
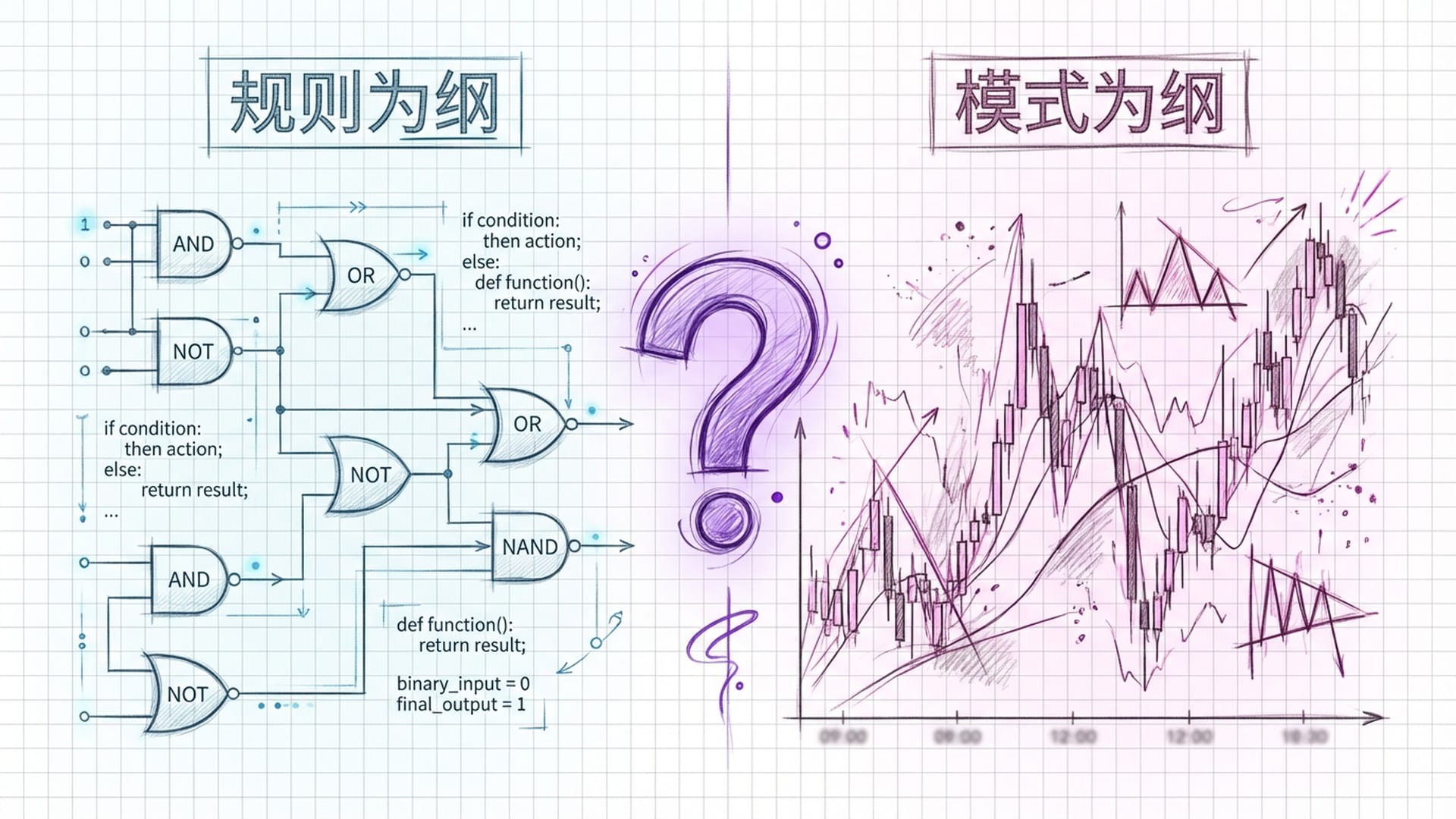
大语言模型(LLM)的崛起,让人们对其能力边界产生了无限遐想。从代码生成到文章创作,再到跨语言翻译,ChatGPT等模型展现出的“智能”令人惊叹。然而,当我们将目光投向波动莫测的金融市场,一个核心问题浮出水面:大语言模型究竟能否预测下一根K线? 许多人直觉上认为,K线图与自然语言一样,都是序列数据,预测“下一个词”和预测“下一根K线”似乎殊途同归。但这种看法,实际上是对AI能力和金融市场复杂性的双重低估。
编程语言有清晰规律,自然语言也有其内在逻辑,但K线,它只有模式,没有规则。这正是理解AI预测边界的关键所在。
规则与模式:混沌理论的视角
要理解语言与金融市场的本质差异,我们首先需要区分“规则”和“模式”。当前人工智能的核心突破在于“预测下一个词”。当我们输入“The quick brown…”时,模型能以极高的概率续写出“fox”。这种成功源于LLM对海量文本中概率分布的学习,它掌握了语言的构成性规则。
但是,将这种逻辑直接套用到K线预测,则无异于“看到蚊子会飞,就觉得它也能造火箭”一般荒谬。
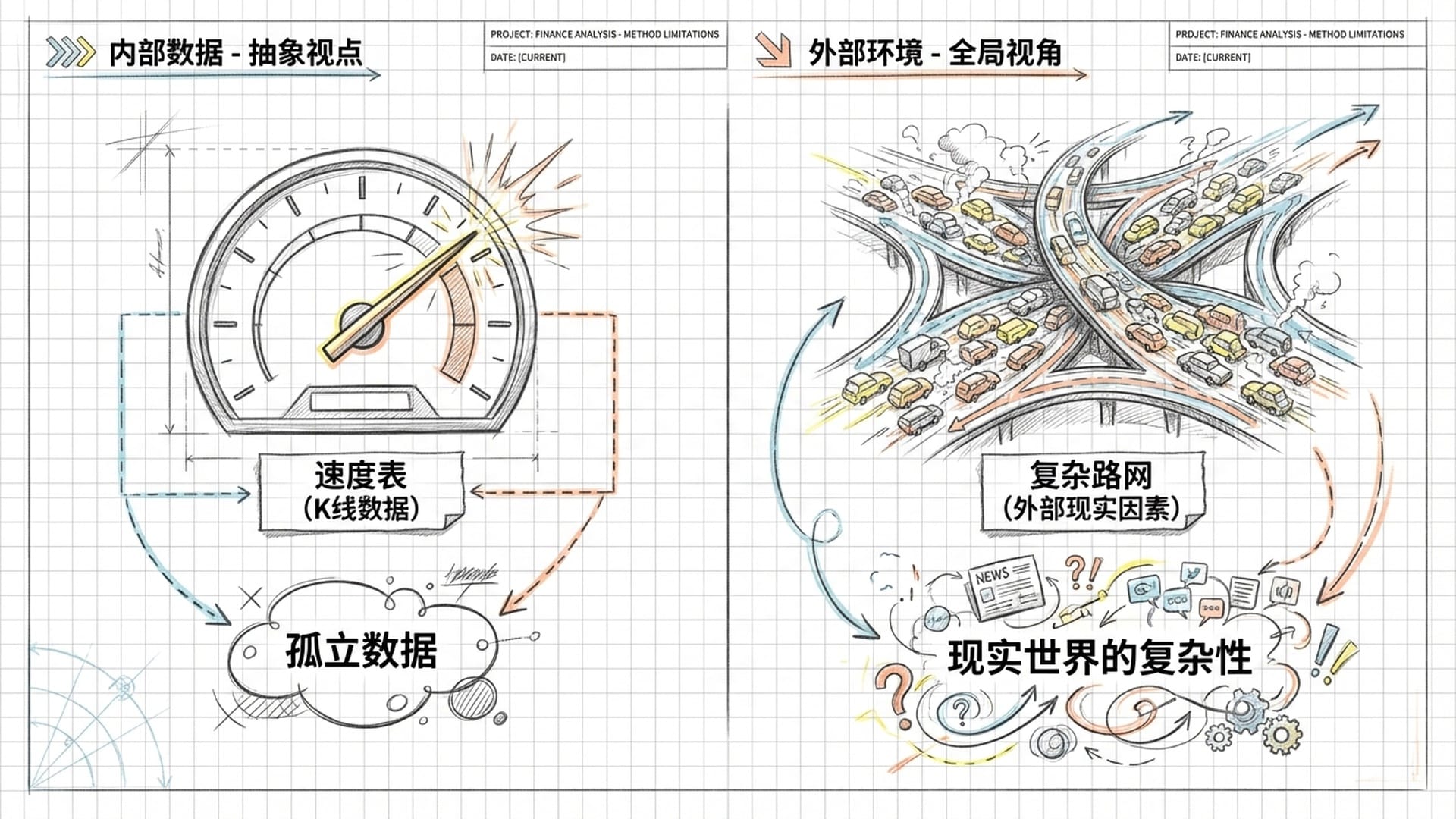
在自然语言处理中,词语的意义由上下文决定,如“苹果”可以是水果也可以是公司。其“基本真理”内嵌于语言结构之中。然而,金融市场的“基本真理”却外在于K线图。它与真实的经济活动、投资者的情绪、地缘政治等宏观因素息息相关,这些是单纯从K线图中无法完全洞察的信息。
