
AI新纪元:英伟达与Groq,一场关乎“确定性”的秘密武器较量
在AI飞速发展的今天,我们正站在一个技术变革的十字路口。当“英伟达”与“Groq”这两个看似毫无关联的名字被放在一起时,一场关于AI推理未来的讨论便悄然展开。如果说英伟达是AI训练领域的“顶流巨星”,那么Groq则携带着一张颠覆性的“确定性”王牌,试图重塑AI推理的版图。
“确定性”:AI推理的新范式
想象一下,你正在与AI助手流畅对话,或者自动驾驶汽车在复杂路况中疾速穿梭。这些场景对低延迟和可预测性有着极致的要求。然而,我们当前赖以运行AI模型的GPU,虽在训练方面表现卓越,但在推理环节却常常面临“长尾延迟”的挑战。
“确定性不是什么概率、模糊、也许,而是板上钉钉、说一不二的确定性。”
Groq的核心竞争力,正是其提出的“确定性”架构。这并非天方夜谭,而是源于对传统AI芯片设计理念的反思与突破。它旨在消除AI推理过程中那些恼人的不确定性,确保每一个计算步骤都像工厂流水线般精准无误。

200亿美金收购传闻的深层含义
最近,坊间盛传英伟达将斥资200亿美元收购Groq。这笔惊人的交易如果属实,无疑是AI芯片领域的一颗重磅“原子弹”。它不仅是资本层面的博弈,更预示着AI推理旧有模式的终结。
“如果这事儿是真的,那绝对是给平静的AI水面投下了一颗原子弹。它不只是资本运作那么简单,它揭示了一个残酷的真相:我们现在AI推理的旧船,可能要沉了。”
英伟达的GPU,以其灵活性和通用性称霸AI训练市场。但在AI推理这个对速度要求严苛的战场,传统GPU为了兼顾各类任务而引入的动态调度、多级缓存以及网络不确定性等设计,反而成了制约性能的瓶颈。推理需要的是像上了发条一样,一步一个脚印,不带犹豫的精准执行。
Groq的“确定性”魔法:软硬件协同的革命
Groq的“确定性”架构,堪称AI推理领域的一股清流。它通过超级智能的编译器,将硬件的复杂性和不确定性都提前解决,让硬件成为一个忠实执行命令的“工具人”。这种看似“笨拙”的设计,实则带来了极致的稳定和高效。
