

同样一本书,为什么有人读完只是点点头,有人却被彻底改变了?
这个问题的答案,藏在2025年最新的神经科学研究里。
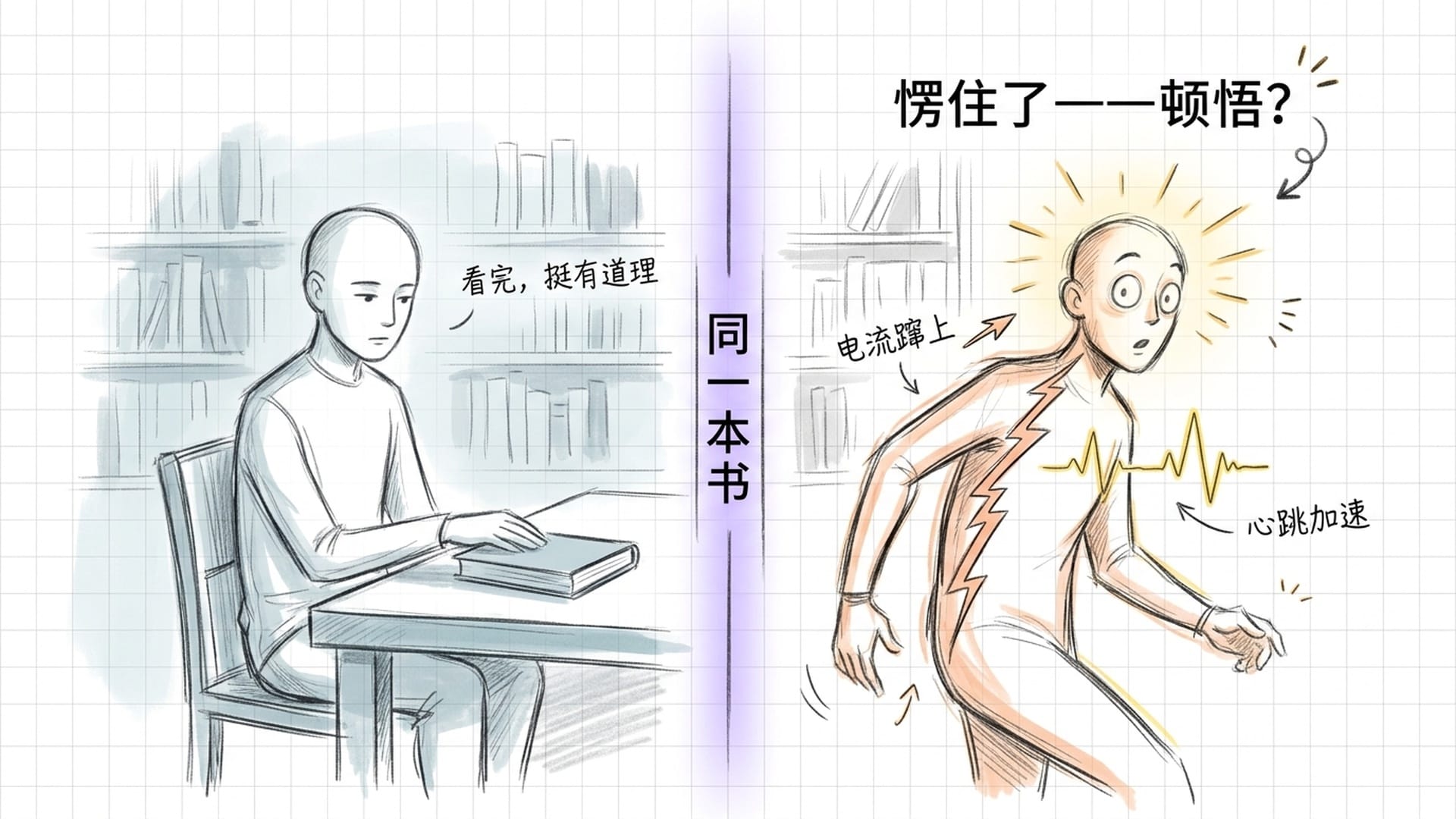
设想这样一个场景:两个人读同一本书。第一个人读完,说"挺有道理的",然后把书放下,继续过自己的日子。第二个人读到某一页时突然愣住了——心跳加速,瞳孔放大,一种电流从脊椎底部蹿上来直达头顶。他放下书,闭上眼,觉得自己好像突然看懂了一些以前怎么都想不通的事情。从那天起,他变了。
两个人之间的差距,我们通常用一个词来概括:悟性。
但悟性到底是什么?是基因决定的天赋,是智商的另一种说法,还是一种可以主动训练、不断提升的能力?
本文最核心的结论先说出来:悟性的高低,本质上不取决于你的大脑有多聪明,而取决于你的大脑有多愿意被改变。
顿悟,在大脑里究竟发生了什么?