我们可以将此比喻为:只看汽车的速度表,就想判断路上是否堵车。这忽略了至关重要的外部环境信息,是风马牛不相及的两件事。
律法系统、随机系统与预测光谱
世间万物系统大致可分为两类:律法系统和随机系统。编程语言是律法系统的极端,其由严格的形式逻辑定义。例如,Java代码中“{”后必然需要“}”,模型预测下一个 token 是右花括号的概率几乎是百分之百,因为它被规则强制要求。
自然语言虽比编程语言灵活,但也遵循语法结构。当你说“The quick brown”时,下一个词是“fox”,这不仅是统计结果,更是英语语法所要求的。
然而,金融市场不遵循这种构成性规则。K线图里从没有规定“三根阳线之后就一定要跟一根阴线”。所谓的“头肩顶”、“双底”等形态,仅仅是统计上的倾向性模式,而非语法上的必然。这正是“有模式无规则”的精髓所在。
AI在编程上之所以能得心应手,因为它处理的是确定性问题;而在金融交易中至今充满争议,因为它面对的是随机性问题。
为了更形象化地理解,我们可以想象一个“预测光谱”:
- 代码(左端):高结构、低熵值(不确定性低)。规则绝对,AI表现最强,下一个
token几乎唯一确定。 - 自然语言(中段):中等结构、中等熵值。规则(语法)弹性存在,预测基于相对稳定的概率分布。我们人类交流遵循合作原则,这使得语言具有可预测性。
- 金融市场(右端):低结构、最大熵值。无硬性语法规则,只有人类心理、宏观经济与随机冲击交织形成的模式。预测不再是恢复信息完整性,而是试图从混沌中寻找极其微弱的偏离。
