

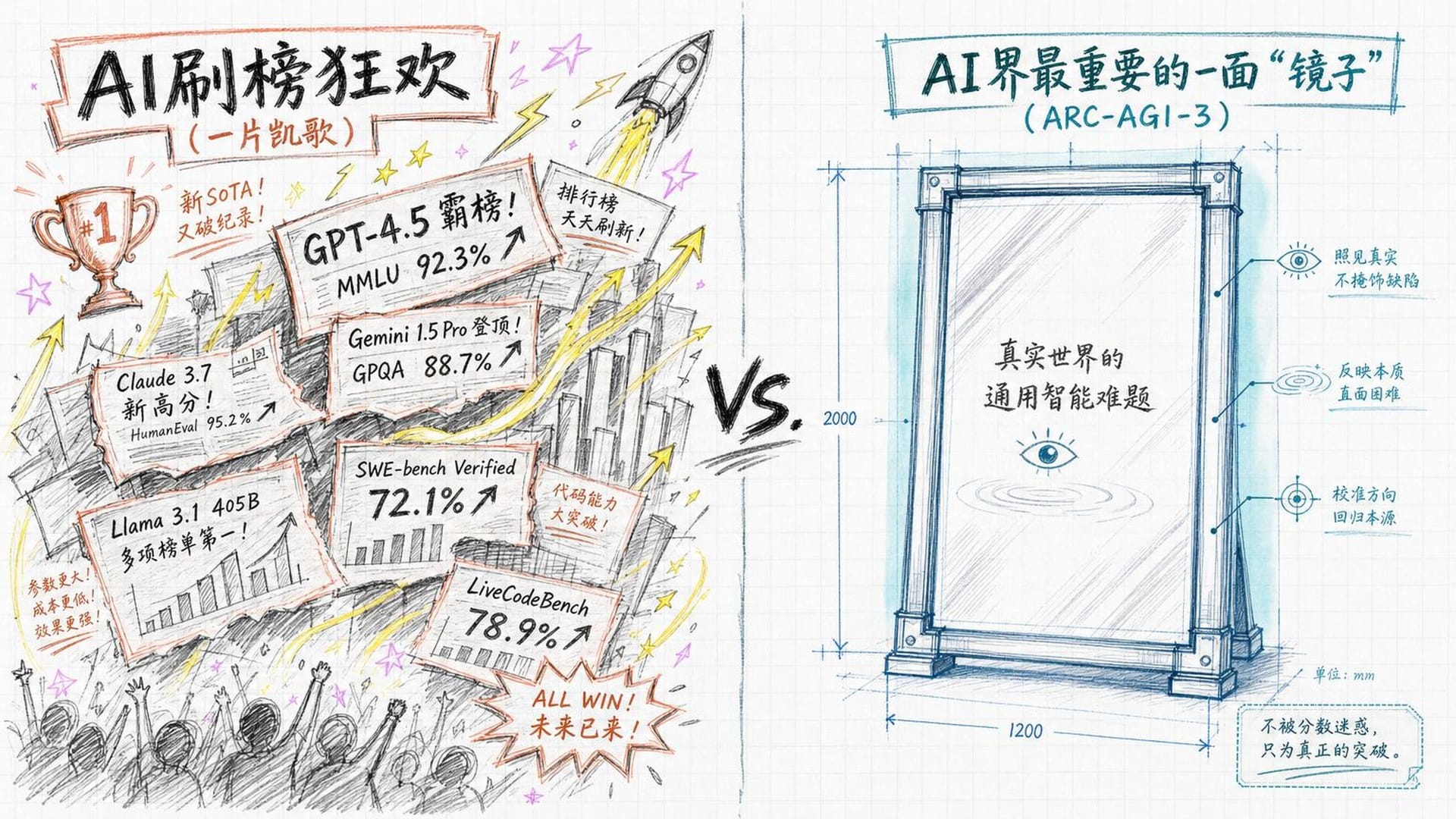
一个悄然上线、没有任何头条新闻的测试,却让硅谷核心圈的很多人在深夜辗转难眠。
这个测试叫 ARC-AGI-3,2026年3月25日发布。它的结论只有一句话,却重如千钧:当今世界上最强大的AI,面对全新环境的推理能力,只有人类的0.37%。
不是37%,是0.37%。
一片凯歌中突然出现的"镜子"
过去两年,AI刷榜的速度近乎疯狂。今天某个模型登上排行榜榜首,明天就被新模型挤下来。每隔几周,就有人宣布AI又在某个考试上"超越了人类"。在这种欢呼声中,突然冒出一个测试说AI只有人类的0.37%,听起来几乎像一个拙劣的笑话。
但它不是笑话。它可能是近几年来AI领域最重要的一次**"照镜子"**。
造AI工具的人,质疑AI的智能
这个测试的创造者叫弗朗索瓦·肖莱(François Chollet),一位法国裔AI研究者。他在谷歌工作了九年多,于2024年底离职创业。他不是一个坐在旁观席上批评AI的局外人——他是深度学习框架 Keras 的作者,这个框架被全世界成千上万的AI工程师用来搭建神经网络。
