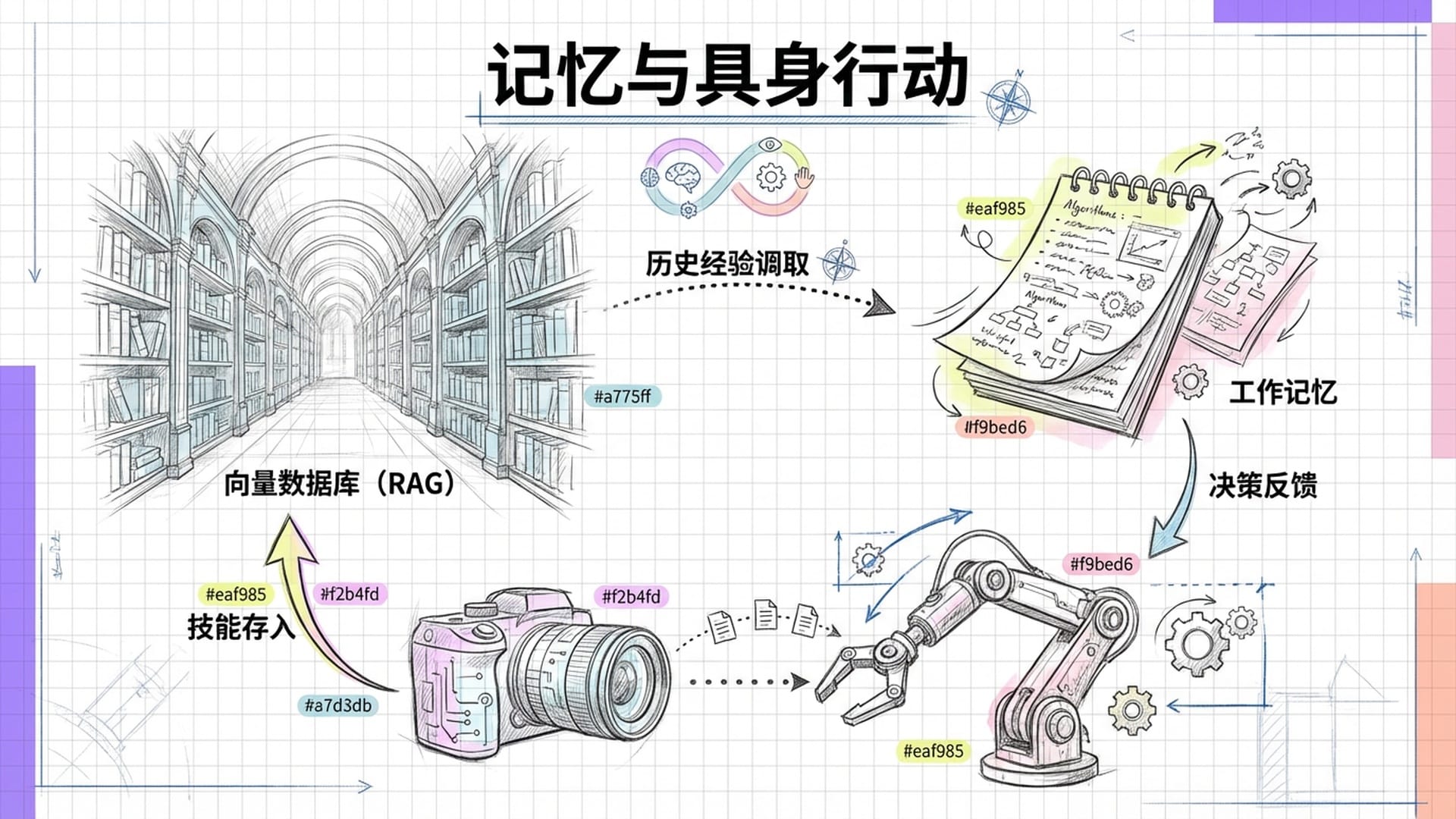
- 工作记忆:类似于短期记忆,用于记录当前任务和即时交互信息。
- 长时记忆:利用 向量数据库 和 RAG技术,智能体能够存储海量的历史对话、习得技能和各种知识。在遇到类似情况时,它能迅速调取相关经验,实现“越用越聪明”。
4. “长眼睛”与“使手脚”:多模态感知与具身行动
- 多模态感知:将摄像头捕获的画面、麦克风录制的声音转化为AI可理解的数据,使AI能够“看懂”并识别物体。
- 具身行动:将AI的决策转化为真实世界中的动作,如通过API调用或直接控制机械臂运动。如何有效设计其“行动空间”是关键。
从文字到世界:World Labs的“激进押注”
如果说《智能体AI》报告是对过去研究的“大盘点”,那么 World Labs 的成立及其发布的《From Words to Worlds》(从文字到世界)宣言,则是一次面向未来的 激进押注。这标志着研究重心从“一个智能体如何行动”转向了“如何构建一个智能体能理解的完整世界”。
李飞飞教授深刻指出:语言,作为人类智慧的重要载体,在描述物理世界时却是极其“有损”和“低带宽”的。我们无法用语言完全描述一个三维空间中的物体及其全部细节。因此,AI如果仅仅停留在语言层面,将永远无法真正理解物理世界的本质。