它的秘密武器主要体现在以下两个方面:
1. 静态决策,周期级精确调度
Groq彻底改造了“静态”和“动态”的接口。传统的处理器在运行时动态决策指令路径和数据缓存,如同开车时遇到堵车才临时变道。而Groq则将这些决策全部前置到编译阶段。编译器如同拥有“千里眼和顺风耳”的超级大脑,提前规划好所有指令的路径、数据的流动,甚至精确到每一个操作的周期级时间。硬件运行时只需按计划执行,杜绝了任何犹豫和不确定性。
2. 透明化的软硬件接口
与传统芯片将内部细节“黑箱化”不同,Groq反其道而行之。它将硬件内部存储位置、数据流向、功能单元延迟等所有细节,毫无保留地暴露给编译器。这使得编译器能够“看透”硬件运行的一切,精确预测程序的每一步,确保数据在正确的时间出现在正确的位置。
这种设计理念带来了显著优势:
- 硬件简化:复杂且为应对不确定性而设计的动态调度器、预测器等组件得以移除,降低了硬件设计难度。
- 效率提升:精简后的硬件可容纳更多计算单元,大幅提升效率。
- 消除长尾延迟:彻底解决了偶发性、难以捉摸的卡顿问题。
- 功耗预测:能耗可精确预测,对于数据中心等追求极致能效比的AI应用而言,无疑是巨大福音。
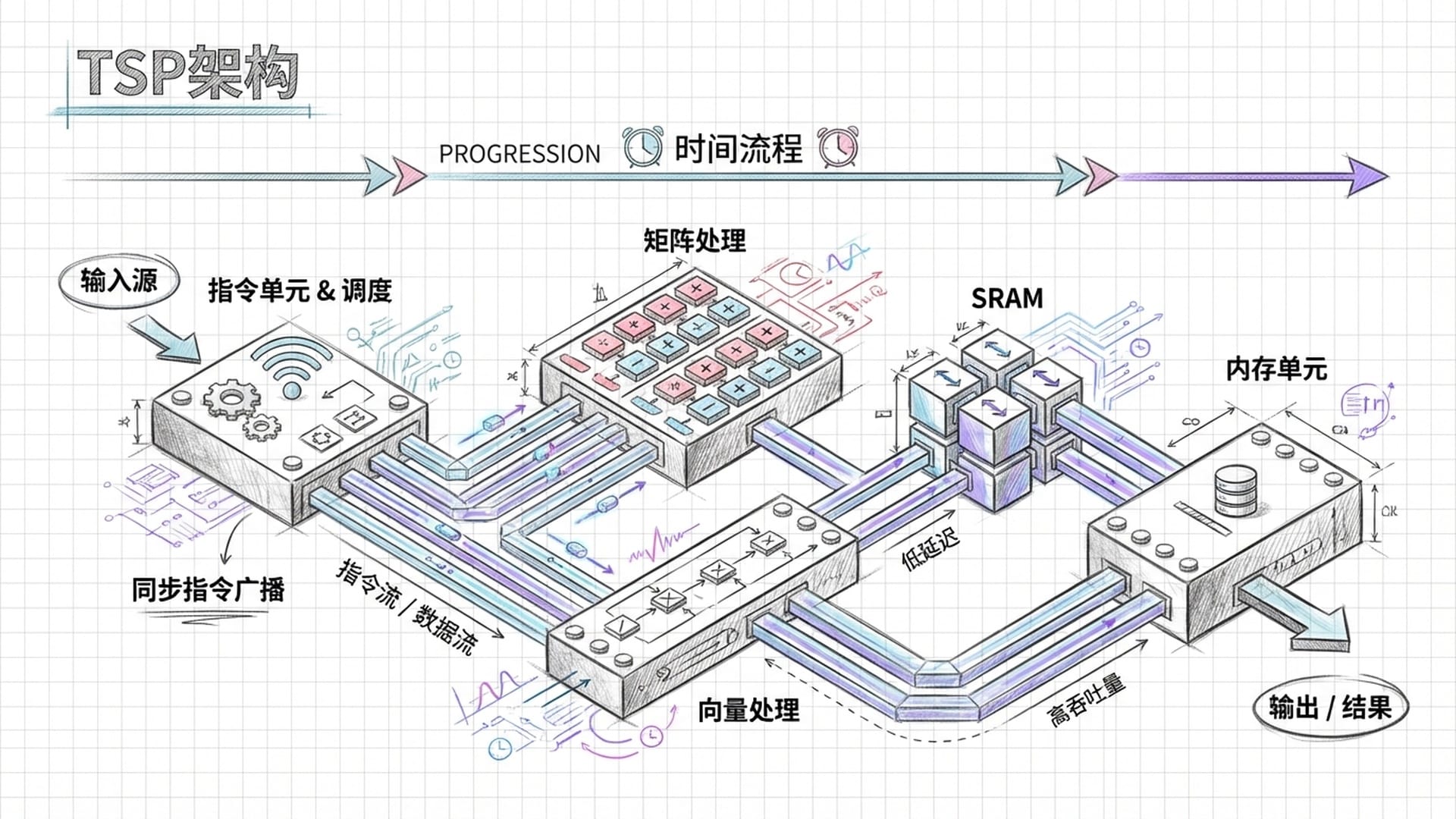
TSP架构:为确定性而生
Groq的芯片架构被称为TSP(Tensor Streaming Processor),专为确定性而生。它将传统的处理器五级流水线打散重组,在每个时钟周期,指令都会同步广播到芯片的各个功能切片,包括矩阵处理、向量处理、数据交换和内存单元。这种大规模并行处理方式,结合数据像“流水线”般固定流动,效率惊人。
在内存设计上,Groq摒弃了传统GPGPU的多级缓存,直接采用一个巨大的单层SRAM。这个SRAM的访问延迟是固定且确定的。编译器能够精确知道每一个张量(AI数据)的存储位置和访问时机,像一位精密的“排舞者”,将所有数据操作安排得井然有序,实现了内存访问的最大效率,避免了丝毫冲突。
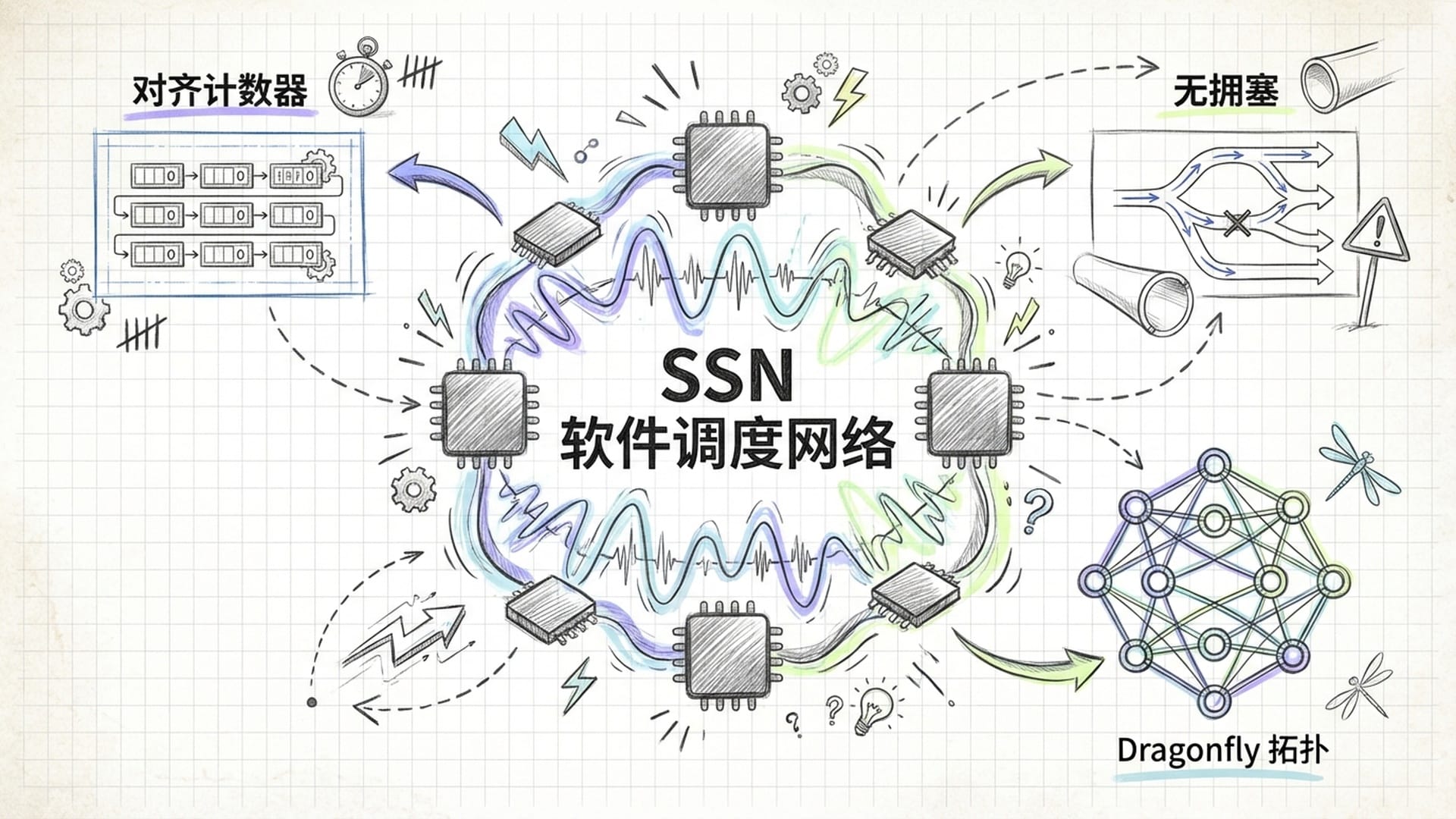