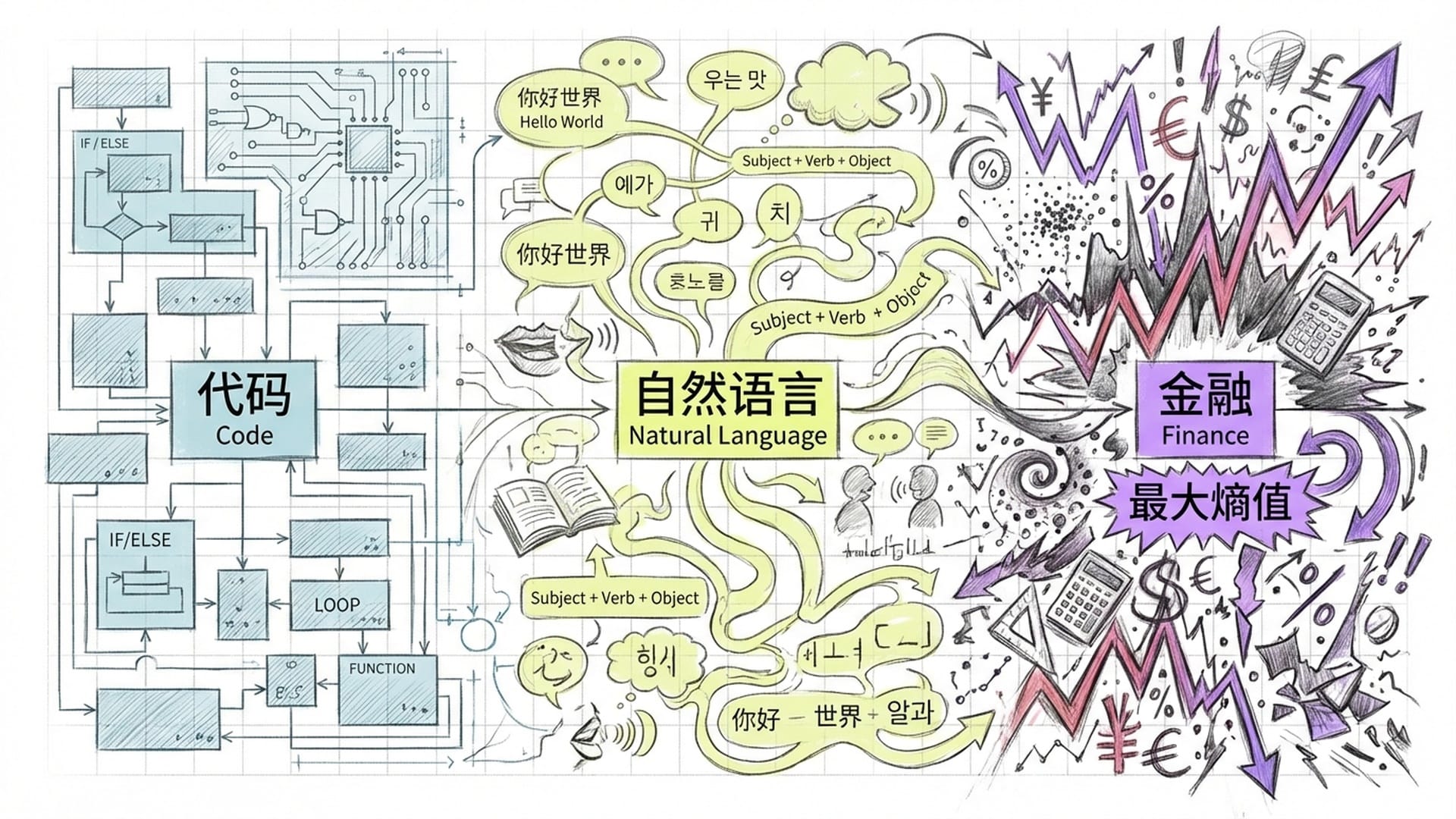
这解释了为何AI编程助手 Copilot 能迅速普及,而AI炒股至今仍备受争议。
语言与K线的统计学差异:平稳性与各态历经性
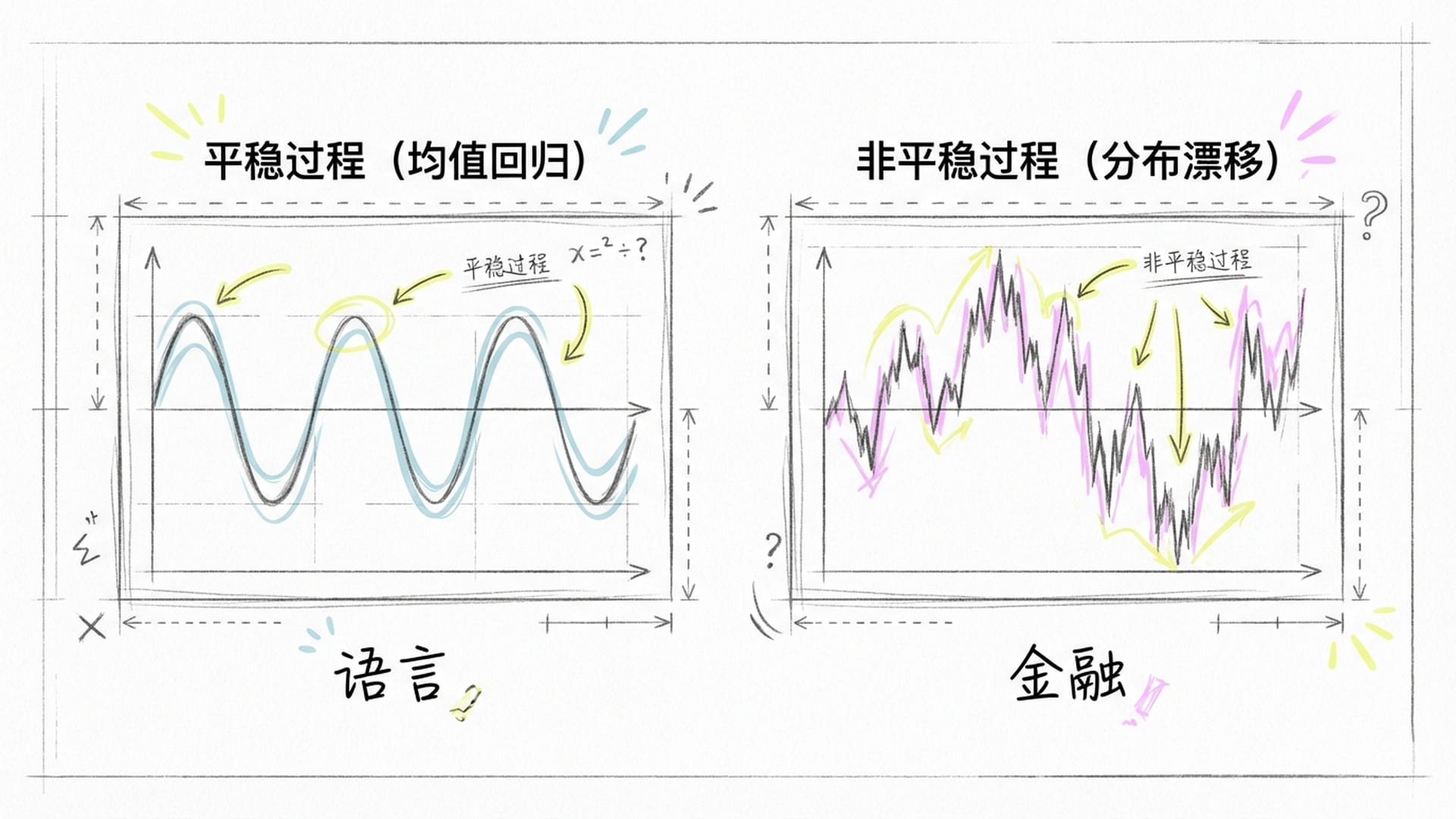
除了规则性质,语言和K线在统计学上还存在根本性差异,即平稳性与各态历经性。
平稳性是指一个随机过程的统计特性(如均值、方差、自相关性)不随时间改变。语言在长时间尺度上是近似平稳的,英语语法规则在百年间变化不大。因此,一个在2010年训练的LLM,到2024年依然能生成通顺的句子。
然而,金融市场是一个极其显著的非平稳过程。市场会发生“分布漂移”,2008年金融危机的市场特征与2017年牛市截然不同。在低通胀环境下训练的模型,拿到高通胀环境可能完全失效,因为市场的“语法”已经改变。
各态历经性指的是时间平均等于系综平均。语言可被视为各态历经的,足够大的语料库能覆盖绝大多数语言现象的概率分布。但金融市场非各态历经。单一资产的价格归零,与市场整体平均表现无关,市场中存在破产风险和黑天鹅事件。
这些数学属性的差异意味着:LLM在语言上的“推理”基于稳定统计规律,而在金融上的“预测”则是在一个不断变化的沙堆上建造城堡。
K线的数据转化与注意力机制
尽管本体论上差异巨大,技术界仍在努力将K线转化为LLM能理解的语言。LLM只能处理离散的词元,而K线数据是连续数值,必须进行离散化处理。
早期的尝试是直接将价格作为文本字符串输入,如“150.25”。然而,文本分词器会打乱数字的逻辑,导致模型无法理解数值大小关系。