真正的智能必须包含 空间智能——即感知、推理、生成,并能在三维空间中与物体互动的能力。这不仅仅是识别一张猫的图片,而是要理解猫在三维空间中的形状、跳跃时的物理轨迹及其与周围物体的空间关系。空间智能更强调对 世界本身和物理规律的建模能力,它就像具身智能体的“底层操作系统”。
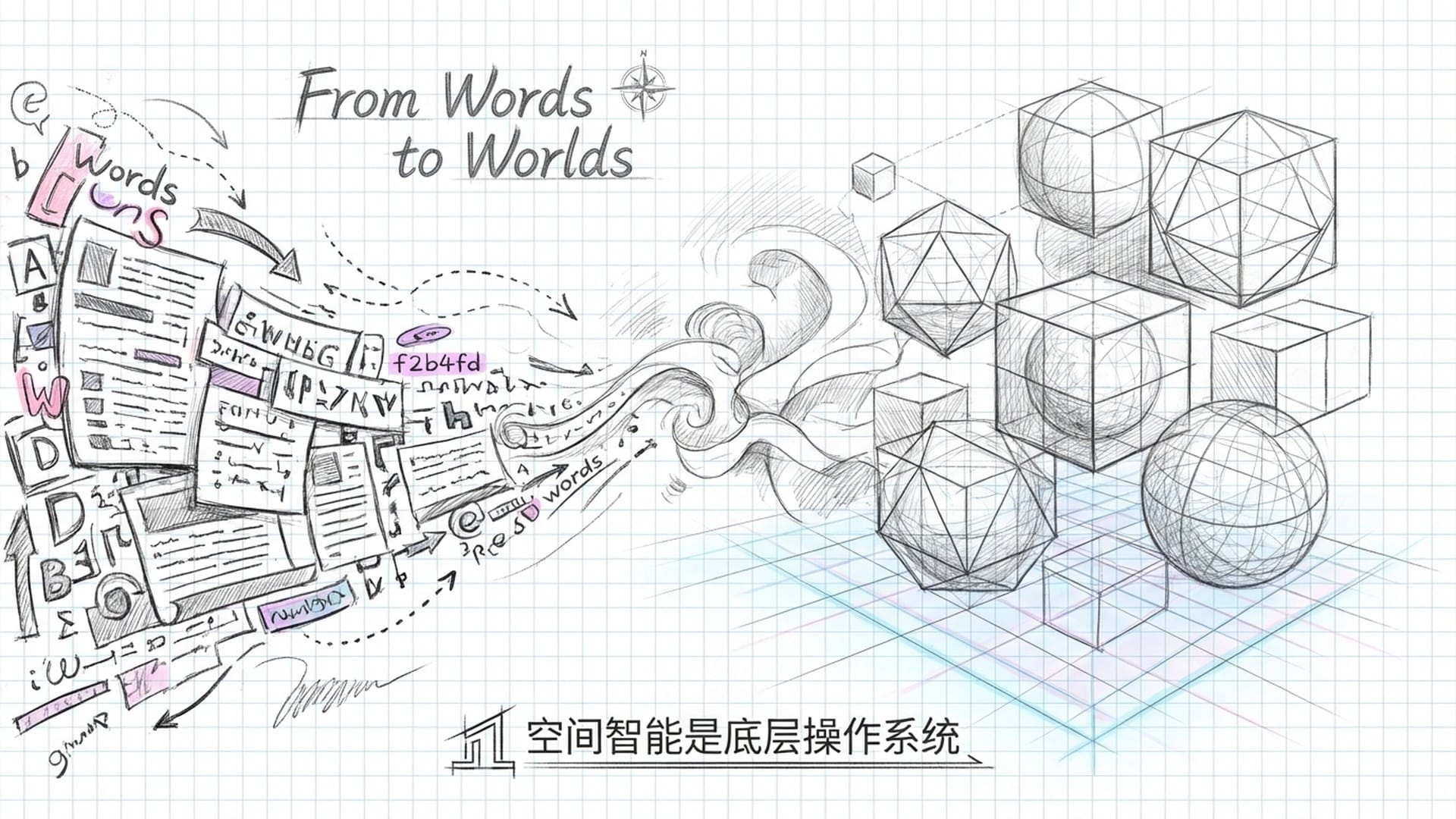
World Labs的宏伟目标是构建 大型世界模型(Large World Models, LWMs)。这种模型不仅能像Sora那样生成短视频像素,更要能生成具有物理属性、几何结构且语义统一的 3D世界。这相当于 生成式AI从2D直接进化到3D,甚至是4D的“维度打击”。
她们为此推出了两个“大杀器”:
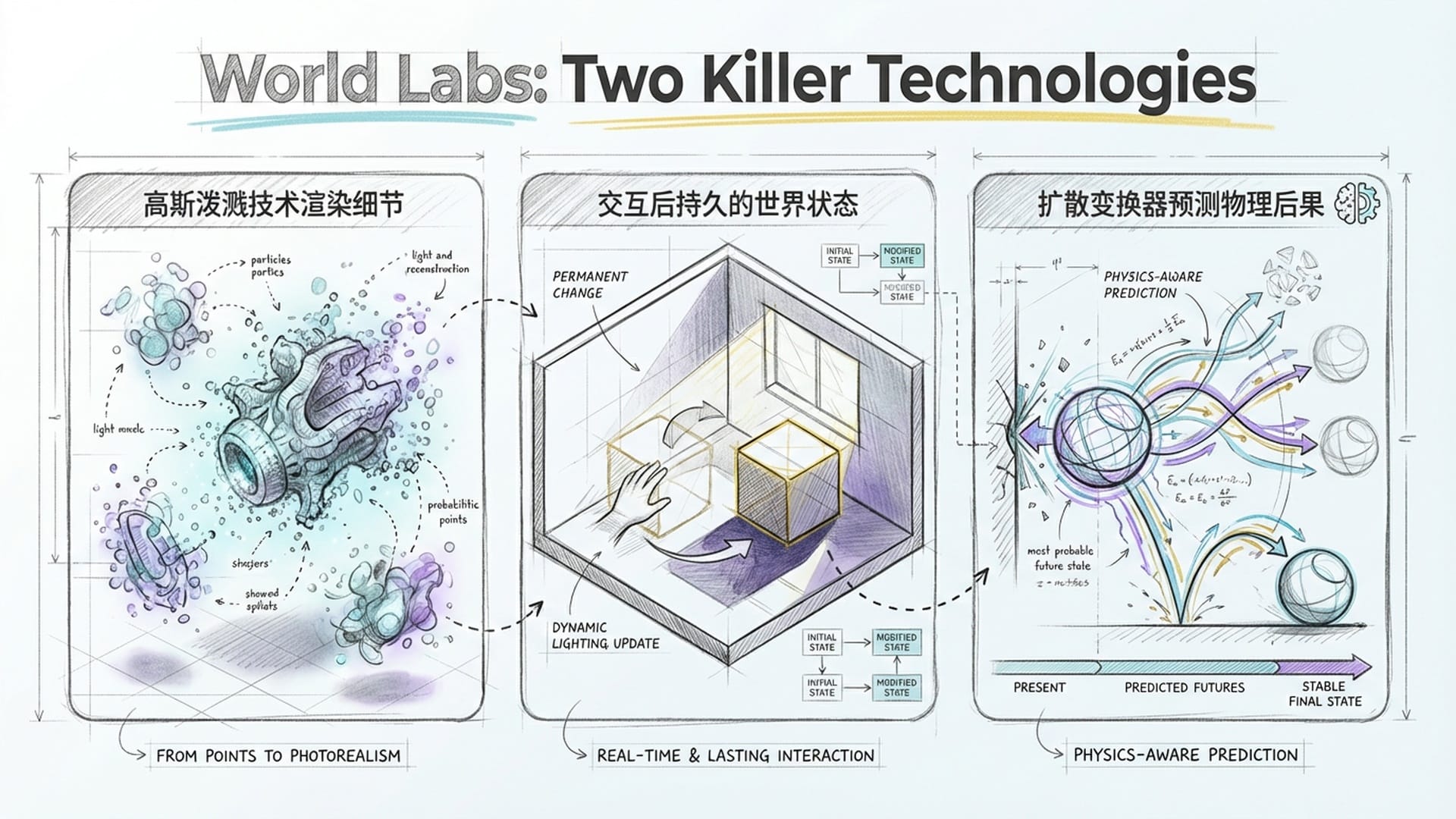
1. Marble:世界生成引擎
Marble是一个“世界生成引擎”,它能通过文字、图片或草图,生成一个完整、可编辑且物理属性真实的 3D环境。其核心技术是 “高斯泼溅”(Gaussian Splats),这是一种用无数个带有颜色和透明度的“3D粒子”来表示场景的新兴3D渲染技术。这种方法渲染速度极快,能捕捉复杂的细节和光影。