SSN:多芯片系统的确定性保障
即使在由多颗Groq芯片组成的系统里,“确定性”依然能得以保持,这得益于其独特的软件调度网络(SSN)。SSN在编译时便规划好所有芯片间的通信路径和时序,消除了运行时可能出现的网络拥塞和竞争。一切都按照精确的时刻表运行,如同火车准点发车,永不堵塞。
Groq甚至引入了“对齐计数器”以及DESKEW和RUNTIMEDESKEW等特殊指令,确保分布式系统在没有统一全局时钟的情况下,也能实现周期级的精确同步。
其Dragonfly网络拓扑设计,通过短而直接的连接路径,实现了超小的网络直径。编译器预知所有数据传输模式,并非简单“路由”数据,而是“调度”数据,将数据流分散到多条路径中,确保负载均衡,从根本上避免了传统网络中复杂的拥塞和死锁问题。
编译器的核心地位
Groq这套体系的真正“大脑”,正是其无比强大的编译器。它能将我们用PyTorch等高级框架编写的AI模型,分解为Groq自有的基本操作,并转换为硬件可理解的指令。其中最核心的挑战,也是最关键的工作,便是调度。编译器必须在编译阶段就解决所有数据依赖和资源冲突,生成一个精确到每一个时钟周期的执行计划。
这听起来像是一个不可能完成的任务,因为理论上这是一个NP难问题。但正因为Groq的硬件将所有细节都暴露给了编译器,使得编译器拥有了“上帝视角”,能够完整地“看透”硬件运行情况,从而进行更深层次的搜索优化,支持各种复杂的并行策略,如流水线并行、模型并行等。
英伟达为何青睐Groq?四大核心技术吸引力
作为AI芯片领域的霸主,英伟达为何会对Groq的“确定性”技术如此重视,甚至不惜重金求购?这背后是Groq在以下几个关键领域的独特价值:
- 解决GPGPU通信延迟高的问题:Groq的确定性SRAM内存和
Virtual Cut-Through网络转发机制,能将芯片之间、系统之间的数据传输延迟降到极低。这能极大优化英伟达GPU的集体通信效率,提升大规模并行计算的流畅度和性能。 - 引入“确定性”特性到英伟达架构:Groq在通信和同步机制上的确定性设计思想,如HAC、SAC以及明确的同步指令,能为英伟达的CUDA核心、Tensor核心和TMA模块之间的异步通信提供更高效的同步和协调机制,缓解恼人的长尾延迟问题。