2025年5月,柏林洪堡大学、汉堡大学与杜克大学的联合认知神经科学团队,在《自然·通讯》上发表了一项重要研究。他们设计了一个巧妙的实验:让参与者躺在核磁共振仪里,观看一种叫做 Mooney图片 的视觉素材。
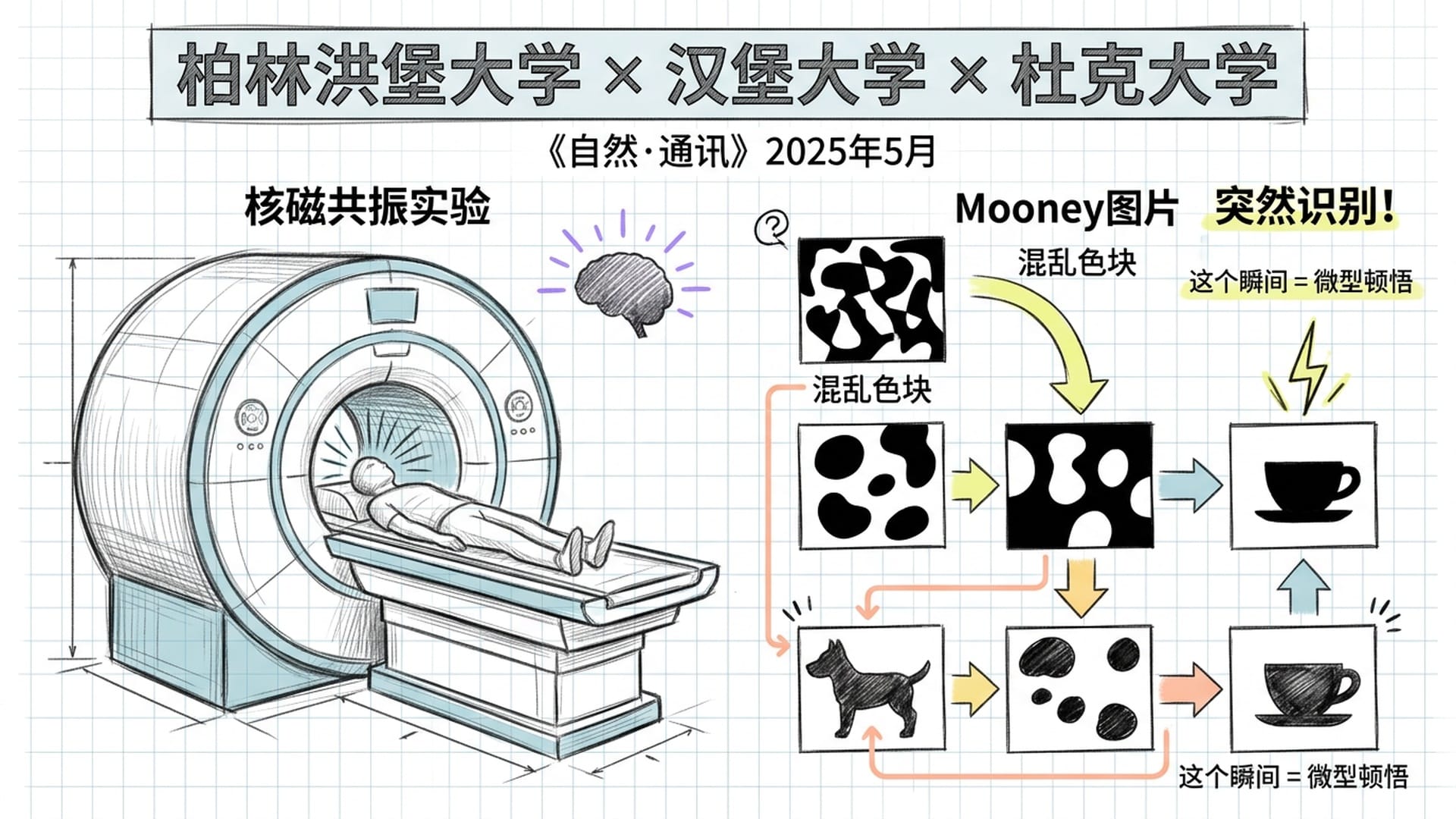
Mooney图片 是把普通照片的对比度拉到极端,变成纯黑纯白的色块。你第一眼看上去完全是一团混乱。但在某个瞬间,大脑突然将碎片拼合起来——你看到了一只狗,或者一个咖啡杯。这个瞬间,就是一次微型的顿悟。
实验得出了三个关键发现。
第一,顿悟瞬间发生了「表征重组」。 顿悟的那一刻,参与者大脑视觉皮层的神经元激活模式,发生了结构性的整体切换,而不是在原有模式上做微调。这不是渐变,是突变。用一个类比来说:不是把收音机的音量调大了一格,而是整个换了一个频道。
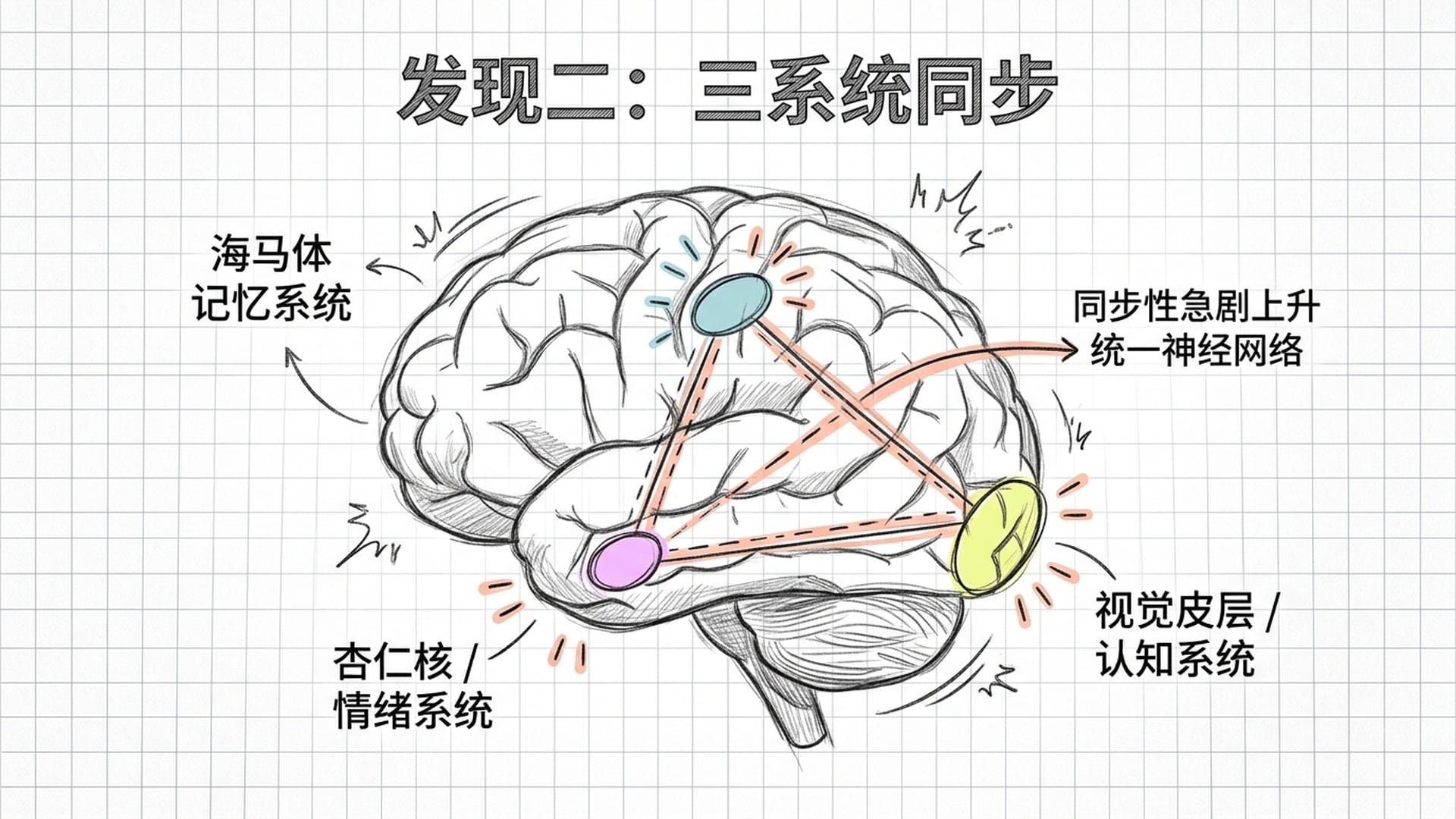
第二,认知、情绪与记忆三系统同时开火。 表征重组发生的同时,大脑的海马体(负责记忆)和杏仁核(负责情绪)被强烈激活,它们与视觉皮层之间的同步性急剧上升,形成了一个统一的神经网络。这解释了为什么真正的顿悟往往伴随着强烈的情绪体验——那不是"感觉上很爽"的副产品,而是神经机制本身的一部分。