换句话说,他是造AI工具的人。
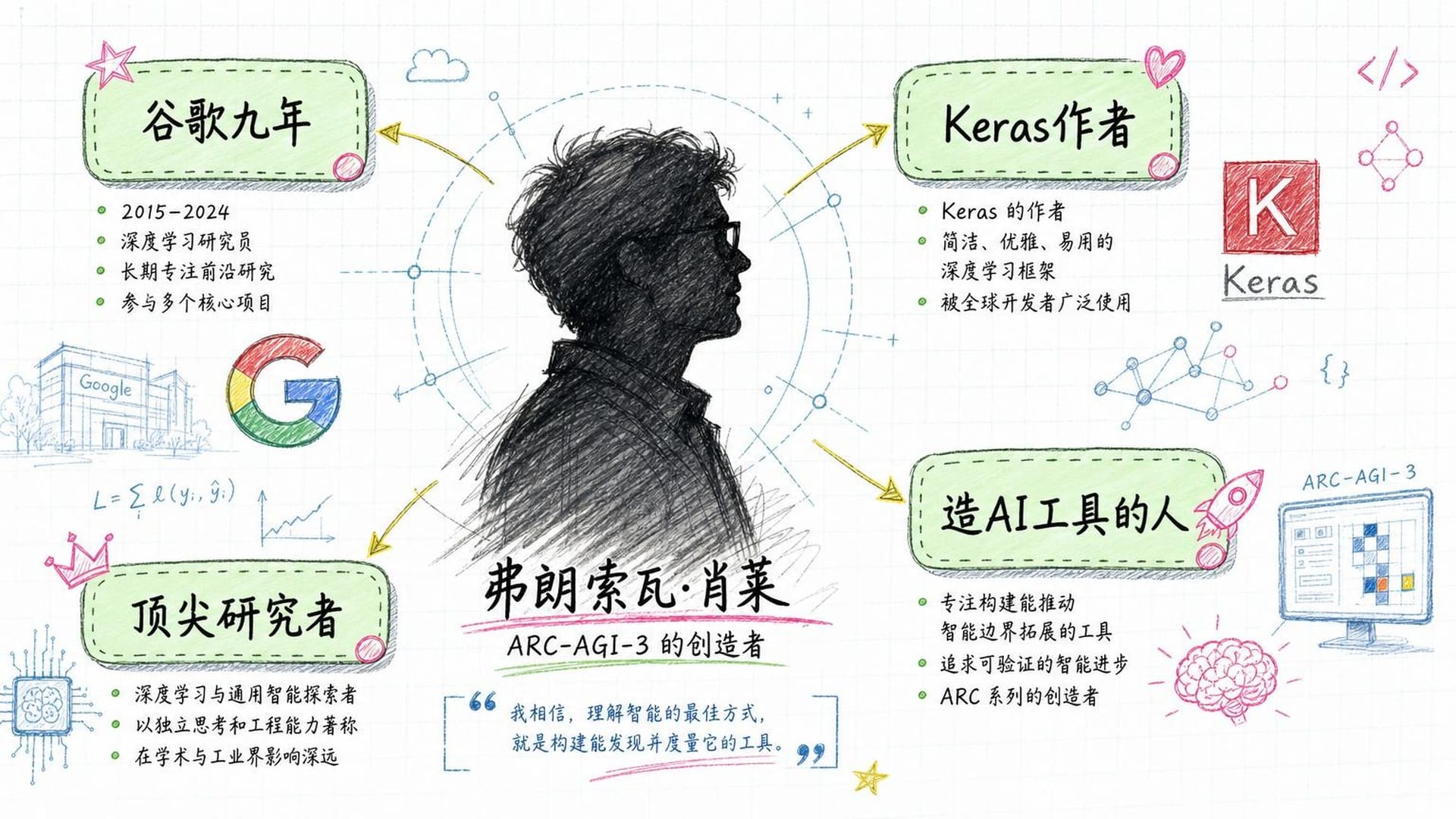
正是这样一个"圈内人",在2019年发表了一篇论文:《论智能的度量》。论文的核心观点可以用一句话概括:
我们一直在用错误的方式衡量AI的智能。
这句话究竟是什么意思?那些年我们看到的AI成绩单——什么考试得了多少分、什么排行榜排名第几——这些测试考的是什么?是AI能不能回答一个已知类型的问题。做数学题、写代码、回答常识问题。AI确实越来越强,有些甚至已经超过了人类。但肖莱说,这根本不是智能,这是背书。
晶体智能 vs. 流体智能:一个被忽视的根本区别
肖莱在论文中借用了心理学里的一个经典概念,做了一个至关重要的区分。
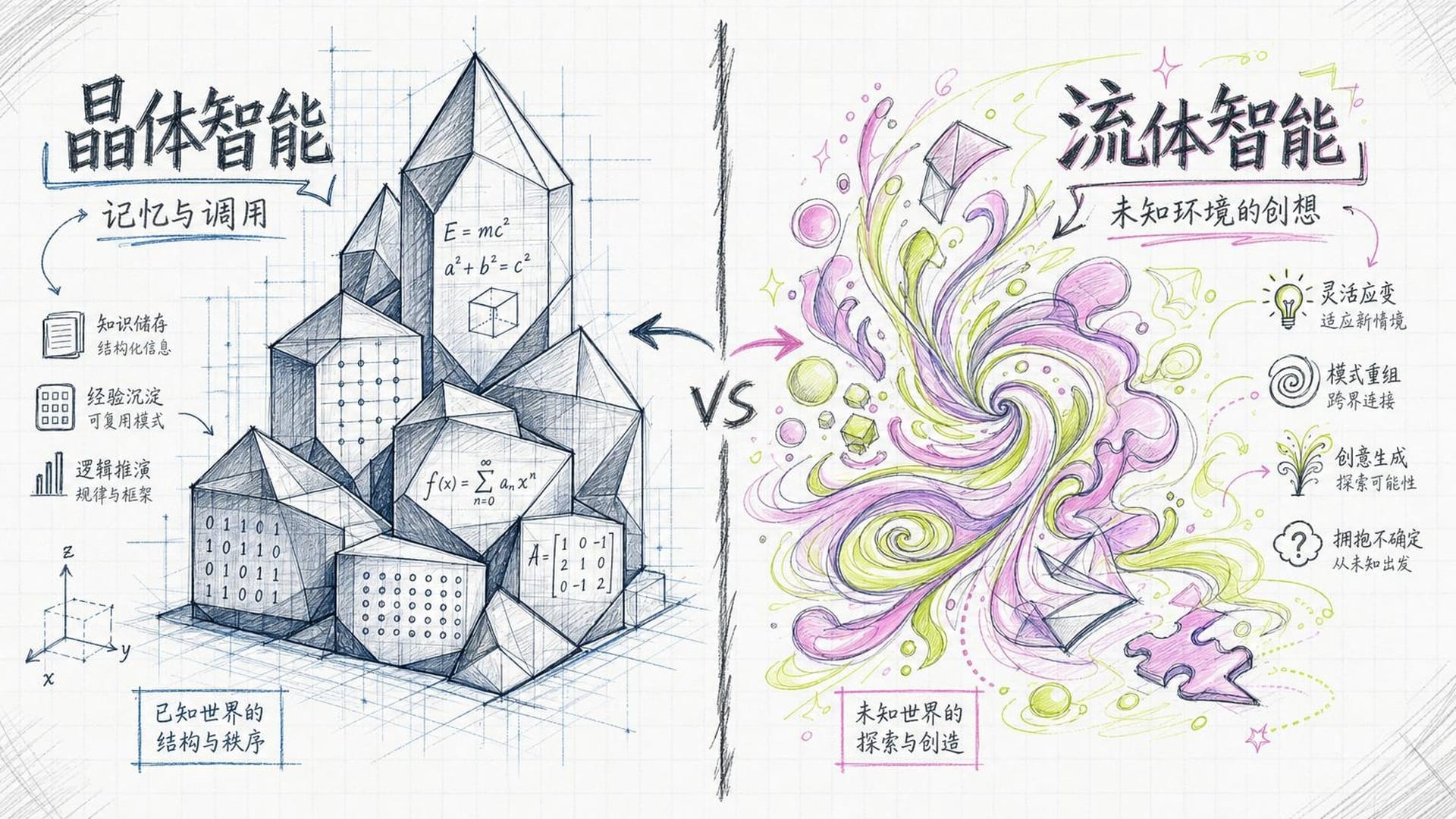
晶体智能是你积累的知识和技能——你会说英语,你记得勾股定理,你知道北京是中国首都。这些东西你学过、记住了、可以随时调用。
流体智能则完全不同。它是你面对一个从未见过的、完全陌生的新问题时,能不能当场想出解决办法的能力。
