

AI的残酷真相:从“内存墙”到“基建狂魔”
我们对人工智能的认知,是否仍然停留在“代码、算法和算力”的层面?一个不为人知的“内存墙”正在悄然重塑整个AI产业,它不仅驱动着技术创新,更影响着科技巨头的战略布局,甚至改变了并购的游戏规则。从2023年到2026年,AI的世界正经历着一场从概念炒作到基础设施建设的深刻变革。
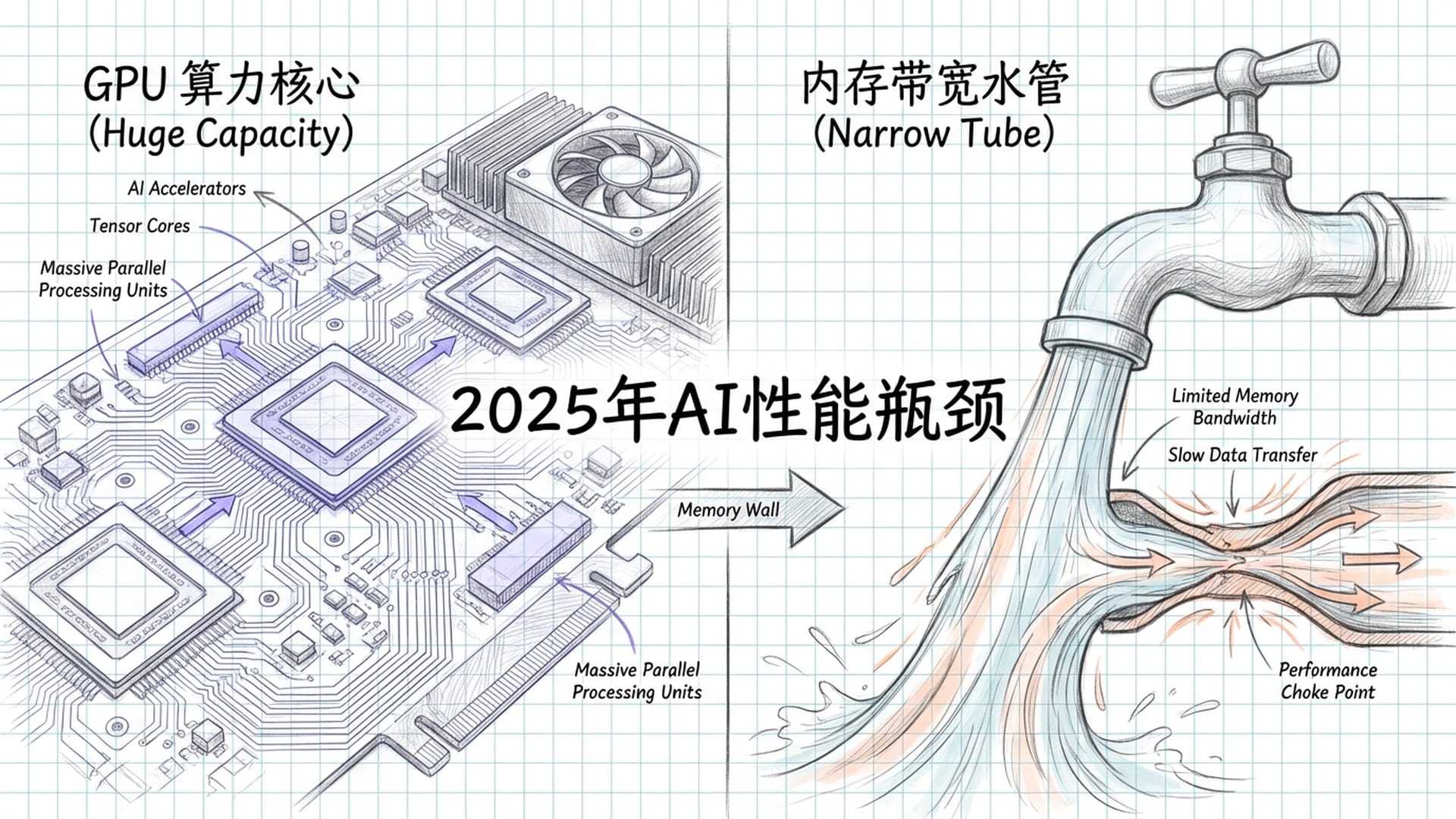
“内存墙”:AI性能的隐形瓶颈
你或许会认为,AI的竞争核心是强大的算力,GPU的性能决定了一切。然而,到了2025年底,业界普遍意识到,真正的限制并非CPU的运算速度或GPU的核心数量,而是内存带宽。