第三,顿悟带来的记忆持久度,是渐进式学习的近两倍。 Cabeza教授的原话是:"如果你在学习某样东西的时候经历了一次顿悟,你的记忆力几乎翻倍,几乎没有什么记忆效应能比这个更强大了。"
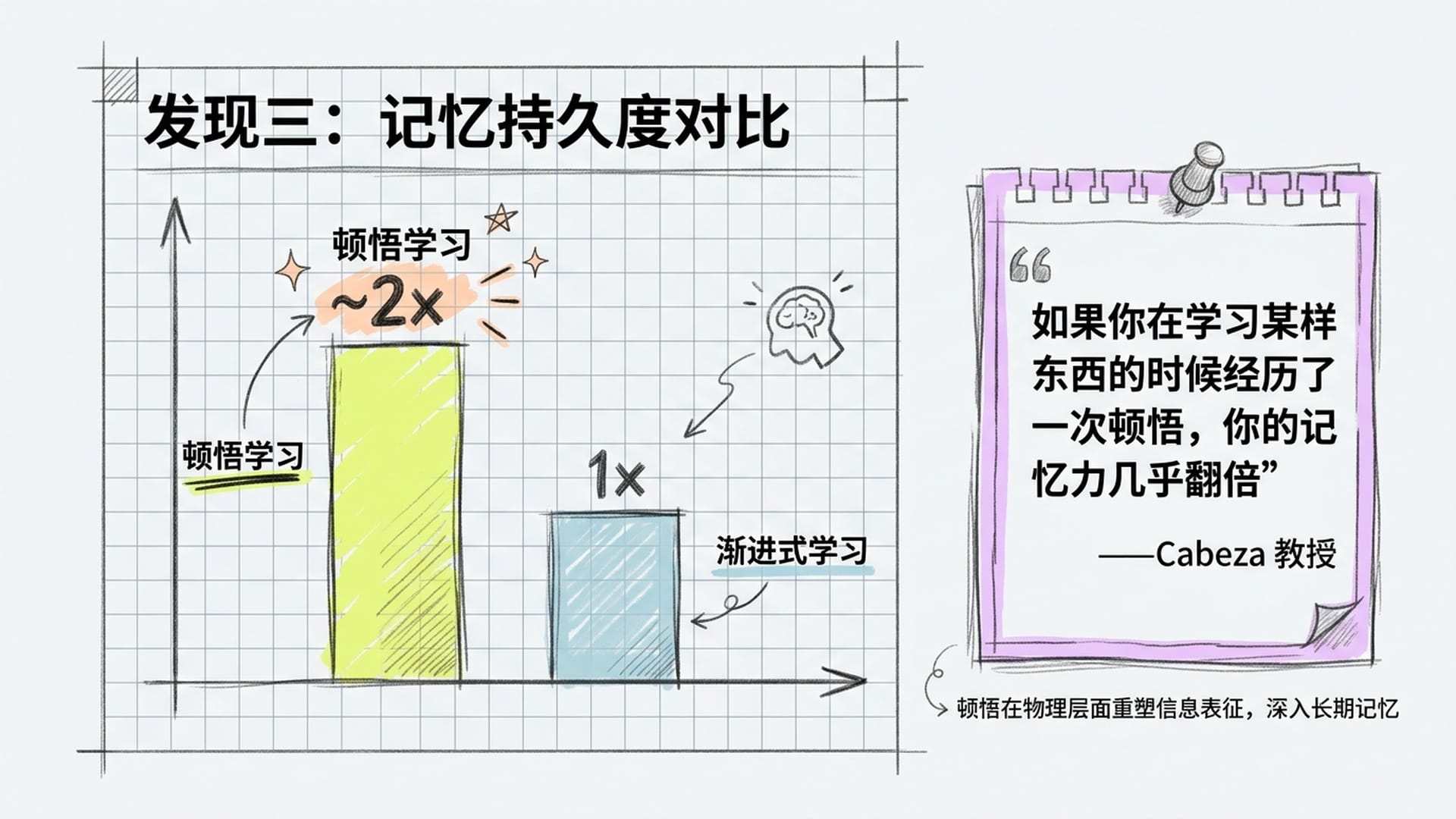
这意味着顿悟不只是一种主观感受,它在物理层面重塑了大脑的信息表征方式,并将这个新的表征深深烙入了长期记忆。
用「预测编码」框架理解顿悟
要真正理解这三个发现的深层含义,需要引入预测编码框架。
你的大脑不是被动的信息接收器,而是一台主动的预测发生器。就像大语言模型一样,它时刻在自上而下地生成对世界的预测,感官数据只传回预测与现实之间的差值——即预测误差。而每一个先验信念都带有一个精度权重,大脑对这个信念有多确信,这个权重就有多高。
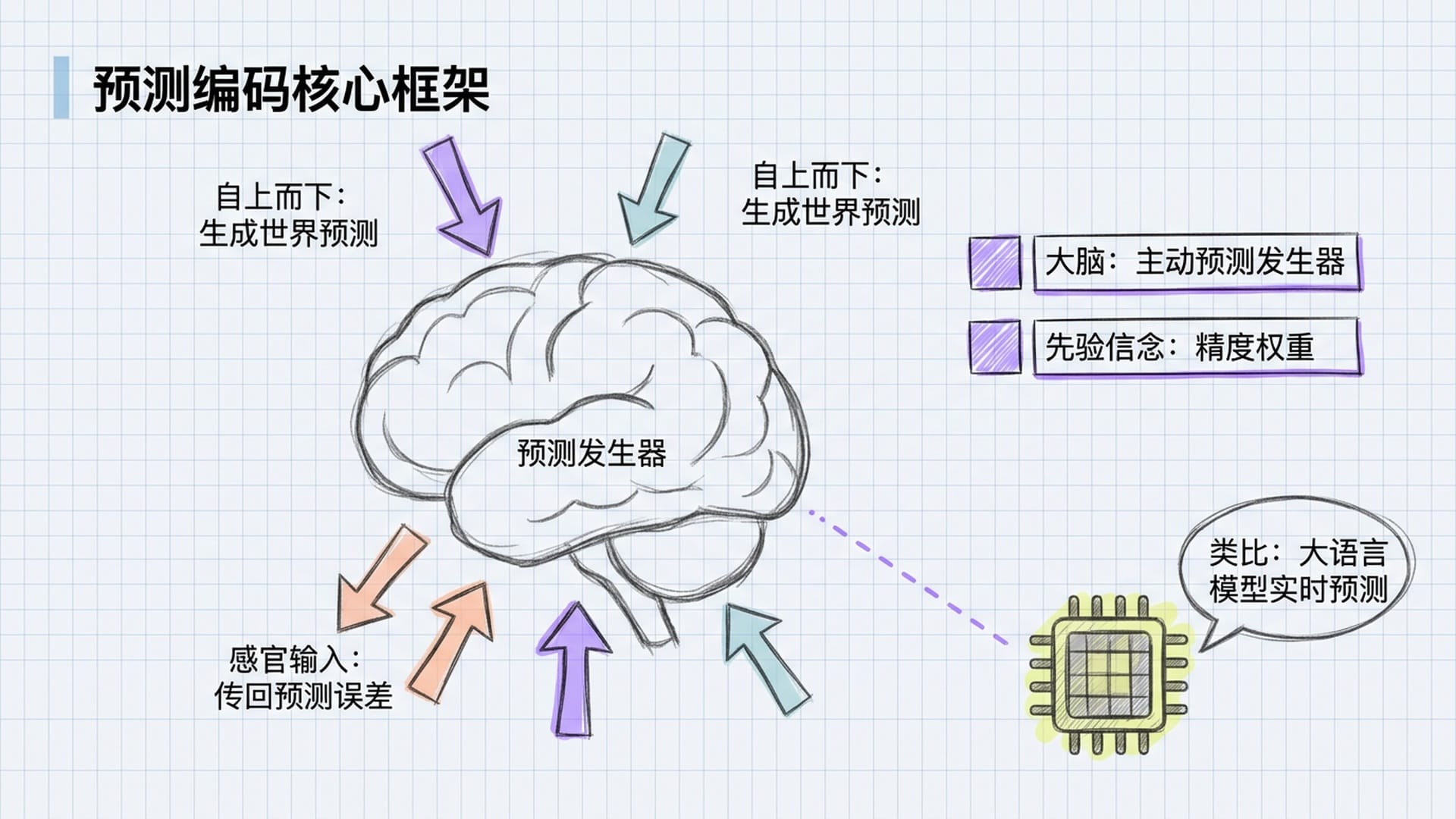
在这个框架里,顿悟的定义变得无比清晰:
顿悟,就是一次大规模的先验信念更新事件。
当你盯着那张 Mooney图片 时,大脑用旧的先验信念去解读它——这是一堆随机的黑白色块。这个先验生成的预测与实际视觉输入之间存在巨大的预测误差。误差信号一直累积,在意识察觉不到的地方,持续冲击着旧模型的墙壁。