举一个最直观的例子:假设你被空投到一个完全陌生的城市——语言不通,手机没信号,地图也没有。你会怎么做?你可能先观察周围的地标,选一个方向走走看,走错了再根据新的线索调整方向。整个过程,你用到的不是任何预先储存的知识,而是一种即时感知、试探、反馈、调整的能力。这就是流体智能,每个正常人都拥有,而且效率极高。
肖莱的核心论点是:当今AI几乎全部的惊人表现,都来自晶体智能。它们拥有人类历史上所有公开文本作为训练数据,知识储备早已超越任何人类个体。但这不是智能,这是记忆力加模式匹配。
真正的智能,是面对一个前所未有的情境时,学习和适应的效率——不是你知道多少,而是你在不知道的时候,能多快地搞明白。
ARC-AGI测试:从图案题到互动世界
为了证明这一点,肖莱设计了ARC-AGI系列测试。
最初的 ARC-AGI-1 是一系列抽象的图案变换题:给你几组输入输出的图案示例,让你推断出背后的规则,然后把这个规则应用到一个新的输入上。题目本身并不难,普通人看一眼就能想明白。关键在于每道题的规则都是独一无二的,不可能提前背答案——它考的就是"现场悟"的能力。
一开始AI表现很差,成绩只有0%到30%左右。然后AI公司们开始集中火力攻克这道坎。到2024年底,OpenAI推出了推理模型 o3,开启最高算力模式——消耗的算力是正常版本的172倍——跑出了87.5%的成绩,超过了人类85%的平均水平。
硅谷欢呼雀跃,许多人宣称通用人工智能的曙光已经出现。
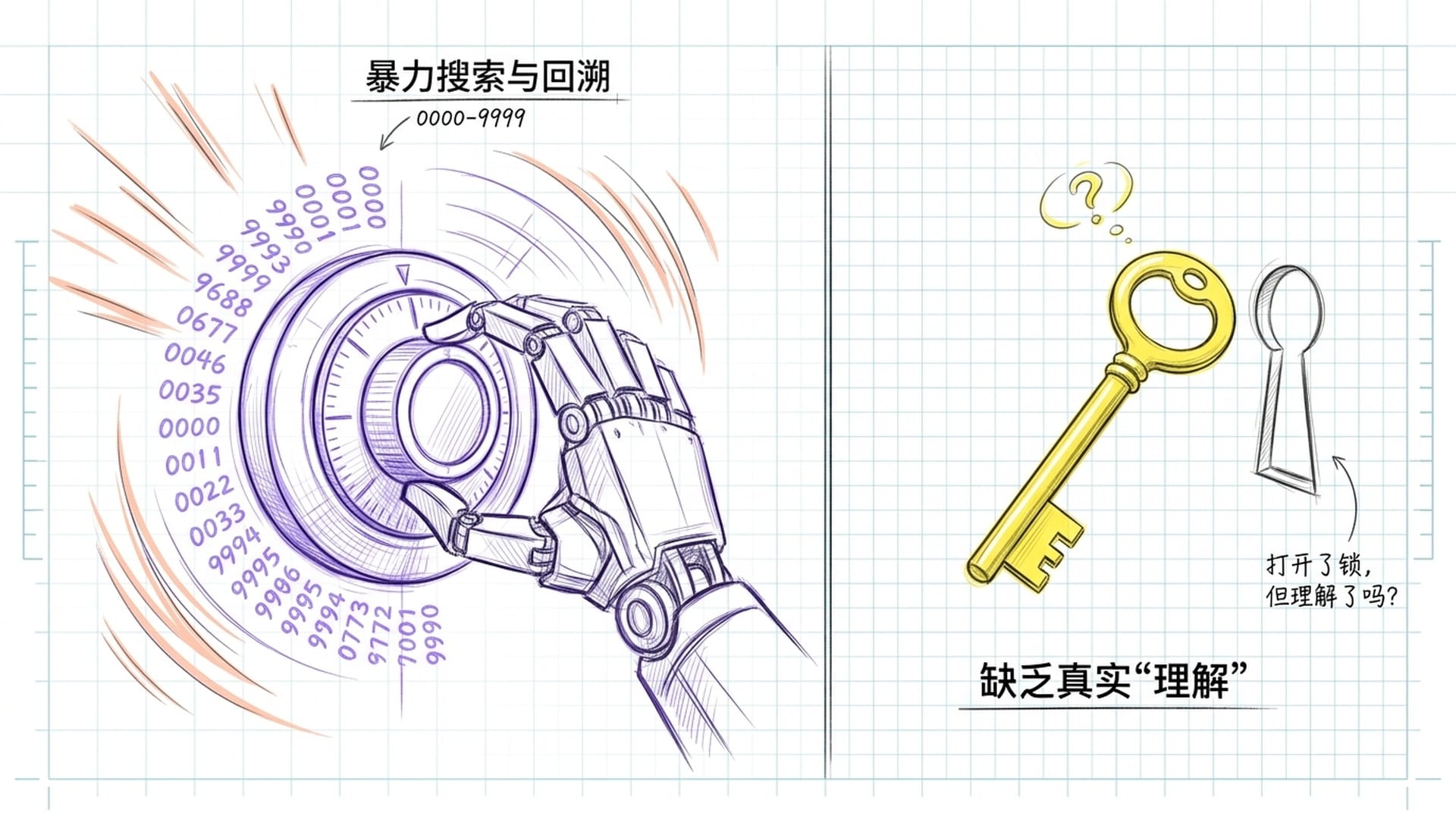
但很少有人注意到另一个数字:这次测试的计算成本是天文数字。最初估计每道题约3000美元,400道题总计超过100万美元;后来有人重新核算,认为真实成本可能高达每题3万美元,总计超过1000万美元。而一个普通人做同样的400道题,花费的能量大概相当于吃一顿午饭,人力成本每题约5美元。
你花了几百万甚至上千万美元,跟一个刚吃完午饭的人打了个平手——这叫突破吗?
更关键的是,当研究者深入分析o3的解题过程时发现,它并不是真正"理解"了规则。它是用暴力搜索的方式,在成千上万条可能的推理路径中反复试探、回溯、重选,直到碰巧找到一条走得通的路。这不是思考,这是穷举——就好比不是理解了密码锁的设计逻辑,而是从0000一路试到9999。你确实打开了锁,但你真的"理解"了这把锁吗?
ARC-AGI-3:彻底改变游戏规则
肖莱看到这个结果,不但没有气馁,反而加倍下注。他先推出了难度大幅提升的 ARC-AGI-2,AI成绩从93%骤降至68.8%。然后,今年3月,他放出了 ARC-AGI-3。
这一版彻底改变了游戏规则。

ARC-AGI-3 不再是静态的图案题。它是一系列互动式的环境——你可以把它想象成一个个微型电子游戏世界,由人类游戏设计师手工打造,共有几百个完全不同的场景。但这些游戏没有任何说明书,没有规则介绍,连目标是什么都不告诉你。
你被扔进一个陌生世界,需要自己去点击、去试错、去观察每一个动作带来的变化,然后自己搞清楚三件事:这个世界是怎么运转的?目标是什么?怎么才算赢?
更重要的是,测试不只看你能不能最终过关,还要看你花了多少步。它计算的是你的学习效率——你从环境中获取信息并转化为有效策略的速度。这正是肖莱在2019年那篇论文里给"智能"下的定义:在未知任务上的技能获取效率。
那个让人目瞪口呆的数字
人类在这个测试上的得分是100%。 每一个参与测试的人类都成功搞定了所有环境。
而全世界最强的AI呢?