“这就像你家水管,水龙头开多大都没用,水管口径就那么点儿。”
数据从存储单元到计算单元的传输路径,正是这道看不见的“内存墙”。因此,近年来所有的技术创新,都围绕着如何突破这道瓶颈展开。
Groq LPU:SRAM的逆袭
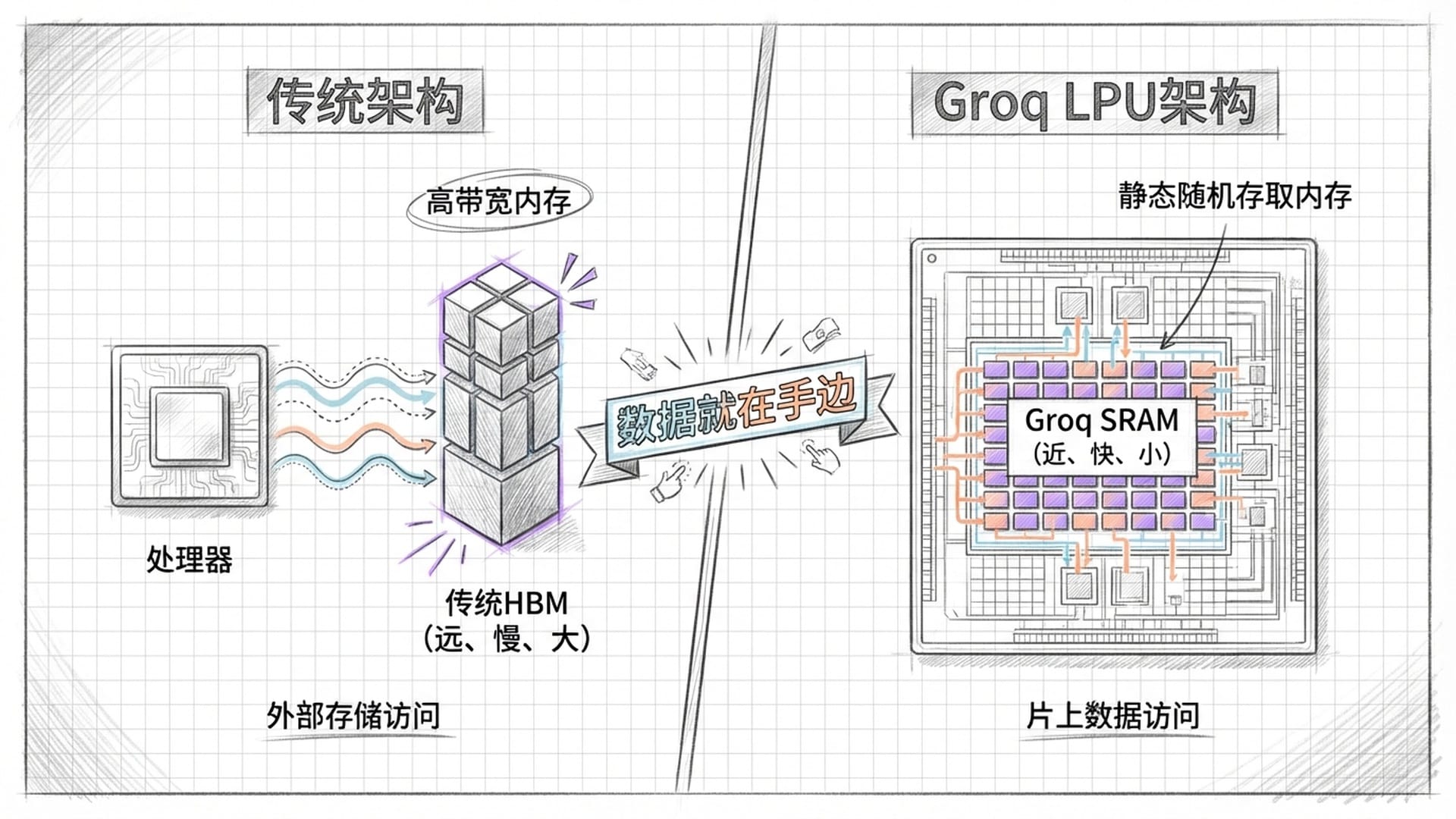
在“打破内存墙”的浪潮中,诞生了一家名为Groq的公司。他们另辟蹊径,推出了一种名为LPU(Language Processor Unit)的处理器。LPU的核心思想是:与其在外部HBM(高带宽内存)上硬碰硬,不如将大部分数据直接集成到芯片内部的SRAM(静态随机存取内存)中。
传统认知中:
- 外部HBM:容量大但速度慢。
- 内部SRAM:速度快但容量小且昂贵。
Groq的反直觉做法是将大量的SRAM搬到芯片上,这仿佛是把电脑硬盘的大部分内容,直接移到CPU旁边的缓存里,用时瞬取,速度骤升。
这种设计带来了显著优势:
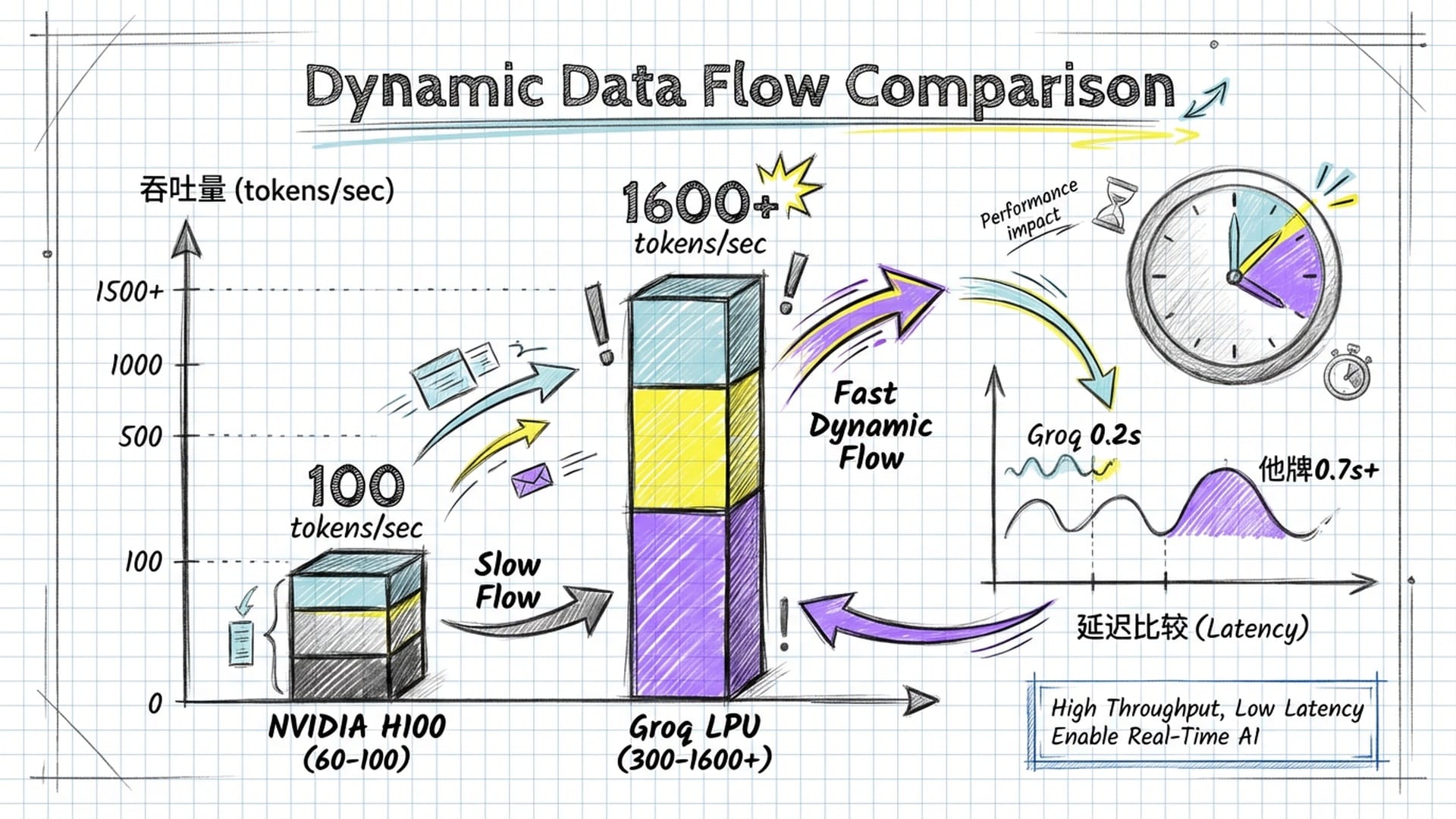
- 超高速度:例如,Llama 3这样拥有700亿参数的大模型,在Groq LPU上每秒能输出300个词(甚至通过“推测解码”可达1600+),而英伟达H100每秒仅能处理60-100个字。这种差距在实际应用中,意味着从**“卡顿中……”到“秒回”**的用户体验飞跃。