目前的解决方案更为复杂:
StockTime:不再预测单个时间点价格,而是将一段连续时间序列(如10天K线)打包成一个“Patch”,映射到高维向量空间。模型预测的是“下一个Patch”,即未来10天的趋势,而非具体数字,以此保留局部趋势信息。Chronos:更激进地将连续价格数据强制映射到一组固定的离散“桶”中,如将所有价格变化分为4096个等级。这使得时间序列完全变成“语言”,可直接使用标准Transformer架构。
这种转化是有损的。量化过程会丢失微小的价格精度,而这些精度在金融交易中可能意味着巨大的滑点成本和亏损。
Transformer 的核心是注意力机制。在语言模型中,注意力机制指向语义依赖,如“The boy who holds the red ball is my brother”中“boy”和“brother”的依赖关系。这是一种逻辑和语法上的连接。在金融领域,注意力机制指向时间依赖,如预测今日股价时,模型会关注365天前(年线效应)、7天前(周效应)或昨日收盘价(动量效应)。因此,虽然算法代码相同,但模型学到的注意力模式截然不同:语言是结构性的,金融是周期性的。
二阶混沌与反身性理论
你提出的“K线历史有模式但没有规则”是一个深刻的观点,这涉及金融巨鳄乔治·索罗斯的反身性理论,它解释了金融预测为何会陷入“二阶混沌”。
预测天气和预测股市的区别,正在于一阶混沌与二阶混沌。
- 一阶混沌(如天气、语言):系统虽混沌,对初始条件敏感,但你的预测本身不会改变系统。气象学家预测下雨,雨云不会因为不想被预测而消散。