更重要的是,Marble生成的世界是 “持久的”和“互动的”。这意味着如果你在虚拟房间移动一把椅子,下次进入时它仍在新的位置,光影也会相应变化。它是一个真正意义上的有记忆和物理规则的“三维世界”。
2. RTFM (Real-Time Frame Model):神经物理引擎
RTFM利用 扩散变换器(Diffusion Transformer),不仅能生成静态场景,还能实时生成对用户交互有反应的视频流。传统游戏引擎需要预设物体的重量、摩擦系数等物理规则,而RTFM通过观察海量视频,自行“学会”了 物理规律。它能直接预测“如果我推这个杯子,下一帧画面会变成什么样”。这堪称一套 “神经物理引擎”。
这意味着AI拥有了 “直觉物理学”,能像人类一样在脑海中模拟物理后果。这对于机器人至关重要,它可以在虚拟世界中预演无数种操作方案,从而降低现实世界中的试错成本,提高效率。
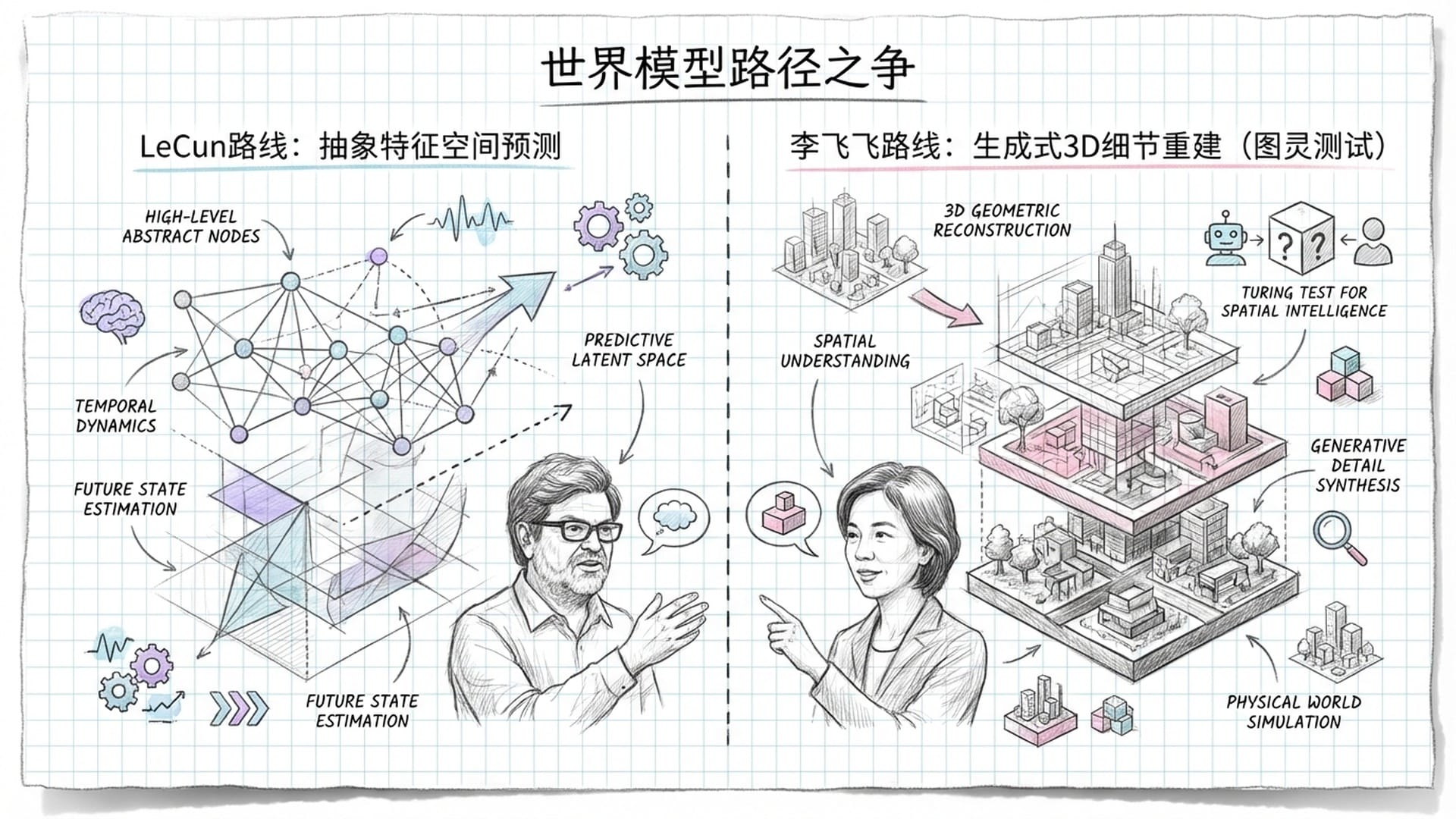
路线之争:李飞飞与Yann LeCun
提到“世界模型”,Meta首席科学家 Yann LeCun 也是其坚定拥护者,但他与李飞飞的路线有所不同。LeCun认为AI无需在像素层面预测世界,那会浪费计算资源并容易产生幻觉,而应在更抽象的 “特征空间” 中预测世界的本质变化。在他看来,“生成”不等于“理解”。