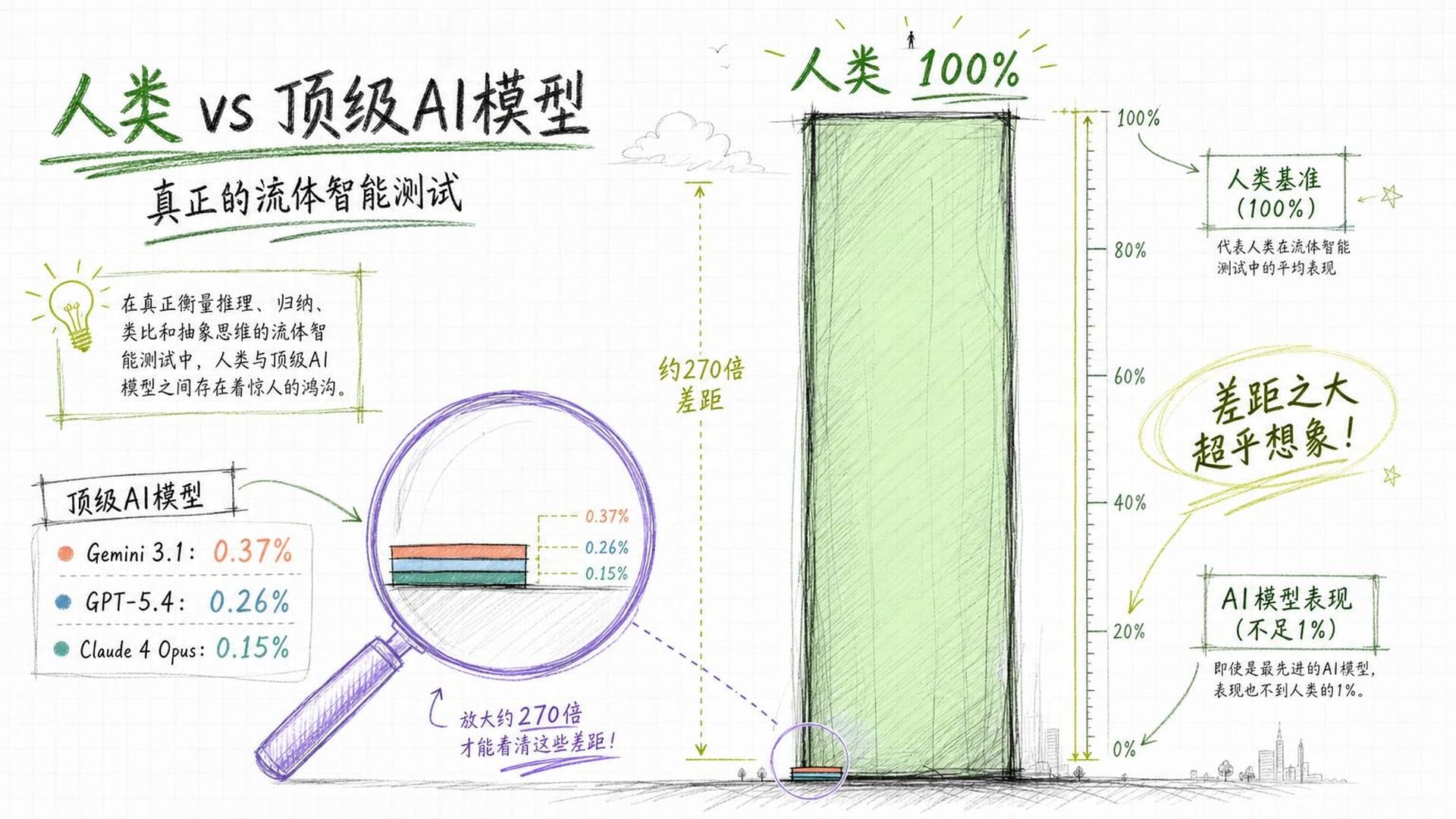
谷歌的 Gemini 3.1 得分0.37%。OpenAI的 GPT-5.4 得分0.26%。Anthropic的 Claude Opus 4.6 得分0.25%。最令人咋舌的是 Grok-4.20,直接零分。
不是AI比人差一点,不是差几十个百分点——是差了两到三个数量级。如果人类是站在山顶上,AI此刻连山脚下的入口都没找到。
有人可能会说,这不公平——这种互动式环境本来就是为人类设计的,AI又没有手,又没有眼睛。但实际上,这些环境完全在电脑屏幕上运行,就是网格上的方块和颜色。AI能看到画面,能执行动作,它拥有和人类完全相同的信息输入和操作接口。
它缺的不是感官,不是算力,不是数据。它缺的是理解。
一个更深的警示:语言不是智能的全部
测试中还有一个耐人寻味的细节:表现最好的系统,不是那些万亿参数的大语言模型,而是一个用强化学习加图搜索方法构建的相对简单的系统,它拿到了12.58%——比所有大语言模型高出整整一个数量级。
这说明了什么?大语言模型那一套思路——从海量文本中学习统计规律和语言模式——在面对真正的新问题时,根本不是正确的方法论。你把整个互联网的文字都喂给一个系统,它也不会因此学会在陌生环境中试错和适应。
想想 AlphaGo 的故事——AI可以在围棋上击败世界冠军。围棋变化极多,但规则是固定的、已知的,从第一天就告诉你了,AI可以在这个空间里做到极致优化。但 ARC-AGI-3 做的事情完全不同——它相当于把你扔进一个从没见过的棋盘游戏,不告诉你棋子怎么走,不告诉你什么算赢,让你自己玩几轮搞明白。人类觉得这事不难,玩几把就能摸出门道。AI呢?几乎完全瘫痪。