- 极低延迟:Groq首次响应时间可压缩至0.2秒,而HBM系统可能需要8到10毫秒。在人机交互中,毫秒级的差异也能带来截然不同的体验。
- 惊人能效:从外部HBM取每比特数据需消耗6皮焦耳能量,而从芯片内部SRAM取数据仅需0.3皮焦耳,节能高达20倍。在大模型运行成本日益高昂的今天,Groq LPU无疑是**“省钱神器”**。
然而,SRAM虽好,其高昂的成本和巨大的占位面积是其致命缺点。一个Groq芯片只能容纳230兆字节的SRAM,要运行超大模型就必须将数百个芯片互联。Groq通过其RealScale网络解决了这一挑战,使这些芯片能协同工作。
HBM:AI训练的主力军
那么,Groq的崛起是否意味着英伟达的衰落?答案是否定的。尽管SRAM在某些**“低延迟推理”**场景表现出色,但对于整个AI行业,特别是模型训练和大规模批处理推理,HBM仍是绝对主力。训练大模型需要海量数据,SRAM的容量根本无法满足。
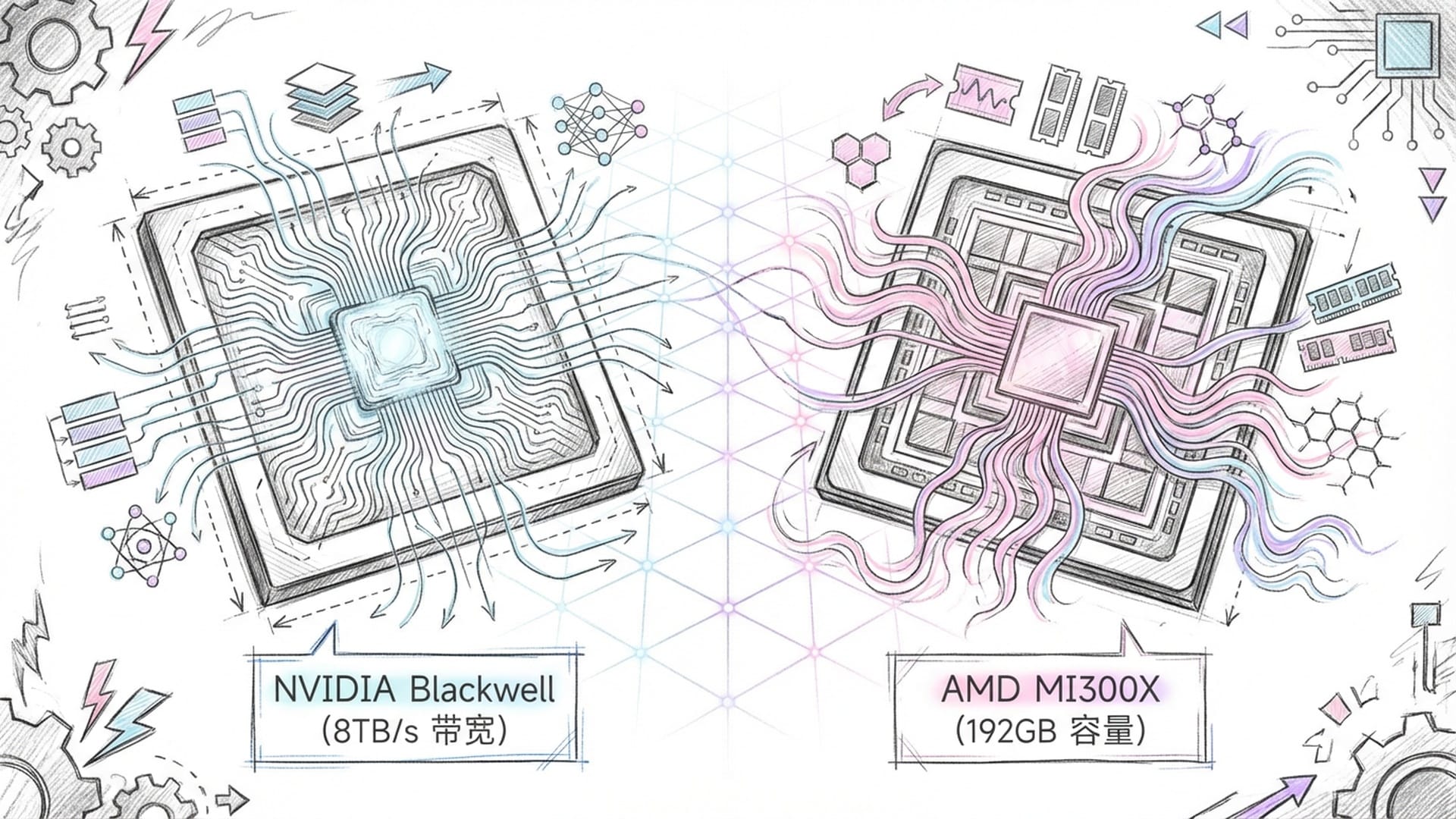
- 英伟达H100与Blackwell(B200):这些芯片是**“内存带宽狂魔”。H100提供每秒3.35太字节的带宽,Blackwell更是飙升至每秒8太字节。虽然它们在小批量推理时单字功耗较高,但胜在容量大、生态成熟**。英伟达的CUDA编程框架,犹如AI界的操作系统,地位难以撼动。