- 二阶混沌(如金融市场):系统不仅混沌,而且会因你的预测而改变。如果AI预测某股票大涨,投资者蜂拥买入,股价即刻上涨,反而透支了未来的涨幅,甚至改变了未来的走势。
这就是逻辑的断裂点。LLM预测词语,处理的是一阶系统;预测K线,处理的是二阶系统。K线之所以没有“规则”,是因为规则本身正被市场参与者的预测行为所不断改写。
索罗斯认为,市场价格并非基本面的被动反映,而是参与者认知功能和操纵功能之间的双向反馈回路。他指出:“市场参与者的思维与事态之间存在双向联系……参与者的偏见会改变基本面,基本面的变化又反过来加强偏见。”
这种反馈循环与语言的线性流形成鲜明对比:
- 语言的线性流:语法规则 → 生成句子 → 传递意义。这是一个相对线性的过程,语法规则是稳定的。
- 市场的环形流:价格 → 影响情绪 → 改变行为 → 改变基本面(如公司融资能力) → 改变价格。
在金融中,“输出”(价格)会改写“输入”(基本面)。例如,一只垃圾股因炒作股价上涨,公司利用高股价融资还债,最终可能真的成为基本面良好的公司。这种因果倒置在语言中极其罕见。LLM学习的是历史的静态切片,无法模拟这种动态的、自我指涉的因果重构过程。
有效市场假说与阿尔法衰减
你对“预测完全不靠谱”的担忧,触及了有效市场假说(EMH)的核心悖论。EMH认为,如果市场是有效的,任何可被预测的信息都已反映在价格中,因此价格变动必须是不可预测的、随机游走。
这再次体现了金融与语言的逻辑差异:
- 语言中:高可预测性是目标,我们希望沟通清晰。