再想想日常生活里一个微不足道的场景:去朋友家做客,发现他家马桶的冲水装置前所未见——不是按钮,不是拉绳,是某种奇怪的旋转机关。你可能愣了三秒,摸了摸,转了一下,水就冲了。你从来没学过这个具体装置,但你就是**"会了"**。这种能力你觉得理所当然,但对今天最强大的AI来说,这才是真正的难题。它可以写诗、做数学证明、生成代码,却搞不定一个没见过的冲水按钮。
两把锤子砸向同一面墙
这个实验结果意味着什么?
如果你熟悉彭罗斯的意识理论,你会发现一条隐隐的连线。彭罗斯从数学出发,用哥德尔不完备定理论证了一个惊人的结论:人类的心智包含某种"不可计算"的成分——有些事情我们能做到,但原则上任何算法都做不到。那是一个纯理论层面的推演。
而 ARC-AGI-3 提供的是实验层面的证据。它不谈意识,不谈灵魂,不谈量子力学,就是朴素地问:面对全新的环境,你能不能从零开始学会应对?结果人类全员通过,AI全军覆没。
一个理论的锤子,一个实验的锤子,从两个完全不同的方向,砸向了同一面墙:人类智能里有某种东西,不是靠堆数据、堆参数、堆算力能复制的。

我们被AI在语言和逻辑上的流畅表现惊艳到了,以至于忘了一个事实:流畅不等于理解。一只鹦鹉可以完美模仿你说的每一句话,但它并不知道那些话是什么意思。大语言模型当然比鹦鹉复杂得多,但 ARC-AGI-3 在问的是同一类问题:当你剥掉所有预训练的知识、所有学过的模式,只留下"面对未知时现场搞明白"这一个维度,AI还剩下什么?
答案是:几乎什么都不剩。
那个"懂了",到底是什么?
一个三岁的孩子被放进一个他从未去过的房间,没人教他,没有说明书,几分钟内就能搞明白门把手怎么用、哪个按钮开灯、积木往哪里放。他不需要训练十万次,不需要搜索所有可能的动作组合。他看了一眼,就**"懂了"**。