而李飞飞的World Labs则选择了更 “生成式”的路线。她认为,能够重建和生成细节丰富的3D世界,是验证模型是否真正理解空间关系的最佳方式——这恰如AI界的 “图灵测试”,且生成的3D世界本身就具巨大价值。
这两条路线的殊途同归或相悖,将在未来几年成为AI基础研究的核心看点,共同推动AGI的到来。
智能体AI面临的严峻挑战
尽管宏伟蓝图已绘就,李飞飞团队清醒地指出了智能体AI面临的挑战:
1. “幻觉”问题与“接地”解决方案
在纯文本大模型中,幻觉可能只是生成错误信息。但在智能体AI中,幻觉可能导致机器人打破物品、误诊病情甚至自动驾驶的危险决策。其根本原因在于大模型的知识是 “无实体”的,它学习的是词语间的统计概率,而非词语与物理世界间的因果关系。
李飞飞团队的解决方案是:“接地”。通过多模态输入(如摄像头感知)和行动反馈(如尝试抓取),智能体能用物理事实校准认知,减少“胡说八道”。例如,当模型试图生成“会飞的企鹅”时,物理引擎会提示其违反物理规则,从而修正认知。
2. “模拟到现实的鸿沟”与“领域随机化”
在真实世界训练机器人成本高昂且危险,因此多数智能体AI都在模拟器中训练。但模拟器无法完美复刻真实的物理世界。
解决方案是 “领域随机化”技术。在模拟器中刻意引入各种极端干扰(如光照、材质变化),使智能体学习更鲁棒的特征,减少对特定环境的依赖。World Labs生成的高保真3D世界也旨在让模拟环境更逼真,促进能力从模拟器向现实世界的平滑迁移。