- 金融中:可预测性是利润来源,因此会被迅速消灭。如果市场出现明显“语法规则”(如“三连阳必跌”),算法会迅速捕捉并利用,直至其失效。
因此,LLM在金融领域的训练面临西西弗斯式的困境:它越成功找到一个模式,这个模式未来有效性就越低,这称为阿尔法衰减。这与编程语言截然相反—— Copilot 越成功学习 Python,其预测就越准确、越稳定。
大模型的实战表现:TimeGPT与Chronos的案例
尽管存在诸多理论障碍,市场上仍出现了 TimeGPT、Chronos 等模型。它们在处理电力负荷、天气、交通流量等具有明显物理规律的数据时表现出色,因为这些数据具有较强的平稳性和周期性。
然而,在纯粹的金融价格预测任务中,其结果发人深思。独立基准测试显示,这些通用大模型在预测股票回报率时,往往不比传统的统计方法(如 ARIMA)或简单深度学习基准强,甚至在某些指标上更弱。
大模型在金融中“失效”的原因:
- 上下文窗口错位:LLM的上下文窗口有限,但金融市场具有“长记忆性”,今日价格可能受十年前宏观政策影响。标准
Transformer难以捕捉跨越数个经济周期的超长依赖。 - 分布外泛化失败:所有预测模型都假设未来与过去相似,但金融危机往往是“分布外”事件。大模型倾向于预测“正常”状态,在黑天鹅事件发生时往往反应迟钝或产生巨大预测偏差。
实证数据表明:AI在编程上的成功源于掌握了句法,而在金融上的挣扎则是因为它试图寻找不存在的定式。
结论:形式相似,本质对立
回到最初的问题:“预测下一个词和预测下一根K线,到底是不是同样的逻辑?”我的结论是:形式上相似,本质上对立。