- AMD Instinct MI300X:AMD另辟蹊径,将HBM容量做到极致,单卡高达192吉字节。在运行某些超大模型时,MI300X表现出优势,在特定推理场景下比英伟达H100快2.1倍。这表明,AI硬件并非英伟达一家独大,AMD也正在迎头赶上。
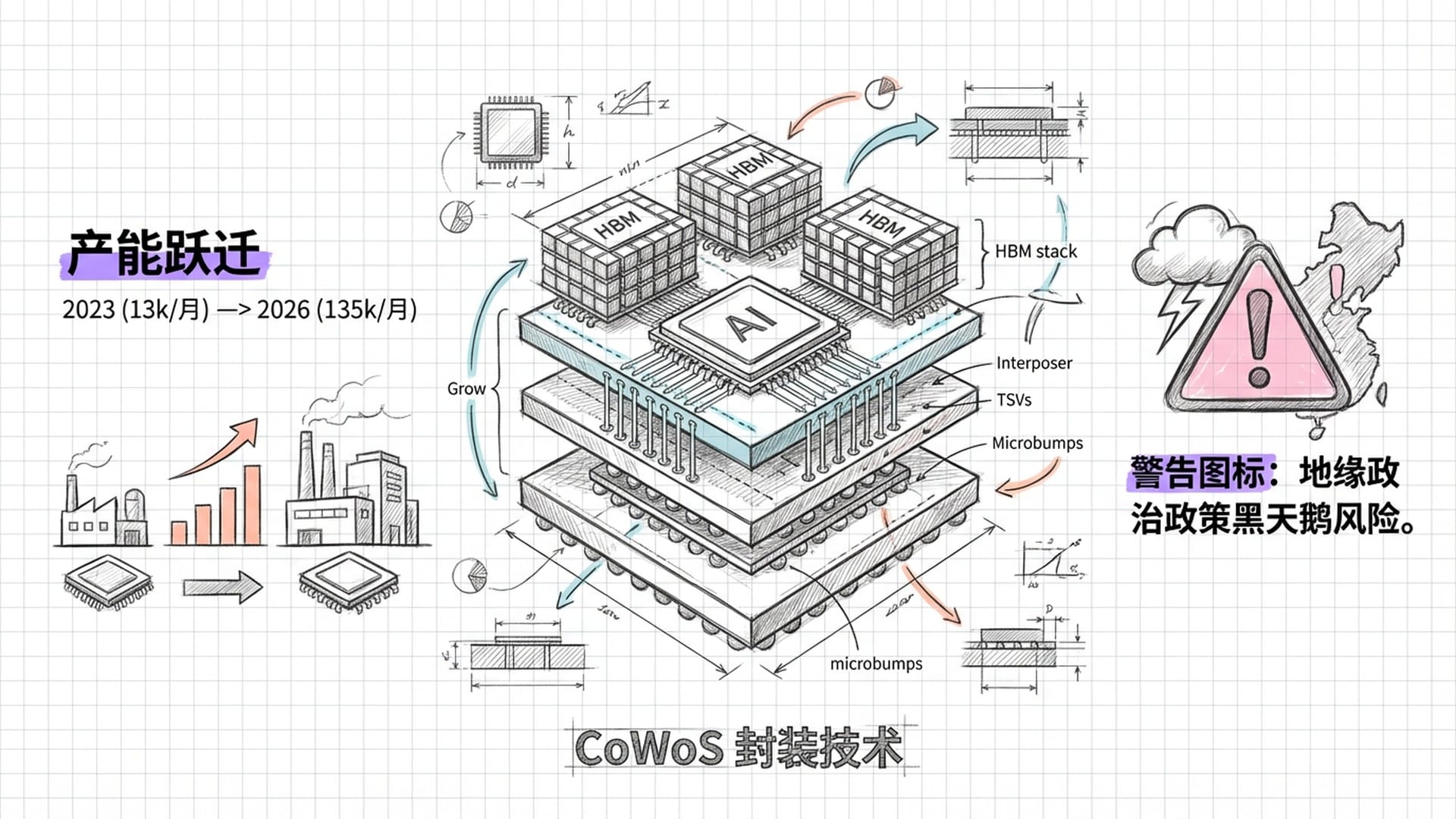
硬件供应链危机与CoWoS困境
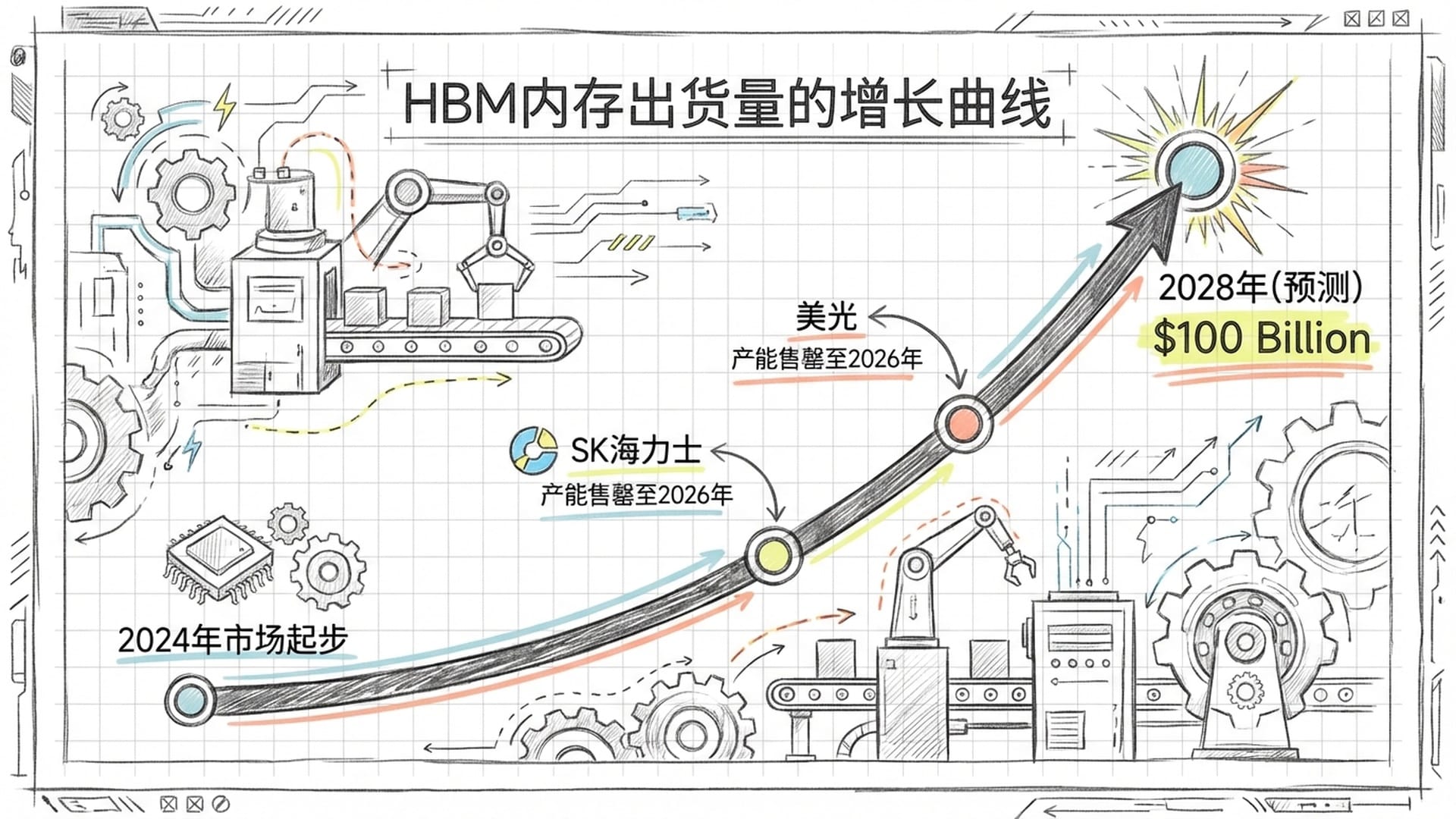
“内存墙”之战直接引爆了硬件供应链危机。HBM需求一路飙升,甚至脱离了传统DRAM市场。美光预测,到2028年,HBM市场规模将达到1000亿美元,这比2024年整个DRAM市场还要大!