然后,在某个临界点,墙塌了。一个全新的先验信念——这是一只狗——突然涌现。新模型一举消除了绝大部分预测误差。误差的瀑布式下降触发多巴胺释放,这就是那股快感的来源。与此同时,海马体将这整个涌现过程连同情绪状态一起打包,存入长期记忆。
这与物理学里的相变,在逻辑上完全一致。
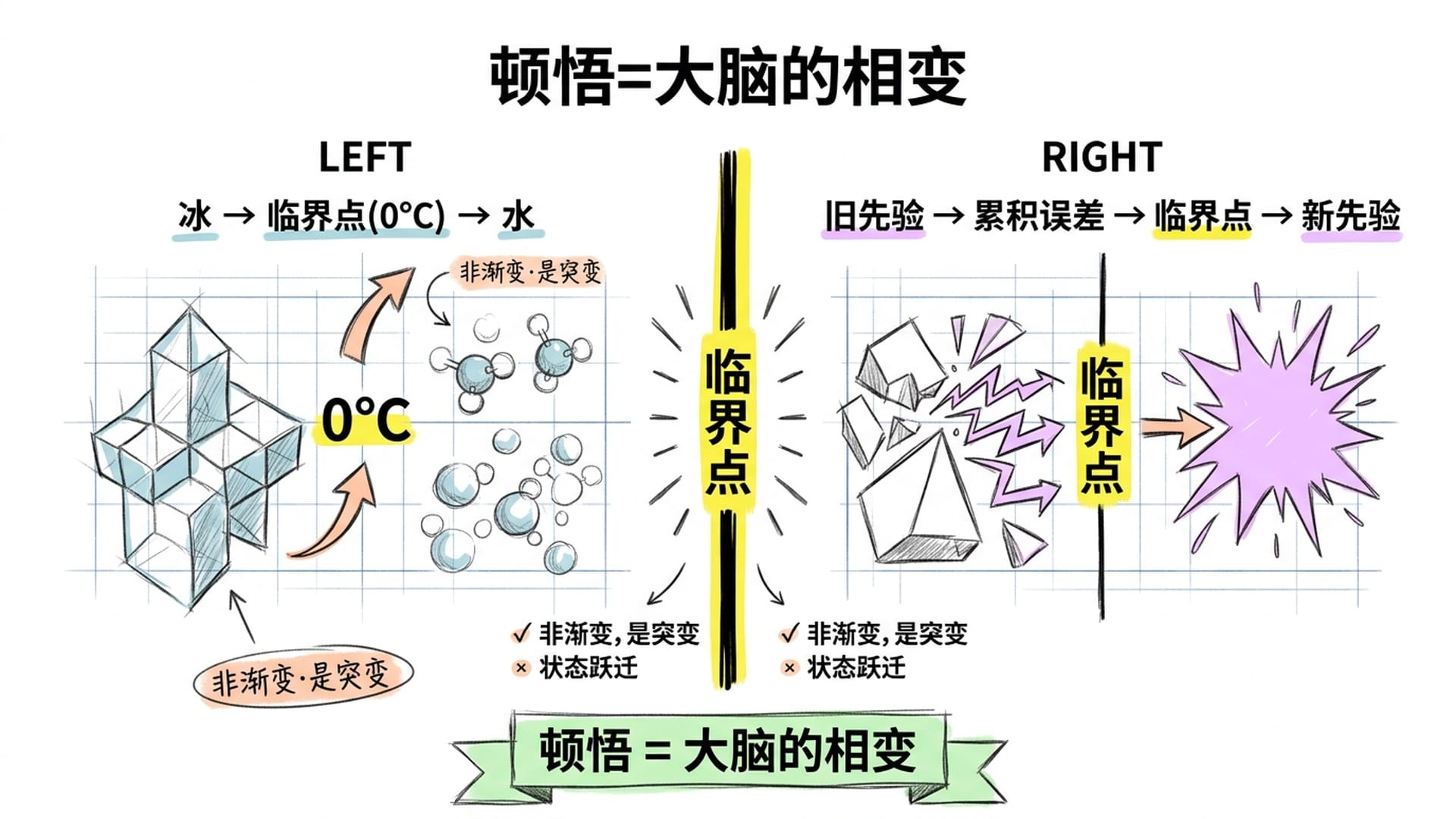
水在零摄氏度以下是冰。你给它加热,温度一度一度地升高,内部结构在微观层面缓慢积累变化,但从外部看,它还是冰。直到零度的那一瞬间,相变发生了——冰不是慢慢变成水的,而是在临界点上突然跳到了全新的状态。
顿悟,就是大脑的相变。
有趣的是,AI领域的 Grokking 现象与此在数学上几乎完全一致:神经网络训练初期只是死记硬背,误差曲线缓慢下降;但积累到某个临界点之后,误差悬崖式下跌,模型突然"懂了"背后的通用规则。那个"悟",在数学上就是参数在高维空间里从混乱状态坍缩成了一个低熵的几何结构——与大脑表征重组,是同一现象在不同尺度上的表达。
悟性高,究竟意味着什么?
理清了顿悟的机制,悟性的定义也随之清晰:
悟性高,不是说你相变的结果比别人好,而是说你的大脑到达临界点的阈值比别人低。 同样的信息输入,你的大脑更容易发生相变。
而决定这个阈值高低的,正是精度权重。
一个人的旧先验信念精度权重越高,大脑就越不愿意更新它。即使收到大量预测误差信号,大脑也会倾向于"解释掉"它们,而非更新信念。这就是为什么固执的人很少有顿悟——他们的先验权重太高了,高到预测误差信号根本穿不透。