- 优化CUDA核心架构:Groq将CPU流水线解耦、分散到功能单元的设计,以及320比特宽度的向量化处理等微架构思路,能为英伟达带来启发,以提升CUDA核心的PPA(性能、功耗、面积)。例如,增加类似Groq ICU的单元专门负责Warp调度和指令派发,让CUDA核心更专注于计算。
- 编译器技术的借鉴:Groq强大的编译器在静态图编译和分布式模型并行调度方面的能力,将对英伟达现有的编译器生态(CUDA Tile、Cute-DSL、Tilelang)形成巨大补充,特别是在处理大规模异构系统中的数据布局、内存访问和任务切分方面,Groq的经验可让英伟达少走弯路。
此外,在3D封装和可靠性方面,Groq通过编译器优化3D堆叠架构下的功耗、散热,及其基于确定性的纠错码和软件重放机制(RAS),对英伟达未来芯片设计,尤其是应对复杂封装挑战,具有重要的参考价值。
融合:通用性与确定性的平衡策略
英伟达在吸收Groq技术时,将面临如何在通用性与确定性之间找到最佳平衡点的巨大挑战。毕竟,CUDA生态系统的普适性是英伟达的核心竞争力。
未来的架构演进,很可能是在GPGPU架构的基础上,针对那些对延迟极度敏感的AI推理应用,引入更多类似Groq DSA的SRAM、明确的通信指令和软件调度网络。最终目标是打造一个既具备通用性,又能在特定场景下实现极致性能的“混合架构”。
如果此次收购成真,它将不仅仅是两家公司的合并,更是AI芯片领域的一个里程碑式变革。它向整个行业宣告:我们对低延迟、高吞吐、高可预测性AI推理的需求已经全面爆发,同时,也深刻认同了架构创新和软硬协同的巨大价值。
未来的英伟达芯片,可能不再是我们熟悉的那个“大力出奇迹”的GPU,而是一个兼具通用性和确定性的**“混合体”**,它将更加智能,更加高效,而且,更加“确定”!