3. “长期规划和灾难性遗忘”
智能体在执行长时间任务时容易迷失目标或遗忘之前步骤。虽然向量数据库能存储记忆,但如何从海量记忆中精准提取信息仍是难题。此外,AI在学习新技能时,常会“遗忘”旧技能,这被称为 “灾难性遗忘症”。报告呼吁研究更先进的记忆管理机制,模仿人类大脑整合与遗忘记忆。
智能体AI的未来应用前景
智能体AI和空间智能的应用前景广阔:
- 医疗健康:智能体AI能分析影像、病历,辅助医生诊断,并能主动提问、建议检查,形成 人机协作的诊断闭环。在手术中,AI可构建患者3D模型,实时预测组织变形,指导手术机器人精确操作。但这需严格的检索机制和人类监督,以规避“幻觉”风险。
- 机器人领域:空间智能的机器人能理解“把桌上乱放的杯子收进洗碗机”这类泛化指令,自主识别物体、规划路径避障。这对于未来的 家庭服务机器人 至关重要。通过Marble生成虚拟厨房场景,让机器人自主“玩”强化学习,将彻底改变机器人训练方式。
- 游戏和内容创作:游戏开发者能用文字直接生成3D游戏关卡,大幅降低成本。World Labs的技术已能实现用一句话生成一个可交互的城堡。游戏NPC将拥有记忆、动机和行为逻辑,玩家每次互动都能永久改变NPC态度和游戏走向,实现真正的 “开放世界”体验。