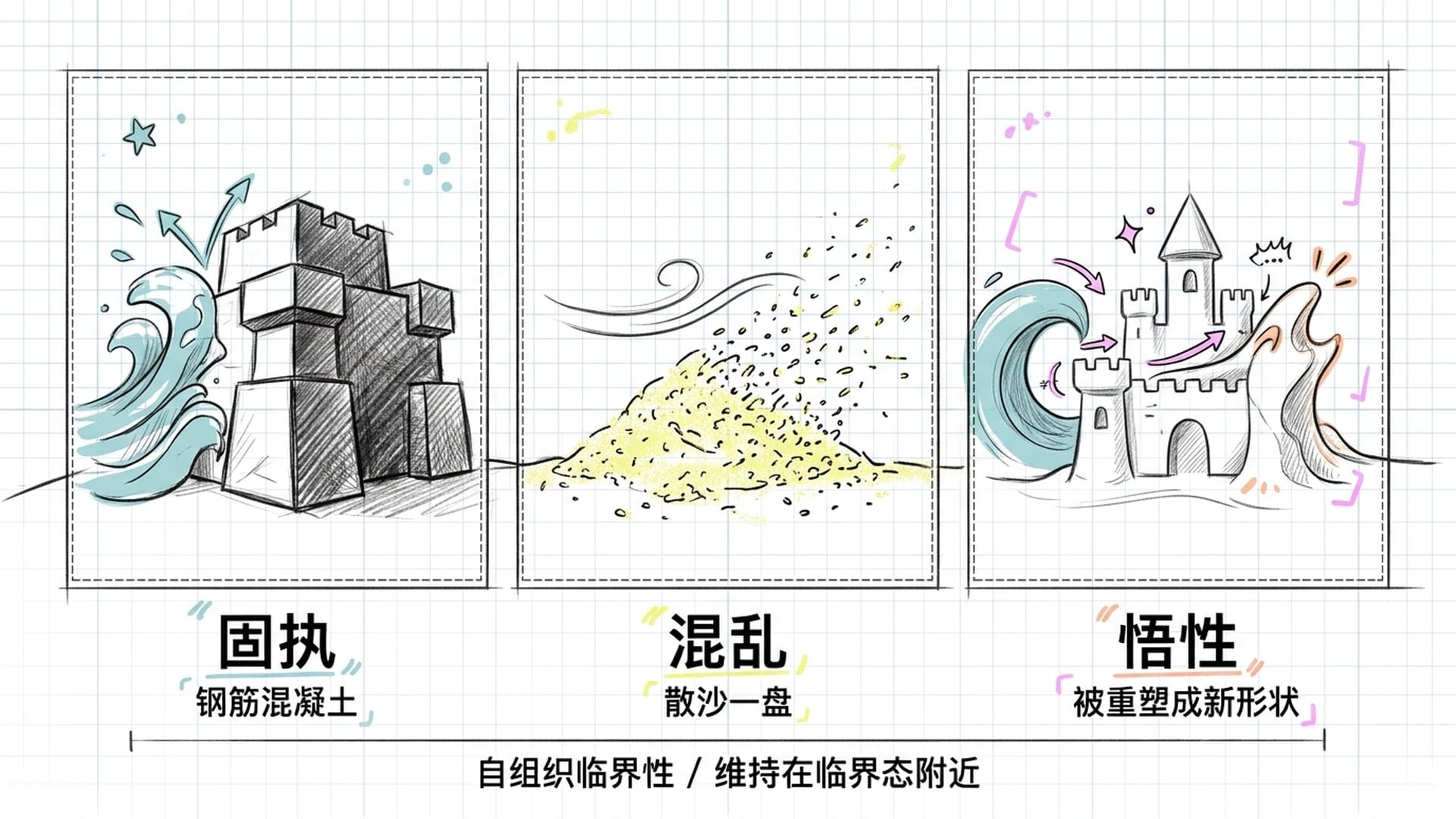
想象用沙子堆了一座城堡。如果是钢筋混凝土浇筑的,海浪拍过来毫发无损——那是固执。如果是散沙一盘,风一吹就没了——那是混乱。悟性,是沙堡刚好站着,但海浪来的时候,它愿意被重塑成新的形状。
这与物理学中的自组织临界性完全一致:复杂系统在临界态附近,最容易产生大规模的级联反应。沙堆太平坦,加一粒沙什么都不发生;沙堆太陡峭,已经崩过了处于稳定态;只有刚好处于临界点,一粒沙就能引发雪崩。
悟性,就是你的认知系统维持在临界态附近的能力。
这也解释了为什么六祖慧能听到应无所住而生其心这八个字就开悟了。同样的八个字,你也读过,为什么你没开悟?不是智商不够,而是你的认知沙堆还没堆到临界点。慧能在听到这句话之前,他的人生经历、内在探索、对痛苦的直面,已经把他的认知系统推到了悬崖边缘。八个字落下,只是最后那粒沙。
如何主动提升悟性?四个层面
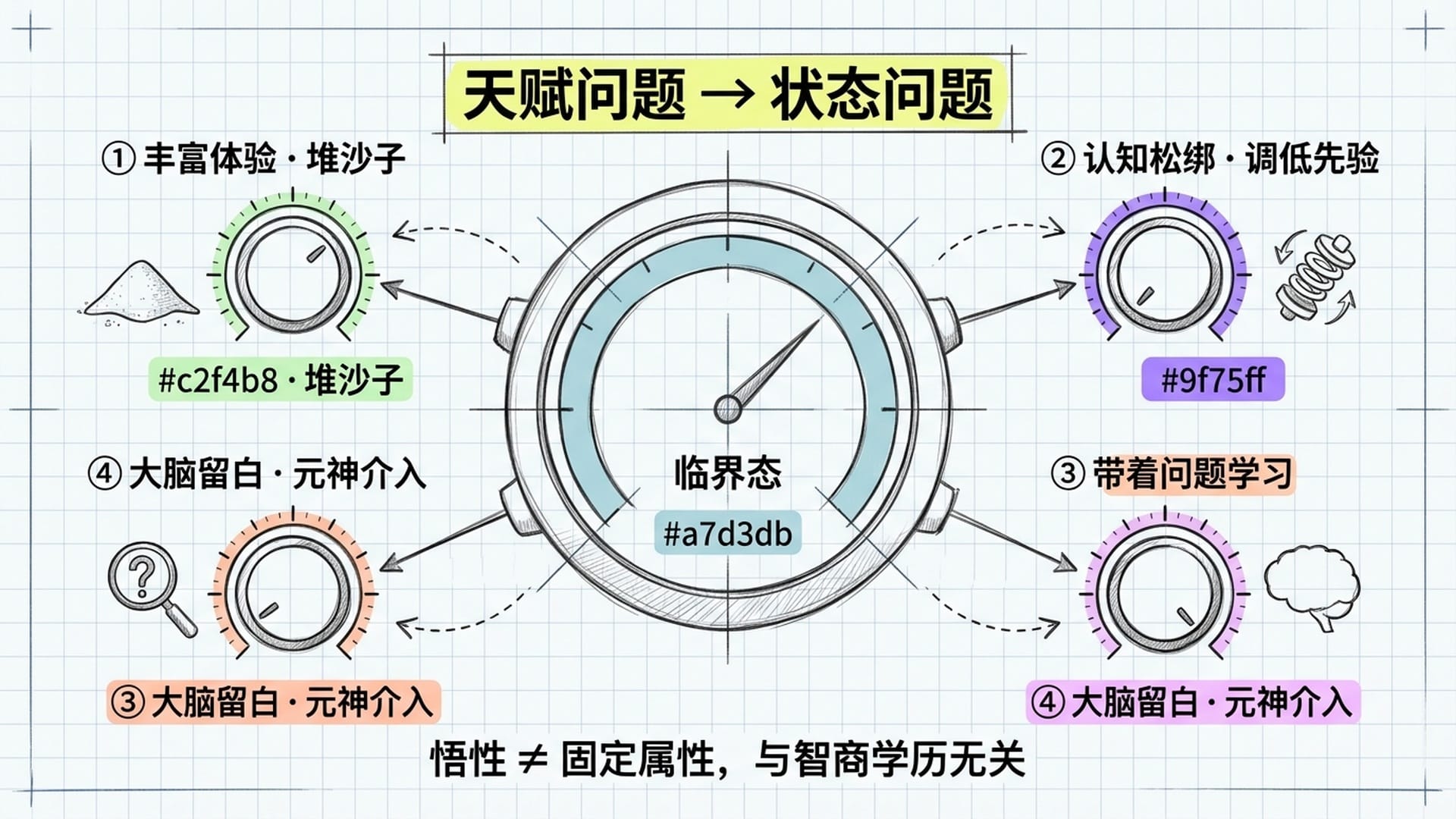
如果悟性的本质是认知系统在临界态附近的灵活性,那这个状态是可以主动调整的。以下是四个层面的实践路径。
第一层:堆积沙堆,扩展体验维度