- 形式上相似:两者都使用自回归数学模型,利用历史上下文,依赖高维向量嵌入。从代码实现角度看,它们是一致的。
- 实质逻辑上对立:
- 语言预测是重构规则:LLM之所以能推理,是因为语言背后有一套稳定、共享、构成性的规则。AI通过海量数据成功逆向工程了这套规则,因此预测可靠。
- K线预测是博弈预期:市场背后没有固定规则,只有流动的、反身性的心理博弈。K线是数百万交易者意图的“战争迷雾”。AI在这里学到的不是规则,而是历史上的“战术痕迹”。由于战术不断演变且会被对手反制,所以预测本质上不可靠。
你的判断——“编程语言因为其规律相对于自然语言更清晰,所以推理结果更可靠……而K线有规律但没有规则”——是完全正确的。
我们可以将不同系统归类:
- 编程语言:白盒系统 — 规则透明、确定、无二义性。
- 自然语言:灰盒系统 — 规则存在但模糊,具有一定的容错性。
- 金融市场:黑盒系统 — 规则不可见,甚至规则本身是动态生成的。
因此,LLM即便能预测K线(且概率优于随机猜测),也永远无法达到AI在编程或写作上的那种“理解”和“推理”水平。在金融领域,AI的角色不是预言家,而是一个以极快速度处理信息的分析师。它能捕捉微小的统计套利机会,但无法像理解“主谓宾”那样,理解“涨跌停”背后的深层含义。
最终,预测下一个词,是在填补信息的缺失;而预测下一根K线,则是在对抗市场的高效。这正是两者逻辑的根本鸿沟。理解这一点,你就看懂了未来AI的真实边界,以及我们在金融市场里,真正可以依靠的是什么。