伦理与安全:伴随智能体而来的挑战
当智能体走出屏幕,进入现实,其伦理风险将呈几何级数增长。
- 安全与控制:一个具身智能体若被恶意指令操控,可能造成不可逆的物理伤害。我们需要一套专门针对智能体AI的 “安全对齐标准”,不仅检测有害文本,更要预测和拦截有害的物理行动,建立一道“物理防火墙”。
- 数据隐私与监控:智能体需要时刻感知环境,摄像头、麦克风常开会引发巨大的隐私担忧。未来的家庭机器人是否会成为极致的监控设备?因此,如何在本地处理敏感数据,以及用户能否要求机器人“遗忘”某些场景,将成为新的法律议题。
结语:迈向有“身体”和“世界观”的AI
李飞飞团队的报告和World Labs的实践共同揭示了AI的下一个演进阶段:AI正在获得 “身体”和“世界观”。我们正处于从“大语言模型”向 “大动作模型”和“大世界模型” 过渡的关键时刻。这就像弥合了数字世界和物理世界之间的鸿沟,让AI真正成为物理世界的一员。
尽管挑战重重,但一个机器与人类在物理空间中协作共生的未来已不再遥远。对于研究者而言,完善“接地”机制、提升模拟器物理保真度是当务之急;对于产业界而言,掌握空间智能技术将赋予其定义下一代交互平台(如AR/VR、家用机器人)的权力。
李飞飞的“世界实验室”不仅在制造模型,更在为未来的AI打造一个可以栖息进化,拥有真实感知的 “新世界”。