认知沙堆越高、越多维,就越接近临界点。读书、旅行、与不同领域的人深度对话、学习全新技能、乃至经历重大挫折,都在往沙堆上加沙子。
但这里有一个陷阱:如果只在同一个领域堆沙子,沙堆会变得很高但很窄,在那个方向上早已越过临界点,再加沙子也不会引发雪崩。真正有效的做法是跨维度堆沙子——你懂物理学,也读佛学,还做过投资,研究过大语言模型,还亲手写过代码。来自完全不同领域的认知堆在一起,更容易把系统推到临界态。历史上最伟大的顿悟,往往正发生在学科交叉的地方。
第二层:调低精度权重,练习认知松绑
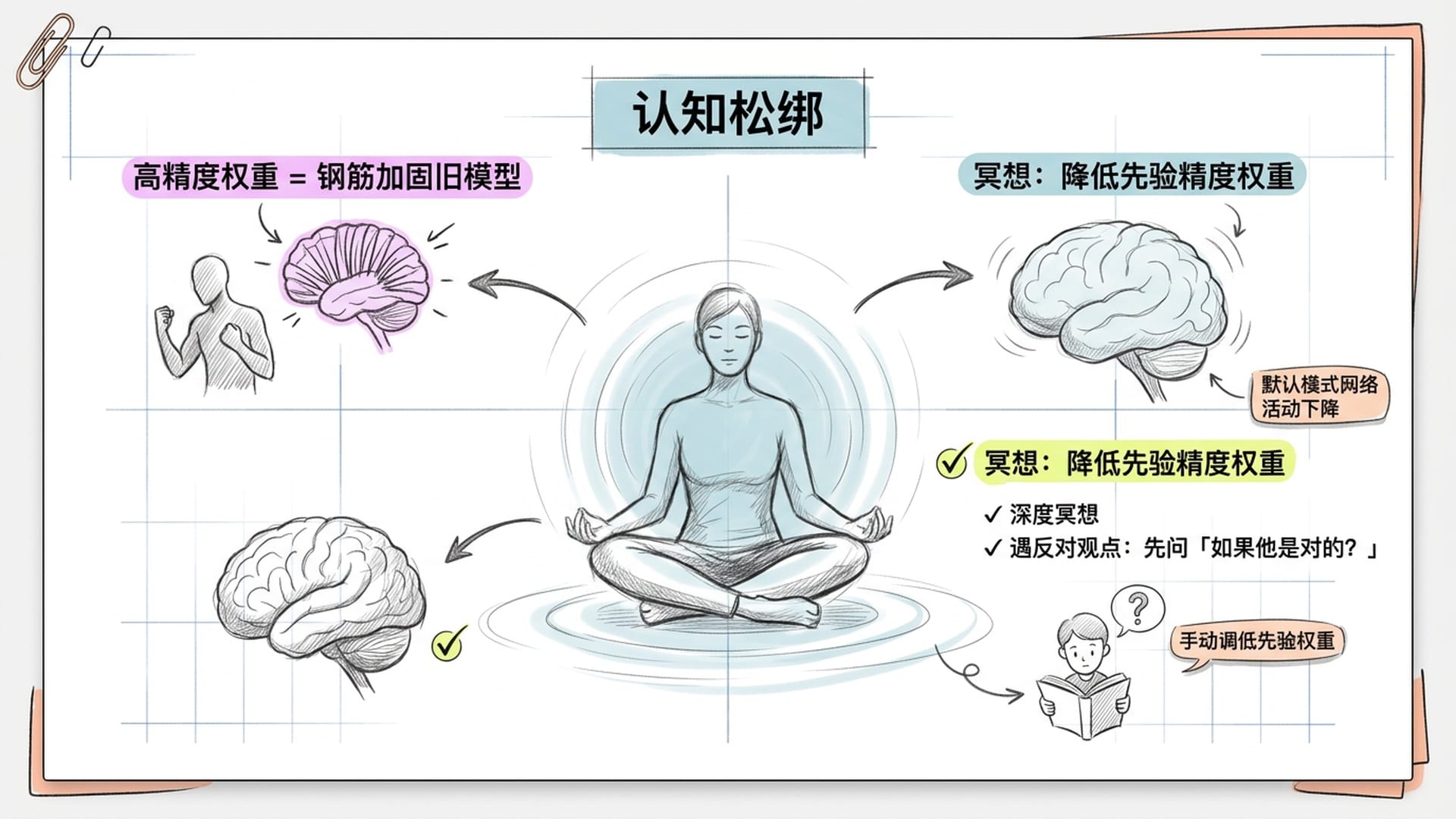
试着感受一下:你此刻最坚定的一个信念是什么?当你去审视它的时候,是否注意到身体有一个微妙的紧缩,好像有什么东西被威胁到了?那个紧缩,就是精度权重在身体上的表达。
过高的精度权重像钢筋一样加固了旧模型,让新的预测误差信号打不进来。降低它的有效路径包括:深度冥想(大量神经影像学研究证实,冥想能降低大脑高层先验信念的精度权重,使大脑进入更开放、灵活的状态),以及面对反对观点时的主动练习——不是急于反驳,而是先问自己:"如果他是对的,我的模型哪里需要修改?" 这个简单的问题,就是在手动调低先验权重。
第三层:增加预测误差的信号强度