- 产能售罄与疯狂扩产:SK海力士和美光两家巨头纷纷宣布,其到2026年的HBM产能已被预订一空。SK海力士甚至承诺到2026年将DRAM产能提高八倍以满足HBM需求。美光更是为了给高利润的AI数据中心产品让路,不惜停产消费级内存品牌Crucial。
- 技术快进:行业正加速研发HBM四代,目标在2026年初实现量产,未来的HBM甚至会将逻辑处理单元直接集成到内存堆栈中,进一步模糊计算与存储的界限。
然而,仅有HBM还不够。将HBM与AI芯片像三明治一样堆叠封装,需要CoWoS这种高级封装技术。CoWoS产能也成了新的瓶颈。
- 台积电的产能扩张:台积电作为CoWoS技术的主力,计划从2023年每月1.3万片晶圆的产能猛增至2026年的13.5万片。即便如此,产能仍供不应求,英伟达一家就预订了2026-2027年超过一半的CoWoS产能。
- 地缘政治影响:更严峻的是,地缘政治的“黑天鹅”可能随时降临。有消息称,因美国政府政策变动,台积电甚至可能暂停2026年的部分扩产计划,这无疑给本已紧张的供应链增加了不确定性。
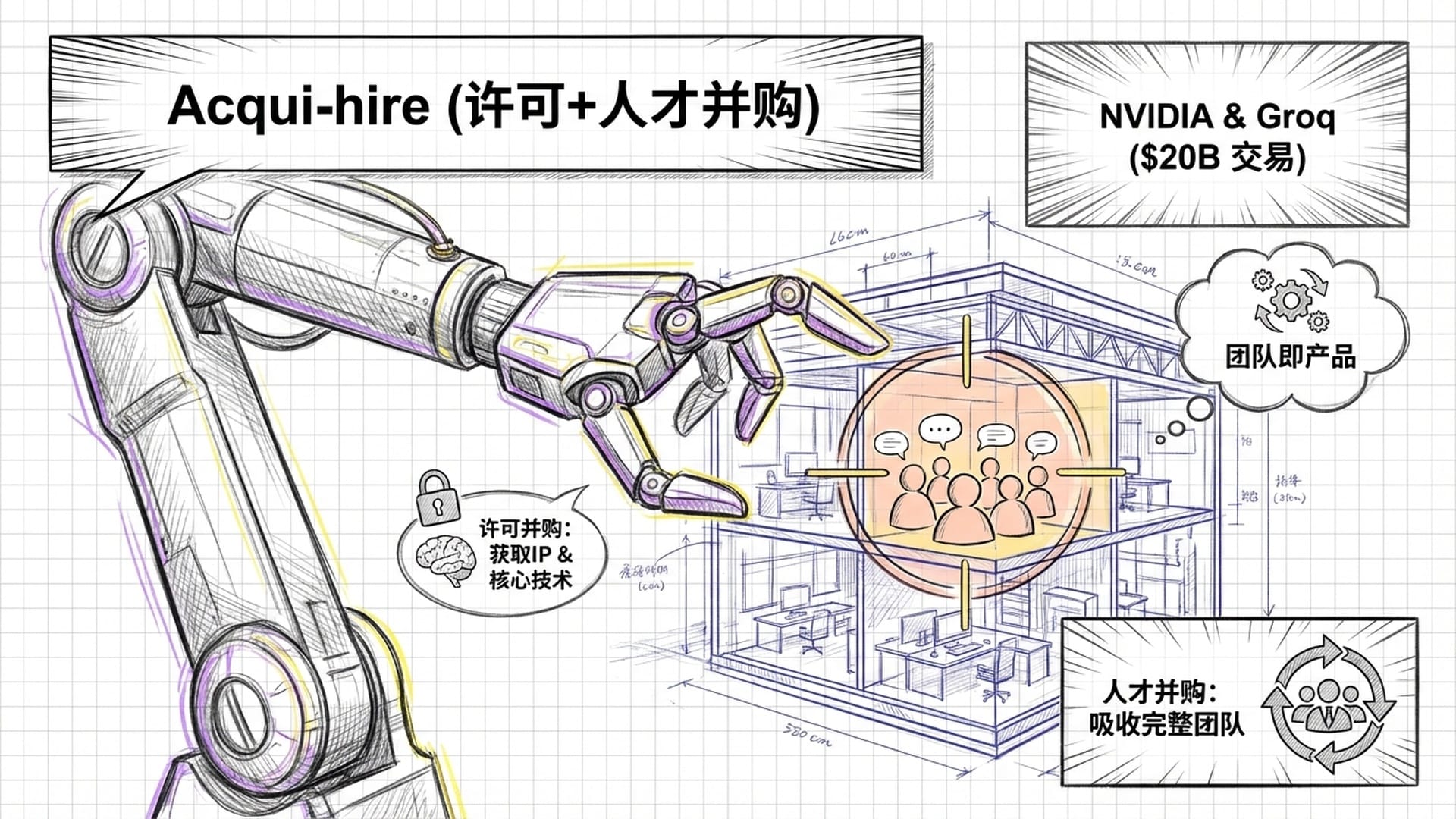
“许可加人才收购”:新时代的并购游戏
当传统并购受制于日益严格的反垄断政策时,科技巨头们发明了一种新玩法:“许可加人才收购”。这是一种巧妙规避并购审查的方式,即不直接收购公司,而是挖走核心团队和关键人才,再将技术授权过来。“表面上公司还活着,但实际上,骨肉已被吸走。”
最典型的案例莫过于英伟达与Groq的交易:
2025年12月24日,英伟达以200亿美元与Groq达成“资产收购和许可协议”。这笔交易中,英伟达不仅获得了Groq的技术许可,更是挖走了其约80%的员工,包括创始人Jonathan Ross。Groq名义上独立存在,但其核心芯片设计能力已归英伟达。
此举对英伟达而言,既是防御(应对潜在威胁),又是进攻(整合超低延迟技术)。
类似的“许可加人才收购”案例不胜枚举:
- 微软与Inflection AI:微软以6.5亿美元挖走Inflection AI创始人及大部分员工,被视为**“反向人才收购”**的模板。
- 亚马逊与Adept:亚马逊许可Adept的AI代理技术,并招募其联合创始人及核心研究人员。
- 谷歌与Character.ai:谷歌豪掷27亿美元许可Character.ai的模型,并召回了两位前员工(Character.ai创始人)领导AI工作。