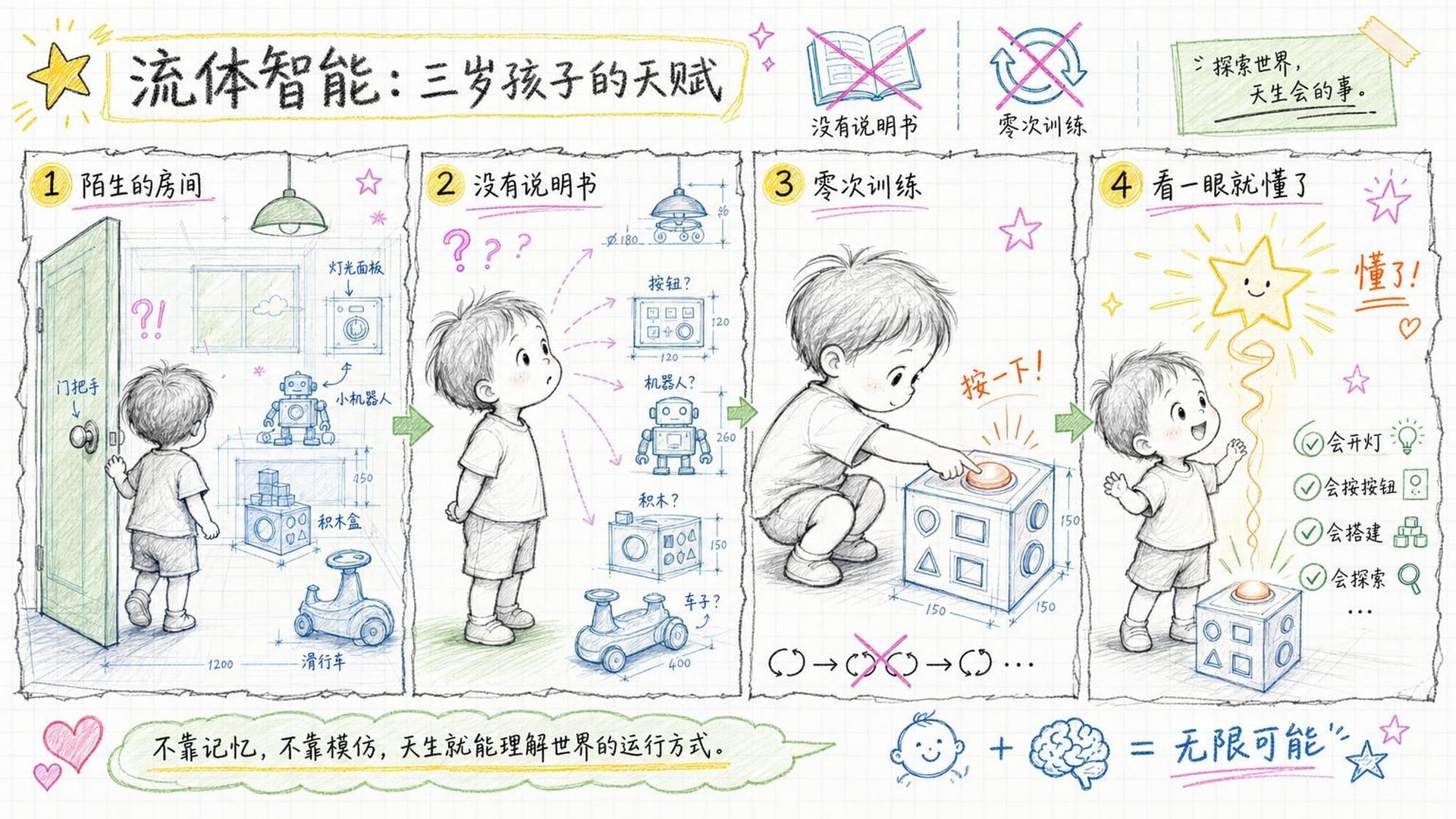
这个"懂了"到底是什么?
它不是计算——因为如果是计算,AI比人快一万亿倍,不应该比人差。它不是知识储备,因为一个三岁孩子的知识储备约等于零。它也不是进化赋予的本能反应,因为门把手和积木不是进化环境里的东西。它似乎是某种更基础的能力——一种把零散的感知信息**瞬间组织成"有意义的整体"**的能力,一种不需要被教就能看出"这个东西是干什么用的"的能力。认知科学家管这个叫 格式塔感知(Gestalt),但这个名字也只是给谜题贴了个标签,并没有解开谜题本身。
在面对真正的未知时,人类这台每秒只能处理大约10比特信息、仅消耗20瓦功率的"生物计算机",碾压了所有用百万美元电费堆出来的硅基系统。
也许,智能从来就不是信息处理。也许"理解"这件事,不是用更多的计算能力就能追上的。也许在人类看懂一个从未见过的东西的那个瞬间,发生的不是计算,而是某种今天的计算机架构根本无法模拟的东西。
这道鸿沟,意味着什么?
我要特别强调:这不是在说AI永远追不上。技术在进步,架构在创新,肖莱自己也设立了200万美元的竞赛奖金,等着谁能在 ARC-AGI-3 上达到人类水平。
但今天这道鸿沟,揭示的不是量的差距。它暴露的是一个质的差异:当前整个AI范式——从大语言模型到推理增强模型——在面对真正的、彻底的未知时,缺少一种根本性的能力。不是说AI只要继续训练、继续扩大参数就能赶上来。
ARC-AGI-3 没有回答"什么是理解"这个问题。但它用**0.37%**这个冰冷的数字,把这个问题狠狠地钉在了桌面上,让所有人都没办法再假装看不见。

你觉得AI最终能跨过这道鸿沟吗?还是说,这道鸿沟本身就在告诉我们——我们从一开始,就小看了**"理解"**这件事?