宇航员在太空看地球之所以能引发总观效应,是因为那个视觉刺激的精度权重被拉到了最高——全感官沉浸、生存性情境加持、没有任何注意力竞争。同样的画面在电视上看,精度权重极低,根本打不动先验信念。
这对学习的启示是:你获取信息的方式,和信息本身同样重要。 同一本书,在沙发上随便翻翻,与带着一个烙在心里最深处的真实困境去读,大脑赋予它的精度权重完全不同。带着真实的困惑、真实的需要、甚至真实的痛苦去接触一段内容,大脑从神经机制层面就会更认真地对待这些输入。这就是为什么带着问题学习比泛泛而学有效得多。
第四层:让元神介入
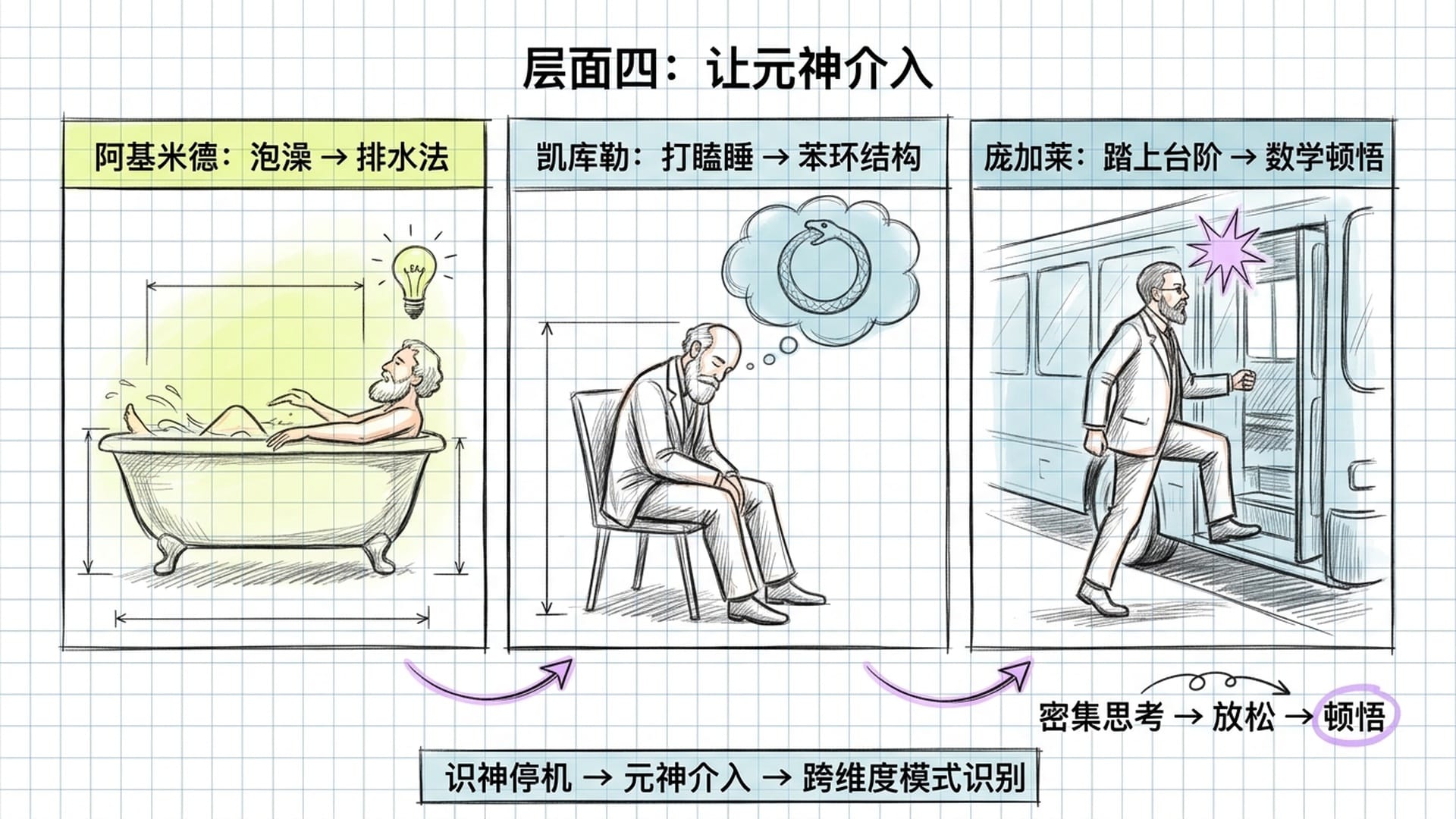
这是最深的一层,也最反直觉。
道家所说的识神,是那个不停说话、不停分析、不停判断的线性思维系统;而元神,是当所有噪音平息之后才浮现的更深层觉知——全局性的、直觉性的,能在高维空间里同时看到所有连接。
阿基米德在泡澡时想到了排水法;凯库勒在打瞌睡时梦到了苯环结构;庞加莱在踏上公共汽车台阶的那一瞬间解开了数学难题。这些故事都指向同一个模式:密集的思考阶段之后,一段放松或走神的阶段,顿悟突然涌现。
用预测编码框架翻译:识神在前期拼命堆沙子、积累预测误差,但精度权重太高,旧模型一直没崩。然后识神暂时停机了。这时默认模式网络的独裁控制松动,元神有机会介入,完成识神做不到的事——一次跨维度的模式识别,一次整体性的表征重组。