这种模式改变了初创公司的退出路径,使得**“团队就是产品”成为新的发展逻辑。然而,这也带来了一些问题,例如,一些公司在人才被挖走后沦为“僵尸公司”,扭曲了风险投资的估值模式,价值不再由商业指标决定,而是由巨头间的“人才争夺战”**推动。
监管收紧:堵上“漏洞”
“许可加人才收购”的玩法终究难逃法眼。到了2025年,全球反垄断机构开始加强审查力度。
- “重实质而非形式”:监管机构认为,如果一项交易实质上转移了核心资产(人才和知识产权),使得公司失去竞争能力,这本质上就是一次合并,应依照合并监管。
- 联合声明与调查升级:欧盟、英国和美国竞争监管机构发表联合声明,承诺严格审查AI领域的合作。联邦贸易委员会已对亚马逊、谷歌、微软投资Anthropic和OpenAI等AI初创公司的行为展开调查,微软和Inflection的交易也正接受审查。
这场由“内存墙”引发的蝴蝶效应,最终波及到法律和监管层面,标志着AI行业的发展正趋于成熟。
2026年AI格局:巨头逐鹿与人才争夺
截至2025至2026年,AI赛道上的顶级玩家各有策略:
- 英伟达:依然是**“点石成金”**的王者,凭借CUDA生态和激进战略(如收购Groq)保持领先地位。
- 谷歌(TPU团队):成功实现转型,TPU v7 “Ironwood”开始对外商业化,与Anthropic达成数十亿美元合作,提供更低的总体拥有成本。
- 微软:重组后投入超过800亿美元于AI基础设施和定制芯片(Maia芯片),与OpenAI合作依然核心,同时发展内部模型以分散风险。
- xAI:埃隆·马斯克的AI公司,融资逾220亿美元,计划建设名为“巨像”的超级计算机,利用“马斯克生态圈”数据参与竞争,但其估值存在显著的**“马斯克溢价”和“关键人物风险”**。
值得注意的是,AI界顶级人才的频繁流动也成为一道风景线,例如Ilya Sutskever离开OpenAI创立新公司,以及Mira Murati的离职。这都说明,最顶尖的AI人才,仍是整个生态系统中最稀缺的资源。
到2026年,AI格局已因硬件物理限制和科技巨头眼花缭乱的战略操作而彻底重塑。“内存墙”推动了Groq SRAM架构的创新,但也诱发了以“许可协议”为掩护的兼并重组。尽管SRAM在低延迟任务中表现亮眼,但对于大规模训练,HBM芯片仍是AI经济的发动机。随着监管机构堵住非传统交易漏洞,AI行业正迈向一个全新的成熟阶段:不再止于概念,而是硬碰硬地拼执行力、基础设施和落地应用。
下一次,你再看到聊天机器人秒回信息,或游戏中AI角色栩栩如生,你或许会意识到,这背后是一场史诗级的“内存战争”,以及大佬们在牌桌上进行的无形博弈。