顿悟往往在放松时出现,不是因为放松本身产生了答案,而是因为放松让识神让出了带宽,让元神终于有机会与更深层的智慧连接。
因此,散步、发呆、洗澡、听音乐、做不需要动脑的体力活,这些看似"浪费时间"的事情,恰恰是在给元神创造介入的窗口。
悟性不是天赋,是状态
悟性这个词长期以来被当成一种固定属性,要么有要么没有。但用预测编码和相变理论重新理解悟性之后,会发现这根本不是天赋问题——它是状态问题。
你不是有没有悟性,而是此刻的认知系统是否处在临界态附近。悟性与智商和学历的关系,甚至可能是负相关的——智商和学历太高,反而容易产生佛学所说的所知障,让先验权重高到密不透风。
佛陀说众生皆有佛性。用今天的框架来理解,这句话的意思是:每一个人的认知系统,都天然具备发生相变的潜力。临界点永远存在,沙堆永远可以继续堆,精度权重永远可以调。
问题只在于:你愿不愿意让自己的旧模型被打碎,愿不愿意承受那个相变前夜的混乱与不安?
最深刻的顿悟,往往发生在最痛苦的时刻。不是因为痛苦本身有什么神圣的,而是因为痛苦是最强的预测误差信号,它在用最高的精度权重告诉你:你现在的模型,错了。
你愿不愿意听?
如果这篇文章引发了你的什么想法,或者你有过自己的顿悟时刻想要分享,欢迎在留言区写下来。你的故事,可能恰好就是另一个人认知沙堆上的那最后一粒沙。